
在Hanlp詞典和jieba詞典中手動新增未登入詞
在使用Hanlp詞典或者jieba詞典進行分詞的時候,會出現分詞不準的情況,原因是內建詞典中並沒有收錄當前這個詞,也就是我們所說的未登入詞,只要把這個詞加入到內建詞典中就可以解決類似問題,如何操作呢,下面我們來看一下:
一,在Hanlp詞典中新增未登入詞
1.找到hanlp內建詞典目錄
位於D:\hnlp\hanlp_code\hanlp\data\dictionary\custom
也就是Hanlp安裝包中的data\dictionary\custom下目錄
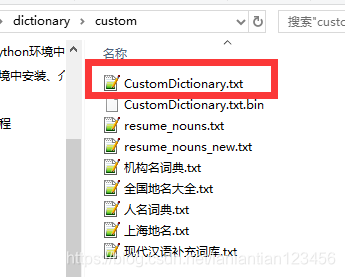
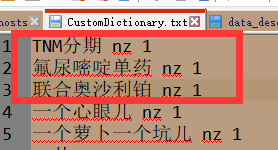
2.將未登入詞以詞名,詞性,詞頻的格式新增到檔案中(句首或者句尾都可以)
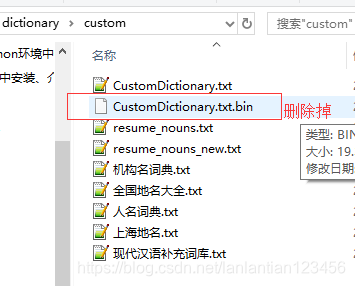
3.將字典的同名bin檔案刪除掉
執行檔案時讀取的是bin檔案,必須刪掉後等下次執行時重新生成,新字典才發揮作用
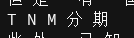
4.使用新字典重新執行檔案
執行時會遇到沒有相關bin檔案的提示,不過放心,程式會自動生成一個新的bin檔案,騷等片刻,就好了。

驗證結果是否正確
二,在jieba詞典中新增未登入詞
先來看看沒新增登入詞的效果

好我們需要開始新增未登入詞了
1.新建一個dict.txt檔案,將未登入詞直接新增到txt檔案中
2.載入dict.txt檔案
這個過程有一步要動態調整詞頻,因為詞典預設是從詞頻較高的詞開始匹配,調整未登入詞的詞頻靠前,這樣可以優先匹配
#-- coding=utf8 --
import jieba
import re
#將新增有未登入詞的詞典載入進來
jieba.load_userdict(“D:\hnlp\hanlp_code\dict.txt”)
#動態調整詞頻,讓未登入詞的詞頻自動靠前,這樣可以優先匹配
[jieba.suggest_freq(line.strip(), tune=True) for line in open(“dict.txt”,‘r’,encoding=‘utf8’)]
string=“TNM分期不太能明確地區分 ,以及輔助治療(氟尿嘧啶單藥或聯合奧沙利鉑)”
words=jieba.cut(string,HMM=False)
print(’/’.join(words))
3.驗證分詞是否有效

哦,好的,就是這樣!完美!
文章來源於小魚兒的部落格