程序的切換和系統的一般執行過程
2018-2019-120189224 《庖丁解牛Iinux核心分析》第九周學習總結
程序切換過程中有兩個重要問題:一是進行排程的時機;二是程序切換的過程。本次學習總結將圍繞以上兩部分內容展開。
程序排程的時機
程序切換過程
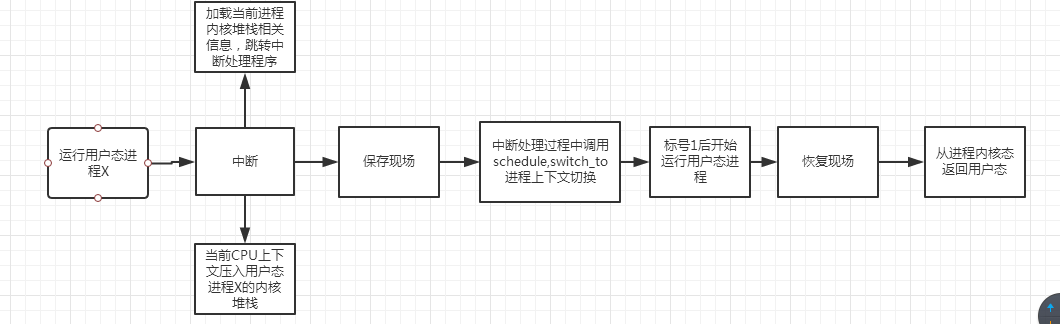
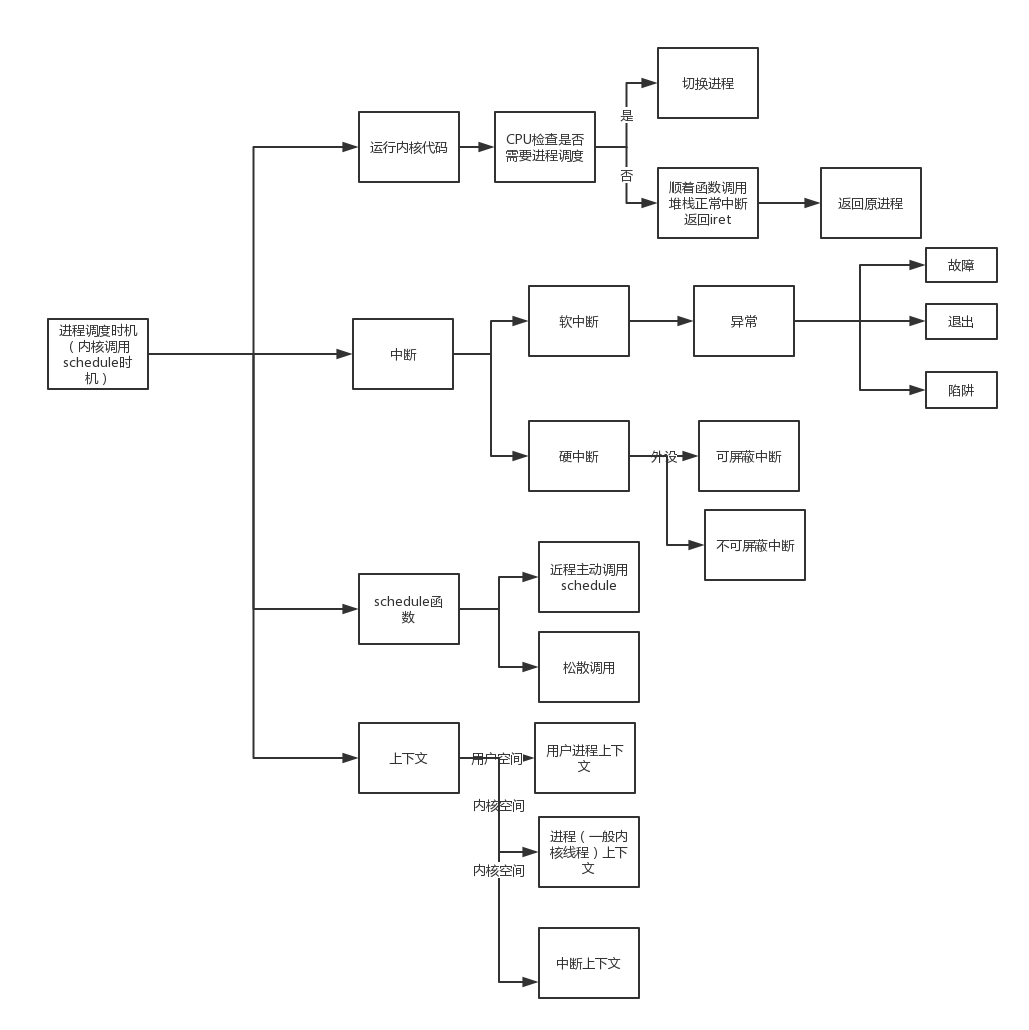
程序排程由作業系統核心進行,目的是合理分配系統資源,令每個程序都能獲得執行時間。程序排程由schedule函式負責,該函式是作業系統核心函式,並非系統呼叫,只能在核心態中由核心程式碼主動呼叫。因此,使用者態程序無法主動進行程序排程,只能在中斷髮生時被動排程。schedule函式的呼叫時機在之前系統呼叫課程中已經提及,位於系統呼叫返回後,返回使用者態程式碼之前,核心可能會呼叫schedule。除了系統呼叫之外,軟中斷、硬終端以及異常都有可能進行程序排程。程序排程的具體任務是對上下文進行切換,即儲存當前程序的上下文,載入將被排程程序的上下文。類似於系統呼叫的保護現場和恢復現場,但其中有本質區別:保護恢復現場涉及的是同一個程序的上下文,而程序排程的上下文切換則涉及兩個不同程序的上下文。
使用gdb跟蹤分析schedule
啟動實驗樓虛擬機器,執行Linux核心,使用-s -S引數暫停核心執行。然後啟動gdb,讀取符號表、連線核心並設定斷點:schedule(),context_switch()。
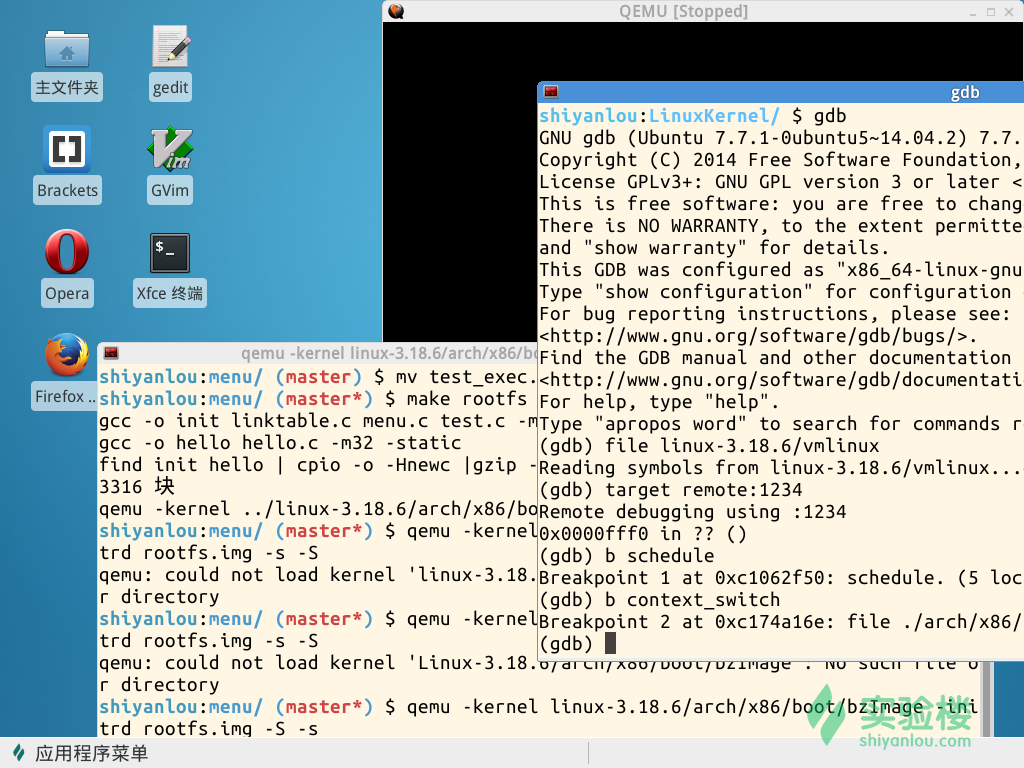
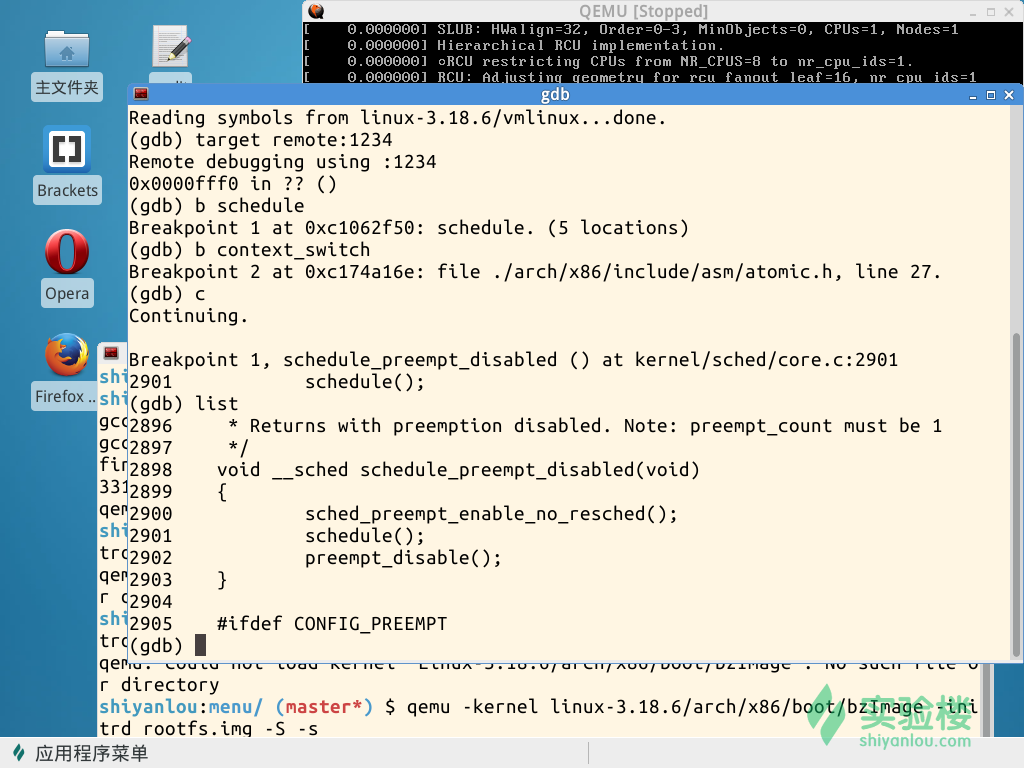
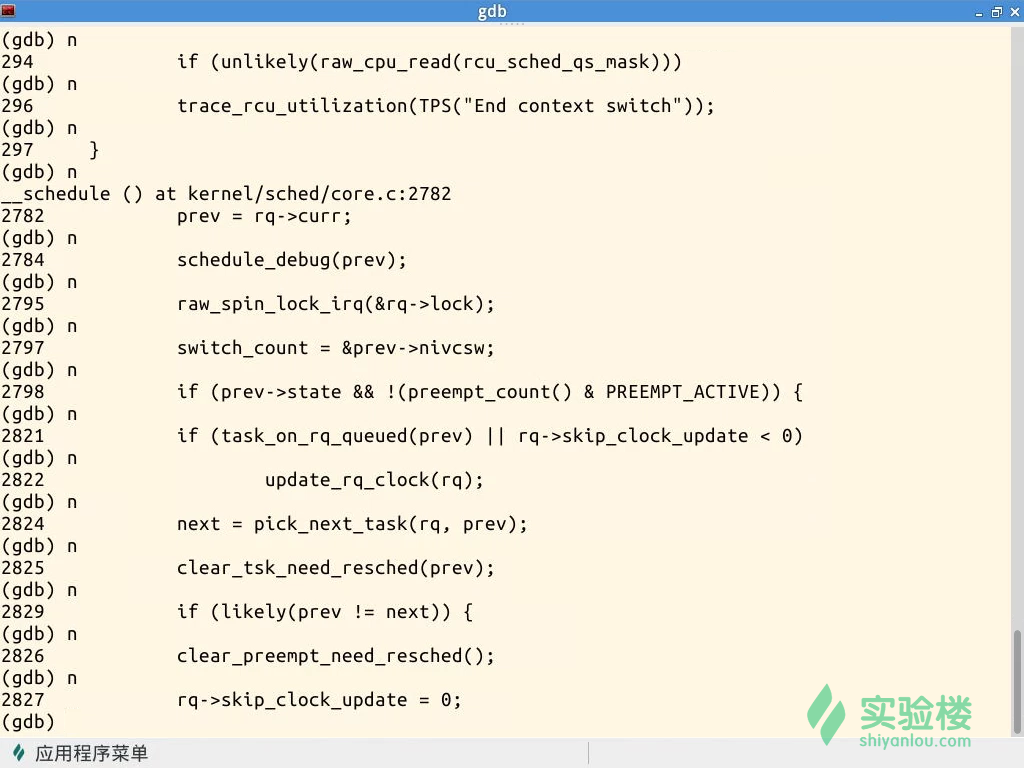
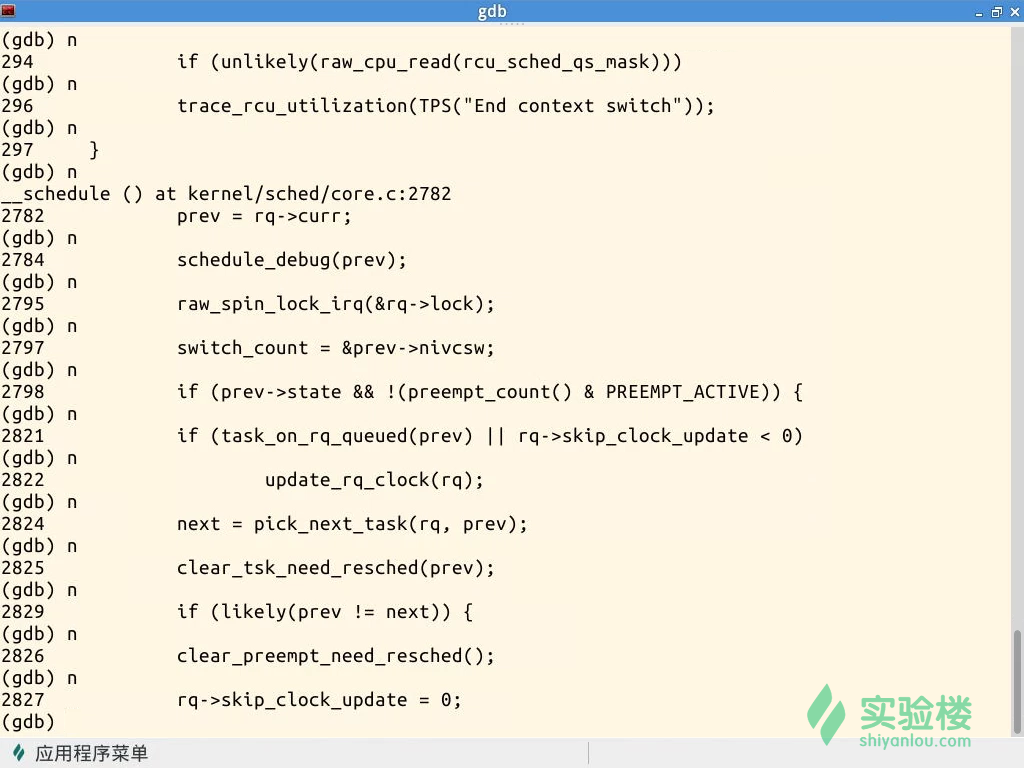
schedule函式是程序排程的主體函式,其中的pick_next_task負責根據排程策略和排程演算法選擇下一個程序。
2865asmlinkage __visible void __sched schedule(void) 2866{ 2867 struct task_struct *tsk = current; 2868 2869 sched_submit_work(tsk); 2870 __schedule(); 2871} 2872EXPORT_SYMBOL(schedule);
context_switch函式是schedule函式中實現程序切換的函式,上下文切換的關鍵程式碼由巨集switch_to給出:
31#define switch_to(prev, next, last) \ 32do { \ 33 /* \ 34 * Context-switching clobbers all registers, so we clobber \ 35 * them explicitly, via unused output variables. \ 36 * (EAX and EBP is not listed because EBP is saved/restored \ 37 * explicitly for wchan access and EAX is the return value of \ 38 * __switch_to()) \ 39 */ \ 40 unsigned long ebx, ecx, edx, esi, edi; \ 41 \ 42 asm volatile("pushfl\n\t" /* save flags */ \ 43 "pushl %%ebp\n\t" /* save EBP */ \ 44 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \ 45 "movl %[next_sp],%%esp\n\t" /* restore ESP */ \ 46 "movl $1f,%[prev_ip]\n\t" /* save EIP */ \ 47 "pushl %[next_ip]\n\t" /* restore EIP */ \ 48 __switch_canary \ 49 "jmp __switch_to\n" /* regparm call */ \ 50 "1:\t" \ 51 "popl %%ebp\n\t" /* restore EBP */ \ 52 "popfl\n" /* restore flags */ \ 53 \ 54 /* output parameters */ \ 55 : [prev_sp] "=m" (prev->thread.sp), \ 56 [prev_ip] "=m" (prev->thread.ip), \ 57 "=a" (last), \ 58 \ 59 /* clobbered output registers: */ \ 60 "=b" (ebx), "=c" (ecx), "=d" (edx), \ 61 "=S" (esi), "=D" (edi) \ 62 \ 63 __switch_canary_oparam \ 64 \ 65 /* input parameters: */ \ 66 : [next_sp] "m" (next->thread.sp), \ 67 [next_ip] "m" (next->thread.ip), \ 68 \ 69 /* regparm parameters for __switch_to(): */ \ 70 [prev] "a" (prev), \ 71 [next] "d" (next) \ 72 \ 73 __switch_canary_iparam \ 74 \ 75 : /* reloaded segment registers */ \ 76 "memory"); \ 77} while (0)
以上是switch_to中的關鍵程式碼,可以看到這份程式碼與my_schedule中的程式碼十分相似。都是先將當前程序的上下文(包括flags、ebp等)壓入棧中儲存,然後修改當前程序的eip,使當前程序下次執行時能從標號1的位置執行,最後載入將要被排程的程序的eip,新程序會從標號1處開始執行,按照順序從棧中獲得自己的上下文(新程序的ebp和flags等)。不同之處在於my_schedule利用ret命令執行新程序,而switch_to則通過跳轉到_switch_to來執行新程序。由於使用了jmp而不是call,執行_switch_to前沒有壓棧,而__switch_to執行完畢後要出棧,這就將新程序的下一條指令地址賦給了eip暫存器。
程序排程過程總結
程序排程是為了合理分配計算機資源,並讓每個程序都獲得適當的執行機會。由於程序排程函式schedule是核心態函式,且並非系統呼叫,故使用者態程序只能在發生中斷時被動地排程。而核心態執行緒即可以被動排程,也可以主動發起程序排程。被動程序排程的時機位於發生中斷並且系統執行完畢對應的中斷服務程式之後。
作業系統的一般執行狀態可描述如下: