
Apache Hive 筆記
1. Hive 簡介
1.1. 什麼是 HiveHive
是基於 Hadoop 的一個數據倉庫工具,可以將結構化的資料檔案對映為一張資料庫表,並提供類 SQL 查詢功能。
本質是將 SQL 轉換為 MapReduce 程式。 可以將hive理解為hadoop的一個客戶端,因為是hive去連線hdfs,是hive去提交MapReduce程式到hadoop中的ResourceManager主節點。
主要用途:用來做離線資料分析,比直接用 MapReduce 開發效率更高。
1.2. 為什麼使用 Hive直接使用 Hadoop MapReduce 處理資料所面臨的問題:
人員學習成本太高
MapReduce 實現複雜查詢邏輯開發難度太大
使用 Hive :
操作介面採用類 SQL 語法,提供快速開發的能力
避免了去寫 MapReduce,減少開發人員的學習成本
功能擴充套件很方便
2. Hive 架構
2.1. Hive 架構圖
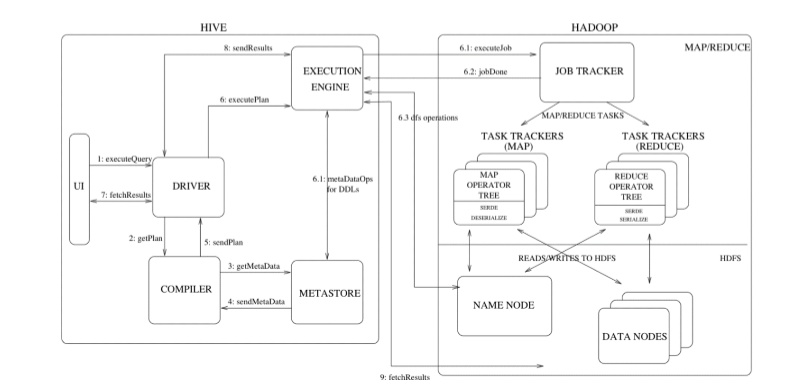
2.2. Hive 元件
使用者介面:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)為 shell 命令列;JDBC/ODBC 是 Hive 的 JAVA 實現,與傳統資料庫
元資料儲存:通常是儲存在關係資料庫如 mysql/derby 中。Hive 將元資料儲存在資料庫中。Hive 中的元資料包括表的名字,表的列和分割槽及其屬性,表的屬性(是否為外部表等),表的資料所在目錄等。
直譯器、編譯器、優化器、執行器:完成 HQL 查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃儲存在 HDFS 中,並在隨MapReduce 呼叫執行。
2.3. Hive 與 Hadoop 的關係
Hive 利用 HDFS 儲存資料,利用 MapReduce 查詢分析資料。
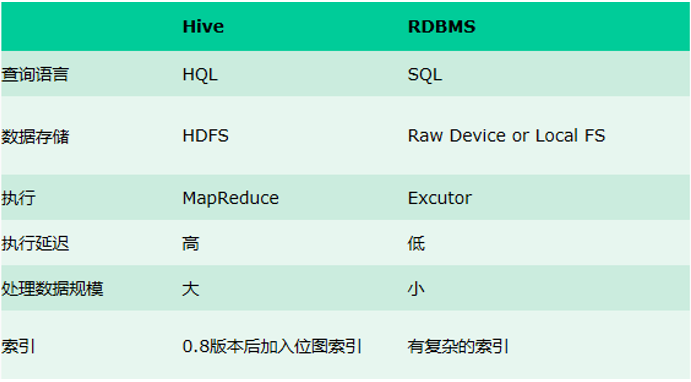
3. Hive 與傳統資料庫對比
hive 用於海量資料的離線資料分析。
hive 具有 sql 資料庫的外表,但應用場景完全不同,hive 只適合用來做批
量資料統計分析。
更直觀的對比請看下面這幅圖:
4. Hive 資料模型
Hive 中所有的資料都儲存在 HDFS 中,沒有專門的資料儲存格式
在建立表時指定資料中的分隔符,Hive 就可以對映成功,解析資料。
Hive 中包含以下資料模型:
db:在 hdfs 中表現為 hive.metastore.warehouse.dir 目錄下一個資料夾
table:在 hdfs 中表現所屬 db 目錄下一個資料夾
external table:資料存放位置可以在 HDFS 任意指定路徑
partition:在 hdfs 中表現為 table 目錄下的子目錄
bucket:在 hdfs 中表現為同一個表目錄下根據 hash 雜湊之後的多個檔案
5. Hive 安裝部署
安裝環境 :首先 安裝hive要有jdk(1.7以上 我所安裝的為1.8版本64位)
其次要有hadoop叢集,hive需要MapReduce和HDFS(hadoop部署可見其他文件)
mysql :雖然hive內嵌了一個關係型資料庫derby。但是內建的derby容量小,有些許可權受限,不便於管理。所以使用mysql,用來做表的對映等.(mysql安裝可見其他文件)
上傳檔案Apache Hive jar包 並解壓(可以去官網下載hive安裝包Index of /apache/hive)
首先要保證mysql可以正常使用 提供mysql下載方法
線上安裝
mysql yum install mysql mysql-server mysql-devel
配置
1 vi conf/hive-env.sh
hadoop環境變數 在配置檔案中找到hadoop_home,linux中安裝hadoop的位置
hadoop_home export HADOOP_HOME=/export/server/hadoop-2.7.4(hadoop所在位置)
配置元資料庫資訊
1 vi hive-site.xml
新增如下內容:
1 <configuration> 2 <property> 3 <name>javax.jdo.option.ConnectionURL</name> 4 <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> 5 <description>JDBC connect string for a JDBC metastore</description> 6 </property> 7 8 <property> 9 <name>javax.jdo.option.ConnectionDriverName</name> 10 <value>com.mysql.jdbc.Driver</value> 11 <description>Driver class name for a JDBC metastore</description> 12 </property> 13 14 <property> 15 <name>javax.jdo.option.ConnectionUserName</name> 16 <value>root</value> 17 <description>username to use against metastore database</description> 18 </property> 19 20 <property> 21 <name>javax.jdo.option.ConnectionPassword</name> 22 <value>root</value> 23 <description>password to use against metastore database</description> 24 </property> 25 </configuration>
安裝完成之後 在hive資料夾下啟動 bin/hive

Hive幾種使用方式:
1.Hive互動shell bin/hive
2.Hive JDBC服務(參考java jdbc連線mysql)
3.hive啟動為一個伺服器,來對外提供服務
bin/hiveserver2
nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
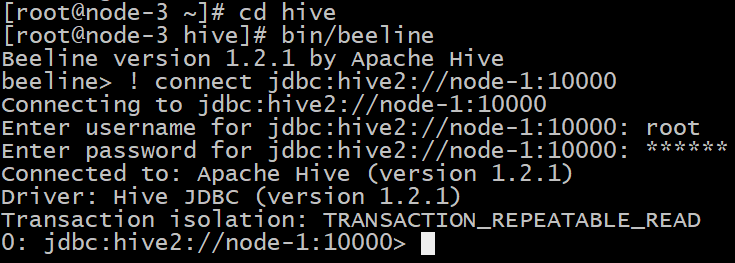
啟動成功後,可以在別的節點上用beeline去連線
bin/beeline -u jdbc:hive2://mini1:10000 -n root
或者 先啟動主節點
bin/hiveserver2 //在主節點作為伺服器啟動
bin/beeline //在其他節點上連線 ! connect jdbc:hive2://node-1:10000 //node-1為主機名 預設埠號10000
node-1作為主節點啟動 node-3做遠端連線 連線成功伺服器會列印ok

可以看到 hive源資料庫一樣 不管是本機啟動 還是遠端訪問 使用的都是mysql中的資料
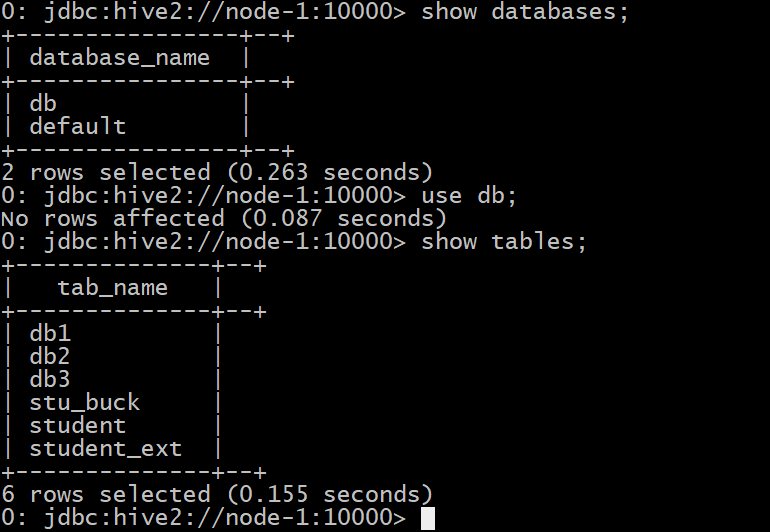
六 hive基本操作
DDL 建立表 分隔符 對映資料檔案
建表語法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
說明:
1、 CREATE TABLE 建立一個指定名字的表。如果相同名字的表已經存在,則丟擲異常;
使用者可以用 IF NOT EXISTS 選項來忽略這個異常。
2、 EXTERNAL 關鍵字可以讓使用者建立一個外部表,在建表的同時指定一個指向實際資料的路徑(LOCATION) 。
Hive 建立內部表時,會將資料移動到資料倉庫指向的路徑;若建立外部表,僅記錄資料所在的路徑,不對資料的位置做任何改變。在刪除表的時候,內部表的元資料和資料會被一起刪除,而外部表只刪除元資料,不刪除資料。
3、 LIKE 允許使用者複製現有的表結構,但是不復制資料。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table;
4、
ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value,...)]
hive 建表的時候預設的分割符是'\001',若在建表的時候沒有指明分隔符,load 檔案的時候檔案的分隔符需要是'\001';若檔案分隔符不是'001',程式不會報錯,但表查詢的結果會全部為'null';
用 vi 編輯器 Ctrl+v 然後 Ctrl+a 即可輸入'\001' -----------> ^A
SerDe 是 Serialize/Deserilize 的簡稱,目的是用於序列化和反序列化。
Hive 讀取檔案機制:首先呼叫 InputFormat(預設 TextInputFormat),返回一條一條記錄(預設是一行對應一條記錄)。然後呼叫SerDe(預設LazySimpleSerDe)的 Deserializer,將一條記錄切分為各個欄位(預設'\001') 。
Hive 寫檔案機制:將 Row 寫入檔案時,主要呼叫 OutputFormat、SerDe 的Seriliazer,順序與讀取相反。
可通過 desc formatted 表名;進行相關資訊檢視。
當我們的資料格式比較特殊的時候,可以自定義 SerDe。
5、 PARTITIONED BY
在 hive Select 查詢中一般會掃描整個表內容,會消耗很多時間做沒必要的工作。有時候只需要掃描表中關心的一部分資料,因此建表時引入了 partition 分割槽
概念。
分割槽表指的是在建立表時指定的 partition 的分割槽空間。一個表可以擁有一個或者多個分割槽,每個分割槽以資料夾的形式單獨存在表文件夾的目錄下。表和列名不區分大小寫。分割槽是以欄位的形式在表結構中存在,通過 describe table 命令可以檢視到欄位存在,但是該欄位不存放實際的資料內容,僅僅是分割槽的表示。
6、 STORED AS SEQUENCEFILE|TEXTFILE|RCFILE
如果檔案資料是純文字,可以使用 STORED AS TEXTFILE。如果資料需要壓縮,使用 STORED AS SEQUENCEFILE。
TEXTFILE 是預設的檔案格式,使用 DELIMITED 子句來讀取分隔的檔案。
6、CLUSTERED BY INTO num_buckets BUCKETS
對於每一個表(table)或者分,Hive 可以進一步組織成桶,也就是說桶是更為細粒度的資料範圍劃分。Hive 也是針對某一列進行桶的組織。Hive 採用對列值雜湊,然後除以桶的個數求餘的方式決定該條記錄存放在哪個桶當中。
把表(或者分割槽)組織成桶(Bucket)有兩個理由:
(1)獲得更高的查詢處理效率。桶為表加上了額外的結構,Hive 在處理有些查詢時能利用這個結構。具體而言,連線兩個在(包含連線列的)相同列上劃分了桶的表,可以使用 Map 端連線 (Map-side join)高效的實現。比如 JOIN 操作。對於 JOIN 操作兩個表有一個相同的列,如果對這兩個表都進行了桶操作。那麼將儲存相同列值的桶進行 JOIN 操作就可以,可以大大較少 JOIN 的資料量。
(2)使取樣(sampling)更高效。在處理大規模資料集時,在開發和修改查詢的階
段,如果能在資料集的一小部分資料上試執行查詢,會帶來很多方便。
SQL語言共分為四大類:
資料查詢語言DQL,
資料操縱語言DML,
資料定義語言DDL,
資料控制語言DCL。
與傳統sql保持一致
[可加可不加]
| 只選其一
支援傳統sql資料型別 與java資料型別
建表的時候要根據表的資料特徵 指定分隔符
複雜型別的資料表指定分隔符
預設分隔符
Ctrl v Ctrl a
指定分隔符(逗號分隔符):
create table db1 (id int,name string, age int) row format delimited fields terminated by ',';
複雜型別的資料表指定分隔符:
create table complex_array(name string,work_locations array<string>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',';
下面為具體操作:
表的mysql中 表的對映
結構化的檔案 對映為一張表
例如 1,ali
2,anqila
首先上傳到hdfs上 hive用hdfs做資料儲存
copy檔案:
hadoop fs -cp /hivedata/db1.txt /user/hive/warehouse/db.db/db1
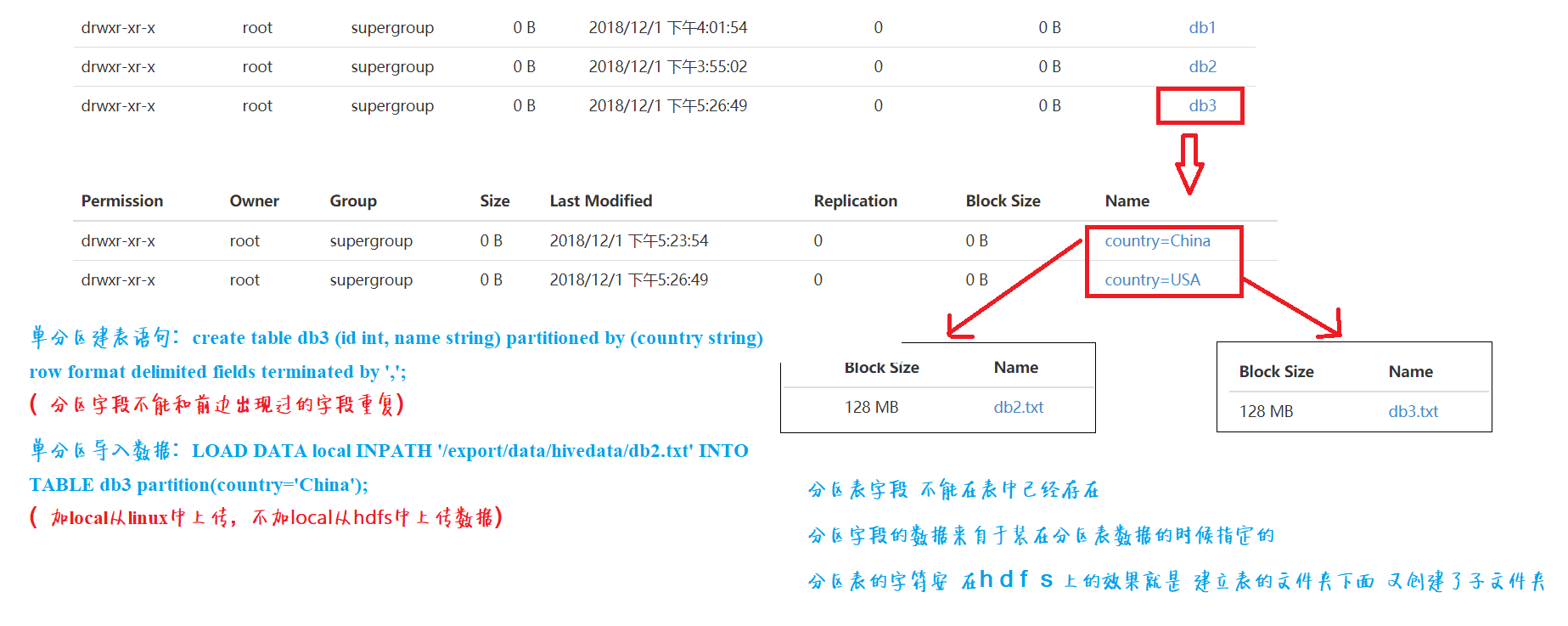
分割槽表
分割槽表字段 不能在表中已經存在
分割槽欄位的資料來自於裝在分割槽表資料的時候指定的
分割槽表的字元 在hdfs上的效果就是 建立表的資料夾下面 又建立了子資料夾
這樣把資料劃分更細緻 提高效率
單分割槽建表語句:
create table db3 (id int, name string) partitioned by (country string) row format delimited fields terminated by ',';
單分割槽匯入資料語句:
create table db3 (id int, name string) partitioned by (country string) row format delimited fields terminated by ',';
分桶表:
建立之前 首先開啟分桶功能
#指定開啟分桶
set hive.enforce.bucketing = true; set mapreduce.job.reduces=4;
TRUNCATE TABLE stu_buck;
刪除表:
drop table stu_buck;
建立表:
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) sorted by(Sno DESC) into 4 buckets row format delimited fields terminated by ',';
建立一個臨時表: 將臨時表中的資料匯入到分桶表中
分桶表匯入資料
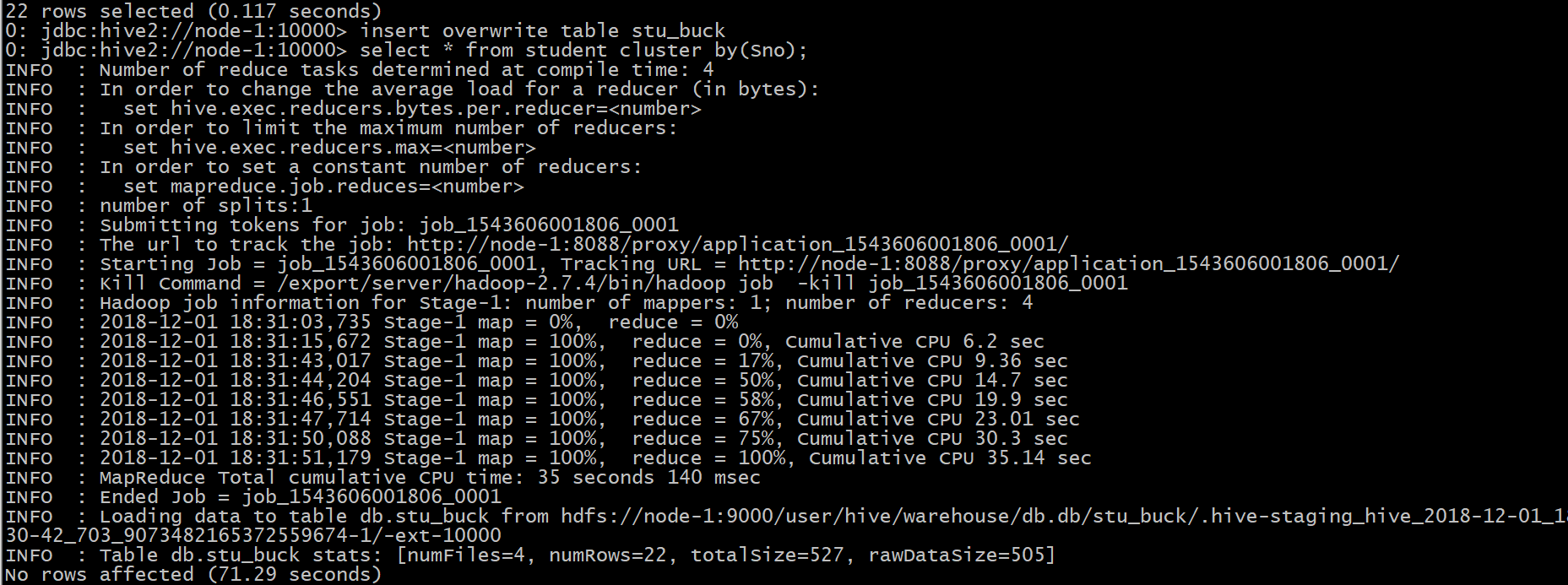
insert overwrite table stu_buck select * from student cluster by(Sno);
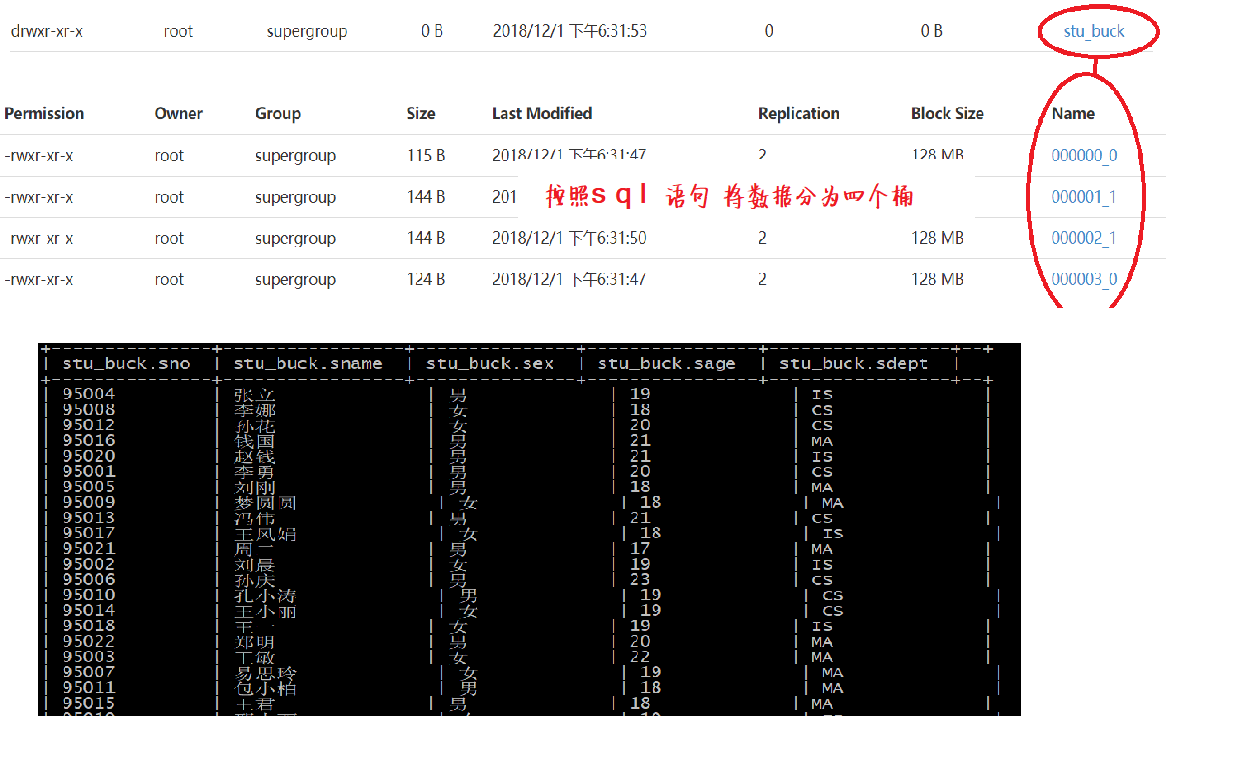
分桶表的資料 採用 insert+select 插入的資料來自於查詢結果(查詢的時候執行了mr程式)
對應mr當中的partitioner
分桶表(分簇表)建立的時候 分桶表字段 必須是表中已經存在的欄位
也就是說 要按照表中的某個欄位進行分桶
建立外部表:
create external table student_ext(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',' location '/stu';
(location'/****'要有相對應的格式化檔案)
修改表
增加分割槽:
ALTER TABLE table_name ADD PARTITION (dt='20170101') location '/user/hadoop/warehouse/table_name/dt=20170101'; //一次新增一個分割槽
ALTER TABLE table_name ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808' PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809'; //一次新增多個分割槽
刪除分割槽:
ALTER TABLE table_name DROP IF EXISTS PARTITION (dt='2008-08-08'); ALTER TABLE table_name DROP IF EXISTS PARTITION (dt='2008-08-08', country='us');
修改分割槽
ALTER TABLE table_name PARTITION (dt='2008-08-08') RENAME TO PARTITION (dt='20080808');
新增列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name STRING); 注: ADD 是代表新增一 個 欄位, 新增 欄位位置在所有列後面 (partition列前 )
REPLACE則是表示 替換表中所有欄位 。
修改列
test_change (a int, b int, c int);
ALTER TABLE test_change CHANGE a a1 INT; //修改 a 欄位名
// will change column a's name to a1, a's data type to string, and put it after column b. The new table's structure is: b int, a1 string, c int
ALTER TABLE test_change CHANGE a a1 STRING AFTER b;
// will change column b's name to b1, and put it as the first column. The new table's structure is: b1 int, a ints, c int ALTER TABLE test_change CHANGE b b1 INT FIRST;
表重新命名
ALTER TABLE table_name RENAME TO new_table_name
顯示命令
show tables; //顯示當前資料庫所有表
show databases |schemas; //顯示所有資料庫
show partitions table_name; //顯示錶分割槽資訊,不是分割槽表執行報錯
show functions; //顯示當前版本 hive 支援的所有方法
desc extended table_name; //查看錶資訊
desc formatted table_name; //查看錶資訊(格式化美觀)
describe database database_name; //檢視資料庫相關資訊