
JVM知識總結-GC收集器
阿新 • • 發佈:2018-12-03
JVM垃圾收集器目前實現有以下幾類:
- 新生代收集器:Serial, ParNew, Parallel Scavenge;
- 老年代收集器:CMS, Serial Old, Parallel Old;
- 跨界收集器:G1
如下圖所示,存在連線線的收集器表示可以搭配使用(圖引自《深入理解JVM虛擬機器》)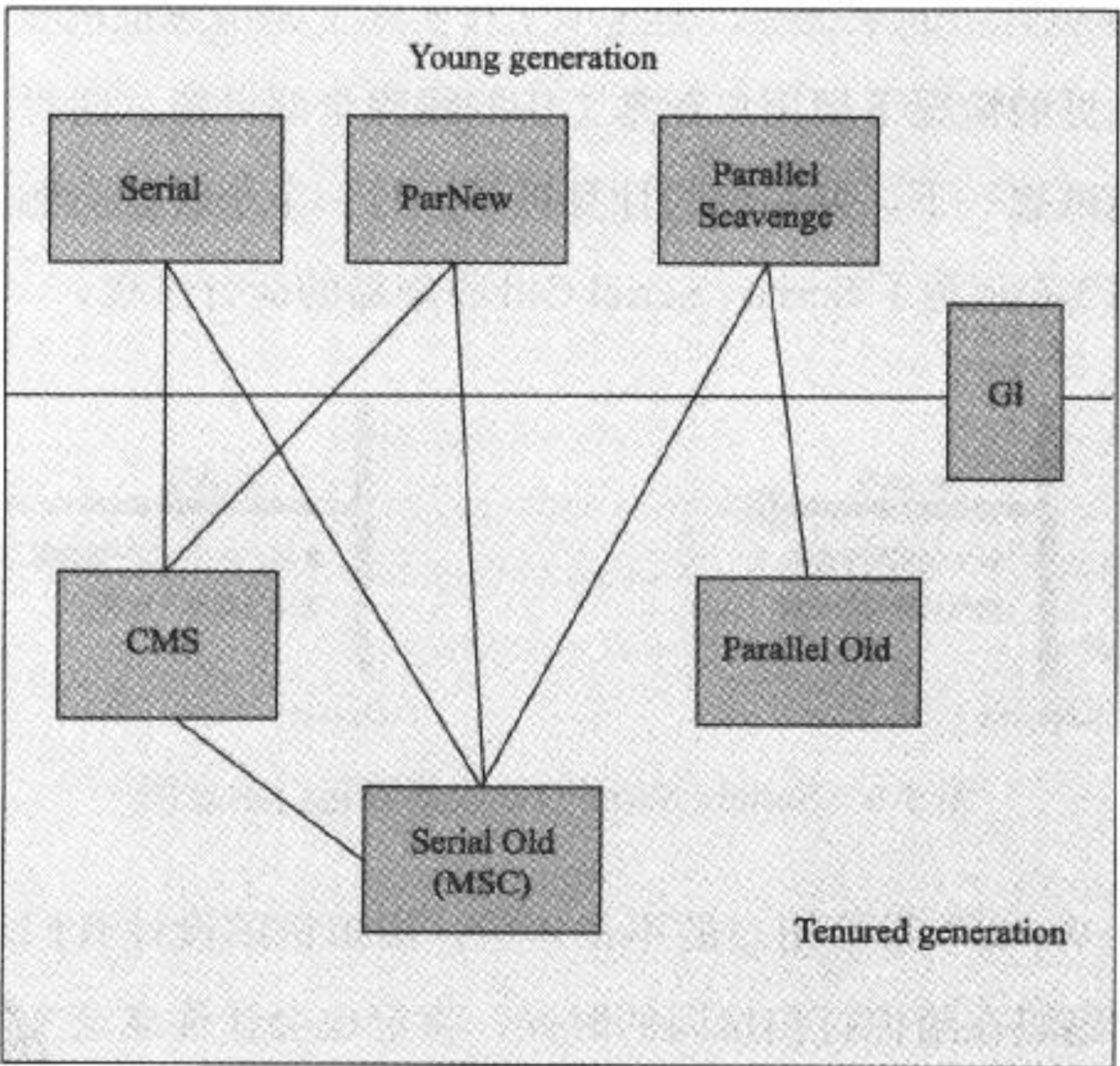
垃圾收集場景下的併發和並行
- 並行(Parallel):多條垃圾收集執行緒並行工作,但使用者執行緒處於等待狀態;
- 併發(Concurrent):使用者執行緒與垃圾收集執行緒同時執行,但並不一定是並行,也可能是交替執行,使用者程式和垃圾收集執行在不同的CPU上;
收集器介紹
-
Serial收集器:僅僅使用一個執行緒去進行垃圾收集工作,且垃圾收集執行緒工作時,需要暫停使用者正常工作的執行緒,即STOP THE WORLD,適用於單CPU的場景,client模式下JVM預設新生代收集器;
-
ParNew收集器:Serial收集器的多執行緒版,Server模式JVM新生代預設收集器,一般與CMS搭配使用;
-
Parallel Scanvenge收集器:多執行緒並行新生代收集器,與ParNew的區別在於此收集器更加關注對系統吞吐量的提升,吞吐量=使用者執行緒執行時間/系統執行總時間,比較適合用在CPU密集型的應用程式上;
-
Serial Old收集器:Serial收集器的老年代版本,使用標記-整理演算法,主要用於client模式下,可以與Parallel Scanvenge收集器搭配使用;
-
Parallel Old收集器:Parallel Scanvenge的老年代版本,使用標記-整理演算法,與Parallel Scanvenge搭配使用;
-
CMS收集器:以獲取最短回收停頓時間為目標的收集器,使用標記-清除演算法,每個回收週期可總結為以下六步:
- 初始標記:需要STW,但僅標記與GC ROOTS能直接關聯到的物件,因此耗時很短;
- 併發標記:不需要STW,使用一個或多個程序進行GC ROOTS Tracing,耗時較長;
- 再次併發標記:不需要STW,使用一個程序進行GC ROOTS tracing,彌補上個步驟執行時物件的變化;
- 重新標記:需要STW,主要是對併發標記期間程式執行物件發生變動的補充,停頓時間比初始標記稍長,但也遠短於併發標記;
- 併發清除:不需要STW,使用一個程序不可達物件進行回收,耗時較長;
- 重置:不需要STW,使用一個程序resize heap區域,併為下次週期準備資料;
cms收集器有以下缺點: - 對CPU資源敏感,由於佔用了一部分執行緒資源會導致應用程式執行變慢,雖然使用增量式併發收集器(Incremental-CMS)解決執行緒獨佔的問題,讓收集執行緒和應用程式執行緒交替執行,但效果一般,且官文明確表示該模式會在未來版本中被移除;
- 無法處理浮動垃圾(Floating Garbage),即在垃圾清理的過程中,依然會有垃圾物件產生,這部分垃圾物件被稱為浮動垃圾,因此CMS收集器需要在老年代為應用程式預留足夠的空間備用,而不能等到老年代幾乎被塞滿後再執行,1.6中CMS的預設啟動閾值為92%,當CMS執行時預留的記憶體無法滿足應用程式使用,會丟擲"Concurrent Mode Failure",VM將啟用Serial Old收集器來重新進行老年代的垃圾收集
- 由於使用的是標記-清理演算法,因此會產生大量的空間碎片,當碎片過多無法儲存大物件時,就會觸發full GC,CMS提供了兩個引數,UseCMSCompactAtFullCollection和CMSFullGCsBeforeCompation,前者指定在full GC時進行碎片整理,後者指定每隔幾次full GC會進行一次碎片整理,預設值為0;
-
G1收集器:官方最先進的垃圾收集技術,G1將java堆劃分為多個大小相等的獨立區域(Region),雖然還保留新生代、老年代的概念,但不再物理隔離,他們都是一部分Region(不需要連續)的集合具備如下特點:
- 並行與併發:充分利用多CPU的硬體優勢,縮短STW時間;
- 分代收集:使用不同的方式收集新建物件、熬過多次GC的舊物件獲取更好的收集效果;
- 空間整合:整體看來G1是基於標記-整理演算法的,收集期間不會產生記憶體空間碎片;
- 可預測的停頓:G1可以建立可預測的停頓時間模型,能讓使用者指定M毫秒內垃圾收集時間不超過N毫秒,G1在後臺維護一個有限列表跟蹤每個Region的回收價值,每次根據允許的垃圾收集時間優先回收價值最大的Region;
G1需要解決的問題:
G1"化整為零的"方式,給垃圾回收時的可達性分析帶來了麻煩,因為一個Region裡的物件可能和其他所有Region中的物件有引用關係,為了避免全堆掃描,G1使用Remembered Set記錄物件的引用資訊,在進行記憶體回收時加入Remembered Set即可不進行全堆掃描並不會有遺漏; G1的執行步驟: - 初始標記:需要STW,標記GC Roots能直接關聯到的物件,並修改TAMS(Next Top at Mark Start)值,讓下一階段使用者程式執行時在正確的Region中建立物件;
- 併發標記:不需要STW,進行GC Tracing可達性分析,耗時較長;
- 最終標記:需要STW,對併發標記的遺漏進行補充,並將此期間內物件的變化記錄到Remembered Set Logs,併合併到Remembered Set中;
- 篩選回收:對各個Region的回收價值排序,根據使用者期望的GC停頓時間制定回收計劃,可以與使用者程式併發執行,但停頓使用者執行緒會大幅提高回收效率;