使用PhantomJS爬取股票資訊
阿新 • • 發佈:2018-12-02
寫在前面
前一段時間使用python+PhantomJS爬取了一些股票資訊,今天來總結一下之前寫的爬蟲。
整個爬蟲分為如下幾個部分,
- 爬取所有股票列表頁的資訊
- 爬取所有股票的詳細資訊
- 將爬取到的資料寫入cvs檔案中,每一種股票為一個CSV檔案
爬取所有股票列表頁的資訊
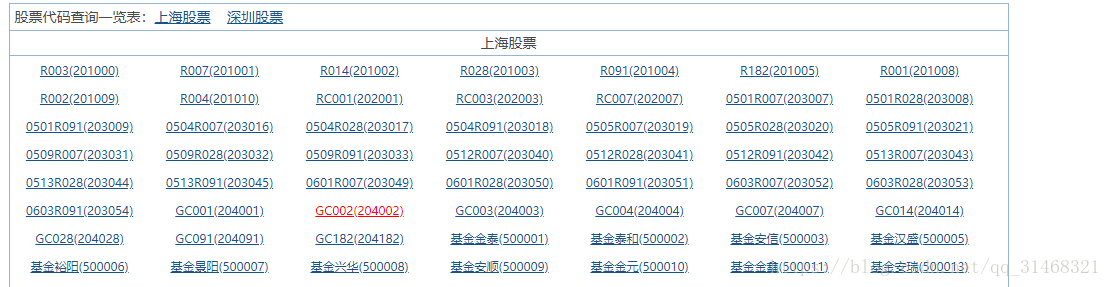
先來看一下網頁
如上,我們準備先獲取所有的股票名稱和股票程式碼,然後構造成新的URL來爬取詳細的資訊。
- 先檢視使用的包
from selenium import webdriver from lxml import etree import time import csv
- 開啟瀏覽器
#開啟瀏覽器
def open_web(url):
web_info = webdriver.PhantomJS()
web_info.get(url)
html = web_info.page_source
time.sleep(3)
return html
- 獲取所有股票程式碼和股票名稱
獲取到所有資訊,並將資訊寫入字典
def get_all_stockcode(html): info = {} data = etree.HTML(html) lis = data.xpath("//div[@class='quotebody']/div/ul/li") for li in lis: key,value = li.xpath(".//text()")[0].split("(") value = value.replace(")"," ".strip()) info[key] = value return info
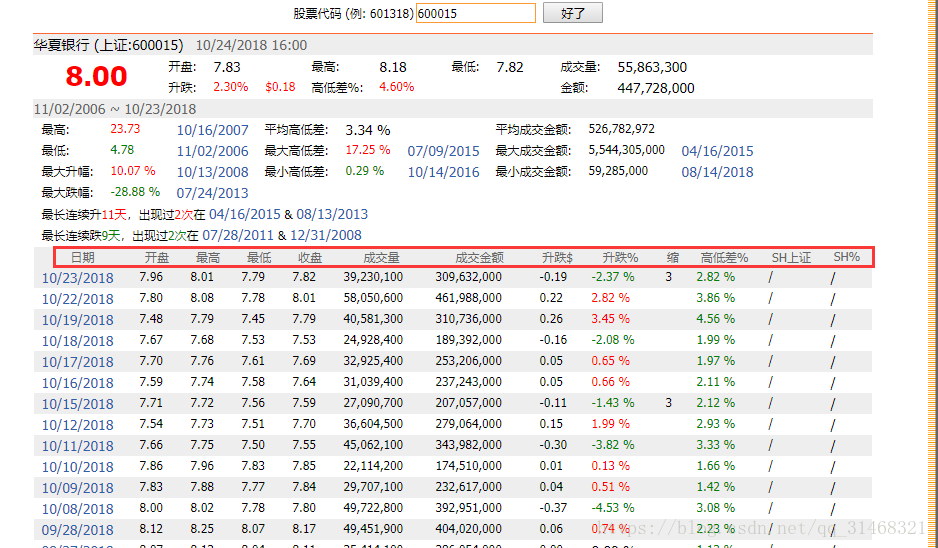
獲取了所有的股票名稱和股票程式碼之後,開始構造詳細資料網頁的URL,開始爬取詳細的資訊,如下為詳細資料頁面。
4. 獲取詳細頁面
#獲取股票資料並儲存
def get_stock_data(stock_num):
find_url = "http://www.aigaogao.com/tools/history.html?s="
#構造URL
socket_url = find_url+stock_num
one_stock_html = open_web(socket_url)
return one_stock_html
- 獲取詳細頁面的資訊
使用enumerate方法,該方法返回一個索引和一個內容資訊,使用該介面獲取表格中的資料。
def get_stock_infos(infos_html):
detaile_info = {}
title = []
deta_data = etree.HTML(infos_html)
infos_div = deta_data.xpath("//div[@id='ctl16_contentdiv']/table/tbody/tr")
for index,info in enumerate(infos_div):
one_info = {}
if index == 0:
title_list = info.xpath(".//td/text()")
for t in title_list:
title.append(t)
#print(index,title)
else:
print('*'*40)
tds_text = info.xpath(".//td/text()")
if "End" in tds_text[0]:
break
tds_a_text = info.xpath(".//td/a/text()")[0]
tds_span_text = info.xpath(".//td/span/text()")
time = tds_a_text
one_info[title[0]] =time
opening = tds_text[0]
one_info[title[1]] = opening
highest = tds_text[1]
one_info[title[2]] = highest
lowest = tds_text[2]
one_info[title[3]] = lowest
closing = tds_text[3]
one_info[title[4]] = closing
volume = tds_text[4]
one_info[title[5]] = volume
AMO = tds_text[5]
one_info[title[6]] = AMO
up_and_down = tds_text[6]
one_info[title[7]] = up_and_down
percent_up_and_down = tds_span_text[0].strip(" ")
one_info[title[8]] = percent_up_and_down
if len(tds_text) == 9:
drawn = tds_text[7]
SZ = tds_text[8]
else:
SZ = tds_text[-1]
drawn = 0
one_info[title[9]] = drawn
percent_P_V = tds_span_text[1].strip(" ")
one_info[title[10]] = percent_P_V
one_info[title[11]] = SZ
percent_SZ = tds_span_text[2].strip(" ")
one_info[title[12]] = percent_SZ
print(one_info)
detaile_info[index] = one_info
return detaile_info
- 寫入CVS檔案的介面
#開啟CSV檔案
def save_csv(name,detaile_info):
#開啟檔案
with open(name,'w+',newline="",encoding='GB2312') as fp:
if detaile_info:
#獲取資料中的詳細資訊
headers = list(detaile_info[1].keys())
#寫入頭部資訊
write = csv.DictWriter(fp,fieldnames=headers)
write.writeheader()
#寫入詳細資訊
for index,info_x in enumerate(detaile_info):
if index != 0:
write.writerow(detaile_info[index])
- 開始爬取
base_url = "http://quote.eastmoney.com/stocklist.html#sz"
html = open_web(base_url)
info = get_all_stockcode(html)
for socket_name,socket_code in info.items():
print(socket_name,socket_code)
html = get_stock_data(socket_code)
detaile_info = get_stock_infos(html)
if detaile_info:
if "*" in socket_name:
socket_name = socket_name.strip("*")
csv_name = "s"+socket_name+'.csv'
save_csv(csv_name,detaile_info)