
tensorflow實戰:端到端簡單粗暴識別驗證碼(反爬利器)
阿新 • • 發佈:2018-12-03
今天分享一下如何簡單粗暴的解決驗證碼的辦法
背景:
- 對於一個爬蟲開發者來說,反爬蟲無疑是一個又愛又恨的對手,兩者之間通過鍵盤的鬥爭更是一個沒有硝煙的戰場。
- 反爬蟲有很多措施,在這裡說說驗證碼這一塊
- 論爬蟲修養:大家都是混口飯吃,上有老下有小,碼農何苦為難碼農?爬資料的時候儘可能減少伺服器壓力,能爬列表頁,就不爬詳情頁,
正文:
-
資料集:百度上找的一個驗證碼資料集(因為懶得生成),也可以自己生成。
-
在訓練前可以先對圖片進行降噪,去掉干擾點,可以用opencv裡面的函式濾波器等。這樣識別會快點
-
在這裡我就沒有去做啦,不然怎麼叫粗暴呢(真正:懶, 沒時間)
-
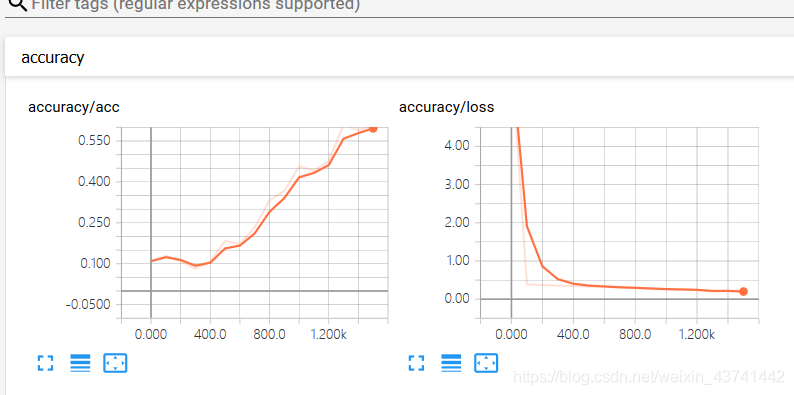
準確率訓練到90+我就儲存模型停止了,大家可以根據需求設定。看下圖
-

-
這裡是訓練中的loss以及accuracy
-
-
這裡是測試
-


-
這個是識別有錯誤的,畢竟我的GTX950也辛苦算了這麼久,再說這個7這麼像1呀。莫得了。
-


話不多說來個網路結構圖再說
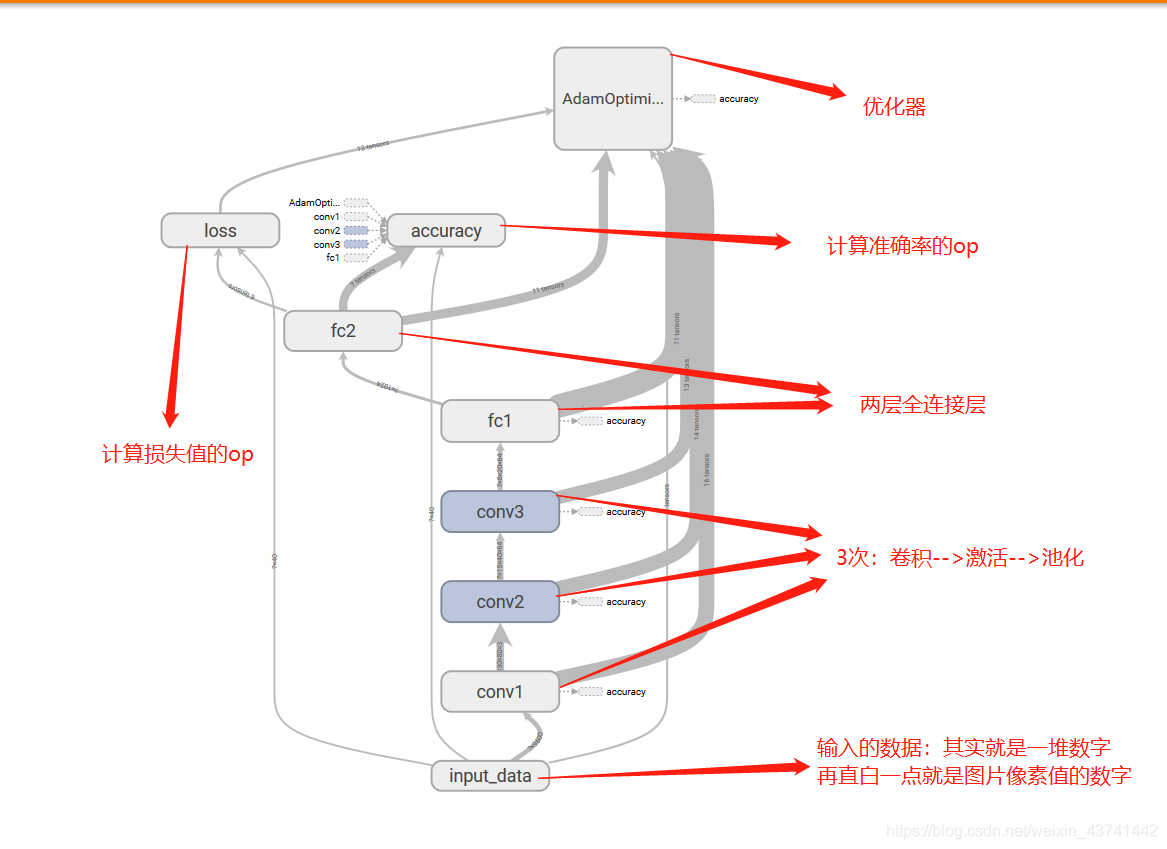
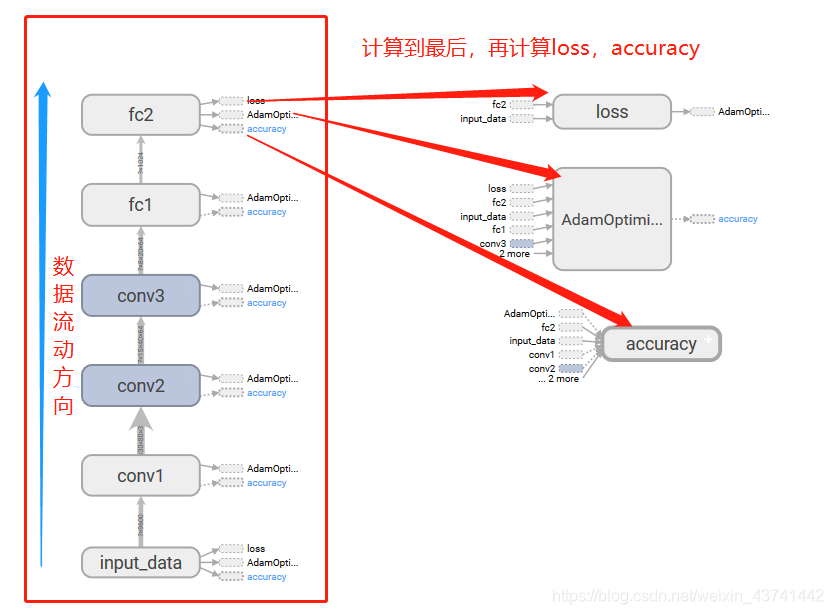
覺得有點亂的,看看下面的圖
劃重點:show you code
import numpy as np
import tensorflow as tf
from PIL import Image
import os
import random
import 在這裡看不懂的有2個辦法:
- 1:收藏退出一氣呵成,舒服又有成就感。
- 2: 看看我之前寫的CNN打造手寫數字識別,還有多百度百度。最重要的是機器學習基礎!!!沒有一步登天的事。
這裡是定義一些初始化引數的函式
# 定義初始化引數的函式
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
3個卷積層, 2個全連線層,看不懂的可以看下我寫的這個部落格
- (雖然寫得也不是很詳細,畢竟最近時間不太夠,以後會回來填坑的)
- https://blog.csdn.net/weixin_43741442/article/details/84558145
with tf.name_scope("input_data"):
x = tf.placeholder(tf.float32, [None, width * height], name='input')
y_ = tf.placeholder(tf.float32, [None, num_numbers * max_captcha])
with tf.name_scope("conv1"):
# 運算前,先轉換圖片畫素資料的維度
x_image = tf.reshape(x, [-1, height, width, 1])
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
with tf.name_scope("conv2"):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
with tf.name_scope("conv3"):
W_conv3 = weight_variable([5, 5, 64, 64])
b_conv3 = bias_variable([64])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
h_pool3 = max_pool_2x2(h_conv3)
with tf.name_scope("fc1"):
W_fc1 = weight_variable([8 * 20 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool3_flat = tf.reshape(h_pool3, [-1, 8 * 20 * 64])
# 全連線層加了啟用函式
h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, W_fc1) + b_fc1)
with tf.name_scope("fc2"):
W_fc2 = weight_variable([1024, num_numbers * max_captcha])
b_fc2 = bias_variable([num_numbers * max_captcha])
output = tf.matmul(h_fc1, W_fc2) + b_fc2
損失函式,以及優化器
with tf.name_scope("loss"):
cross_entropy = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_, logits=output))
with tf.name_scope("AdamOptimizer"):
# 1e-4也就是: 0.0001
train_step = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cross_entropy)
with tf.name_scope("accuracy"):
predict = tf.reshape(output, [-1, max_captcha, num_numbers])
labels = tf.reshape(y_, [-1, max_captcha, num_numbers])
correct_prediction = tf.equal(tf.argmax(predict, 2, name='predict_max_idx'), tf.argmax(labels, 2))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
最後就是訓練了
with tf.Session() as sess:
# sess = tf.InteractiveSession()
sess.run(init_op)
# 儲存事件檔案
train_writer = tf.summary.FileWriter("F:/checkimages/event/", graph=sess.graph)
saver = tf.train.Saver() # 用於儲存模型
for i in range(8000):
batch_x, batch_y = get_next_batch()
if i % 100 == 0:
train_accuracy = sess.run(accuracy, feed_dict={x: batch_x, y_: batch_y})
print("第%d步 --- >準確率為: %g " % (i, sess.run(accuracy, feed_dict={x: batch_x, y_: batch_y})))
# 儲存訓練過程的資料變化
summary = sess.run(merged, feed_dict={x: batch_x, y_: batch_y})
train_writer.add_summary(summary, i)
if train_accuracy > 0.90:
saver.save(sess, "F:/checkimages/model/output.model", global_step=i)
break
# 訓練模型
sess.run(train_step, feed_dict={x: batch_x, y_: batch_y})
小結:
- 這次分享主要目的事分享一下實現的程式碼,但不是說看了文章就可以識別驗證碼了。想要自己解決這些問題沒有其他的辦法。從頭開始學,歡迎學習交流一下。
- 這次使用的就是單任務訓練模式。以後還會分享多工模式以及使用Alexnet來實現。有興趣的可以關注一下,以防迷路。