
CS224n筆記17 NLP存在的問題與未來的架構
hankcs.com 2017-07-13 上午11.32.57.png課程介紹了各種各樣的深度學習網路與應用,是時候從更高層次思考自然語言處理存在的問題與展望未來了。雖然BiLSTM與attention幾乎統治了NLP,但在篇章級別的理解與推斷上還不盡人意。
新時代人們正在“解決”語言
深度學習填平了領域鴻溝,許多計算機視覺的泰斗級學者也開始研究起自然語言處理的各種任務。

這裡提到的自然語言理解、機器翻譯都是較高層次、更難的任務,現有系統做得並不那麼好。
舊時代的熱血
早期NLP學者擁有崇高的目標,希望讓機器像人一樣理解語言;但奈何資料和計算力都有限,使得成效甚微。Manning說今天我們有了海量的資料與強大的計算力,卻往往自滿於跑個LSTM,而不願意挑戰這個終極目標。
AI的師祖Norvig (1986)的Ph.D.論文The unified theory of inference中舉了個例子,希望機器從一篇文章中理解如下資訊:

其中a和b即便是最前沿的技術也無法自動推斷,因為在文字沒有提到海與島的關係,也沒提到漁網,省略了太多背景知識。
所以Norvig認為,必須先建立一個包羅永珍的知識庫,才能進行自然語言理解。但最近二十年,沒有知識庫我們也完成了許多NLP任務,並且模型學到的“知識”是連續的表示,而不是“知識庫”中的離散表示。
Norvig假想的系統中含有如下4種推斷(inference):
Elaboration:連線兩個實體,表示解釋說明
Reference Resolution:就是指代相消
View Application:比喻、活用、習語
Concretization:具體化,一般化,比如TRAVELLING is an AUTOMOBILE is an instance of DRIVING
基礎NLP:在進步
Norvig寫博士論文的時候,連像樣的句法分析器都沒有,所有句子都是手工分析的。現在我們有了全自動的句法分析器:

但現代NLP依然沒有完成Norvig設想的巨集偉目標——自動推斷:

也許是時候開始挑戰這個巨集偉目標了。
我們還需要什麼
現在BiLSTMs with attention已經統治了NLP領域,你可以在任何任務上應用它,得到超越其他方法的好成績(就如同若干年前的CRF和SVM一樣)。
另外神經網路方法也帶來了自然語言生成領域的文藝復興(MT、QA、自動摘要……)
這些現代突破都沒有采用Norvig假想的“知識庫”。究竟是否需要一個顯式的、localist(應該指的是領域相關的)語言與知識表示和推斷機制,這是一個亟待探討的科學問題。
雖然神經網路隱含了知識表達,我們也已經取得了如此多的成就,但我們建立和訪問記憶或知識的手段依然十分原始。LSTM只是短時記憶,並不能與人類經年累月的經驗與記憶相比。LSTM只是線性地掃描最近100個單詞而已。
另外,現有模型也無法制定和執行目標或計劃。這對對話系統而言非常重要,對話應當是有意義有目標的,而不是閒扯。
雖然句子級別的分析已經可以做到很清楚,句子之間的關係(順承、原因、轉折)則無法理順。
而且現在無論多深的網路,依然缺少理解語言解釋說明的常識或背景知識(雖然模型可能不夠複雜,我覺得資料量不夠也是很大原因,人類從小到大接受了多少文化教育,你能提供給神經網路的標註語料能有多少個句子)。
接下來介紹一些前沿的嘗試“盜火”的研究。
Recursive Neural Networks用於意識形態檢測
作為語言學者,Manning還是很喜歡樹形模型(贊成)。他的學生嘗試用Recursive Neural Networks檢測人們在政治上是保守的還是自由激進的等等。
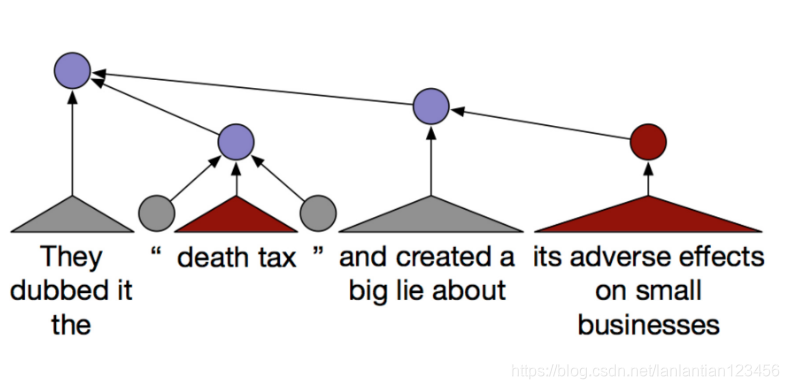
這並不是句子級別或段落級別的分析,而是文章級別的分析。一些政治術語被複合起來檢測最終的政治傾向(用不同顏色表示)。紅色表示保守的:
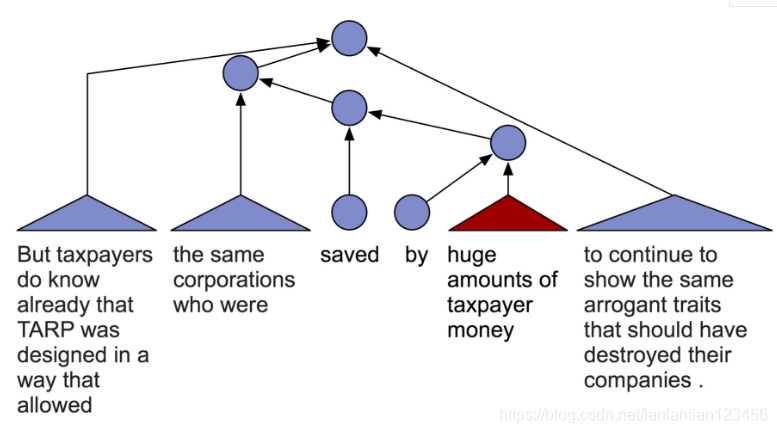
TreeRNN
樹形模型理論上很有吸引力,但非常慢,需要外部句法分析器(如果用內部的則更慢),而且也沒有用到語言的線性結構。
recurrent NN訓練快
線性結構的模型適合batch訓練,因為對每個訓練例項,模型結構都是一樣的。
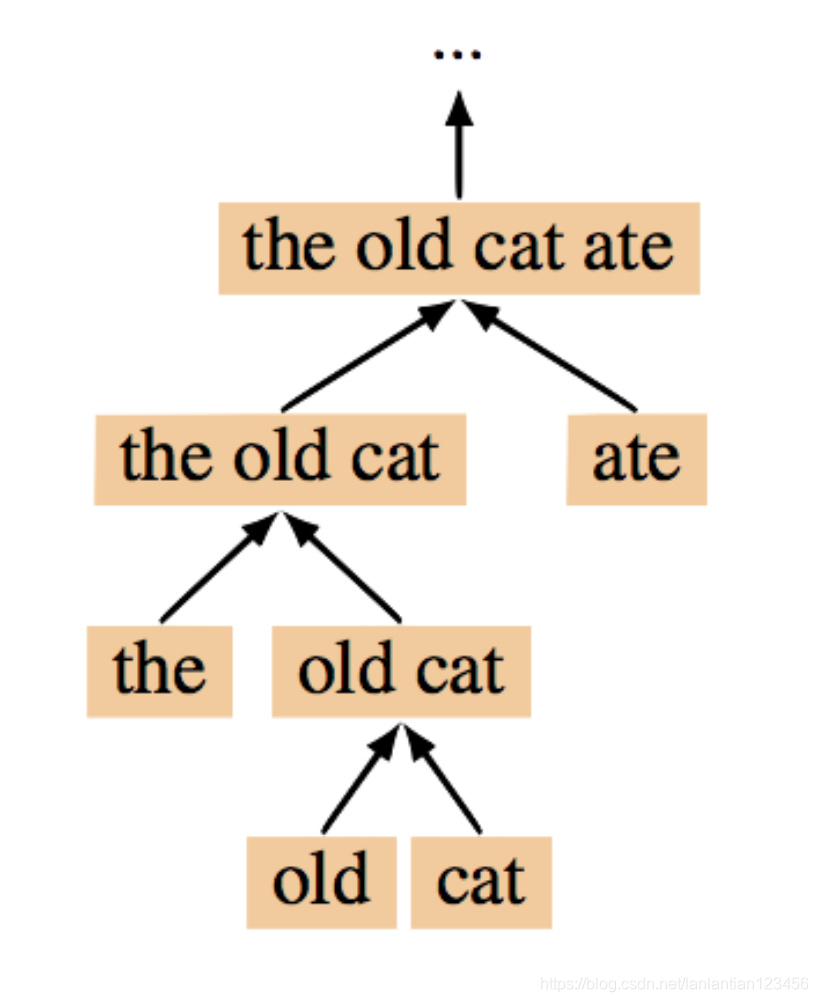
TreeRNN結構取決於輸入
所以無法並行化,一個執行緒在訓練某種結構的模型,其他執行緒得等它。
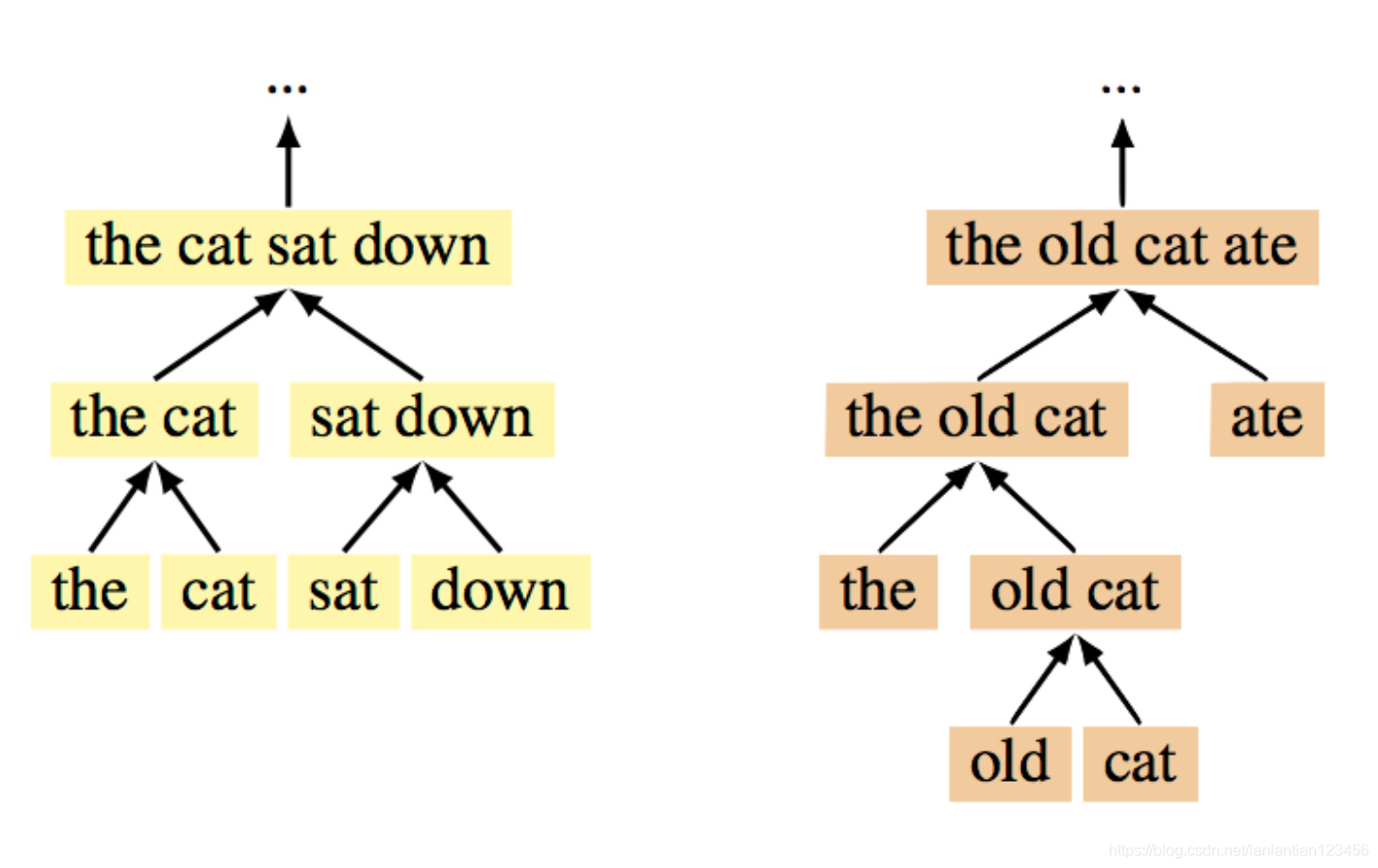
The Shift-reduce Parser-Interpreter NN (SPINN)
為了提高tree模型的訓練效率,人們活用Shift-reduce依存句法分析的思想,將模型的樹形機構拆分為動作序列,得到了25倍的速度提升。這還產生了“線性”與“樹形”模型的混血,可以離開外部句法分析器獨立執行。
binary trees = transition sequences
具體拆分方法如下:
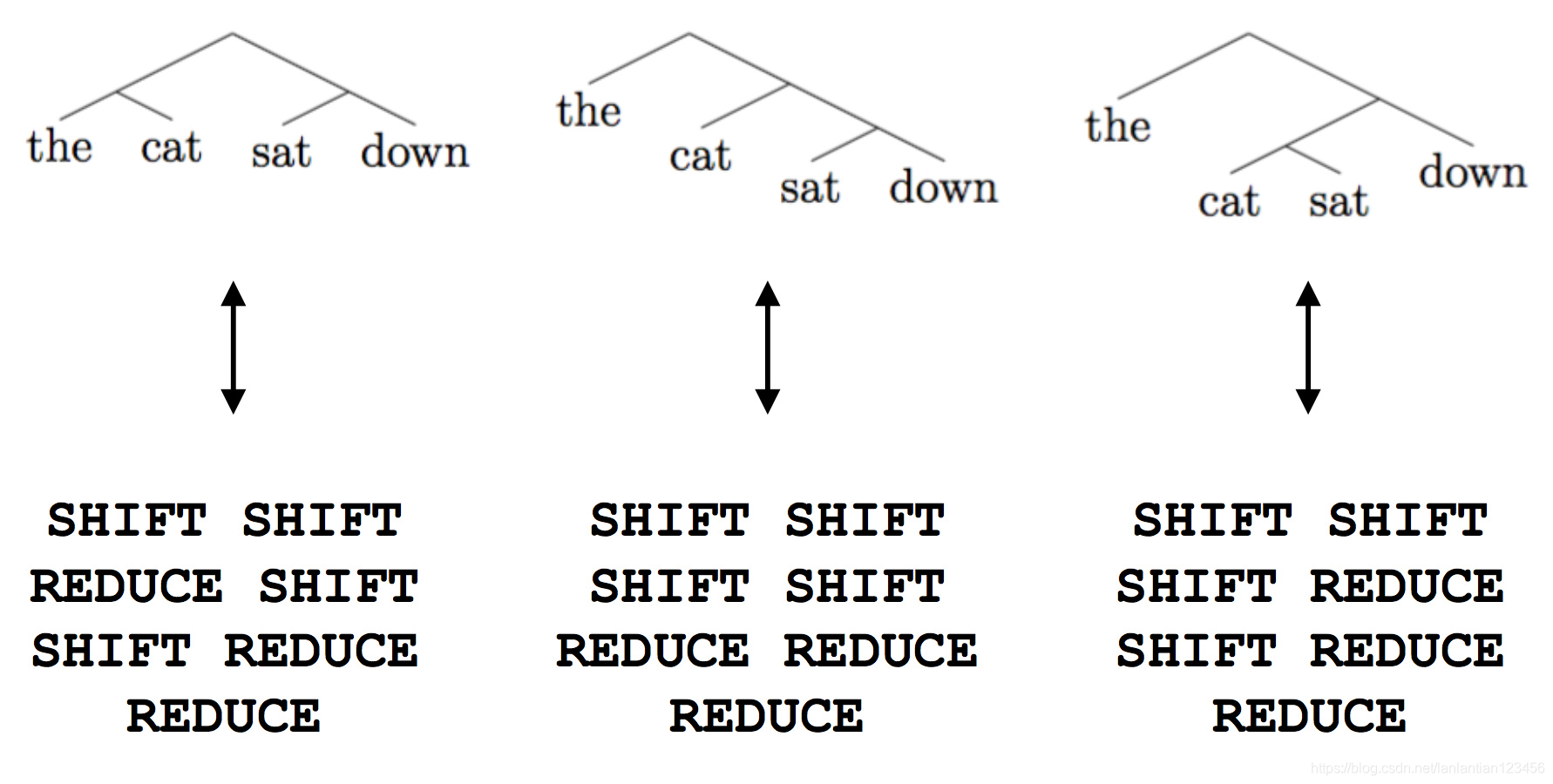
shift入棧,reduce合併。
架構
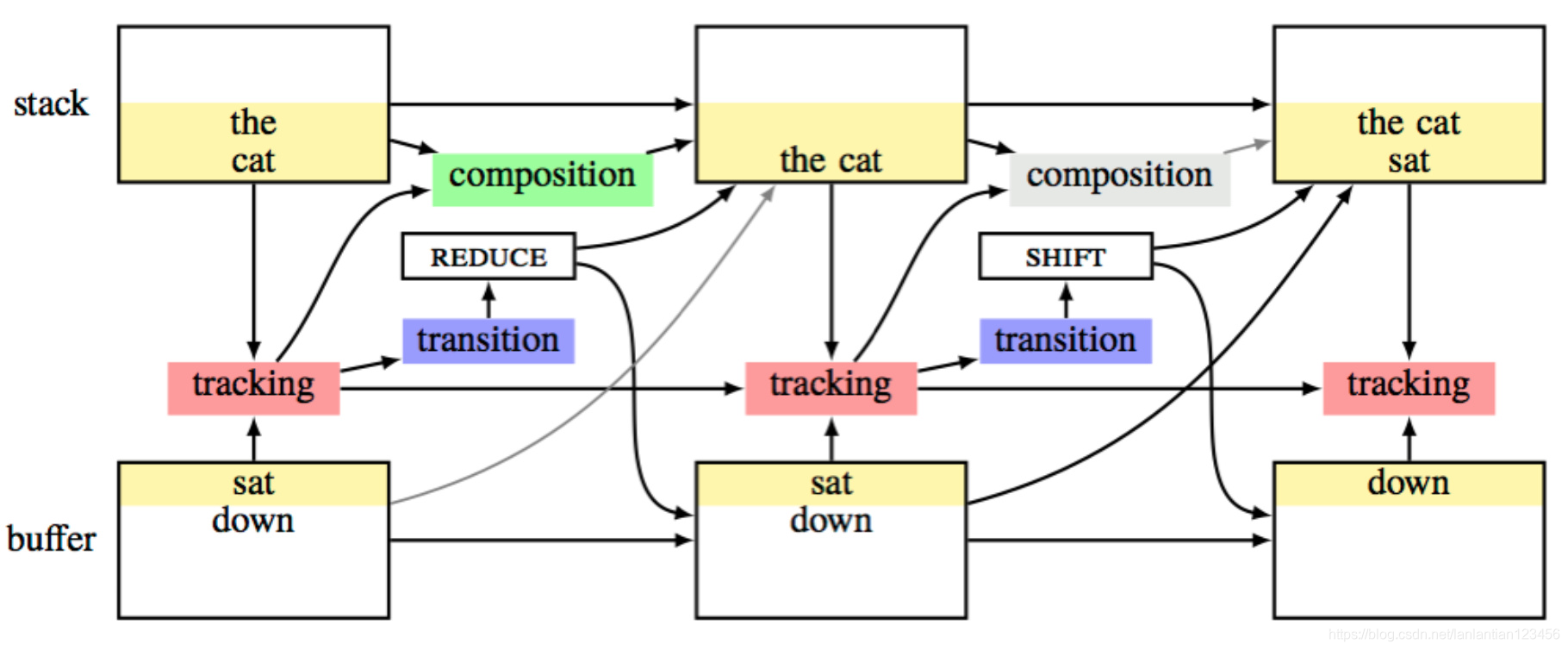
模型與parser類似,有stack和buffer儲存單詞,tracking由LSTM負責track並決策動作,TreeRNN負責拼裝成分的表達。LSTM還將上文的表示送給TreeRNN拼裝,這似乎解決了樹形模型無法捕捉語言的線性結構的問題。
文章來源於網路