
Java高頻面試題匯總--Java職場範兒
經歷了兩周的面試,終於收到了幾個滿意的offer。換工作的過程是痛苦的,除了一天馬不停蹄地跑好幾家公司面試,剩下的時間基本就是背面試題了。想找到一份適合自己的面試題並不簡單,比如我找的是高級Java開發的職位。出於之前公司系統架構的設計,需要準備Java、spring、springboot、mysql、mybatis、mycat、zookeeper、dubbo、kafka、redis、網絡等面試題。我結合之前面試的20多家公司,以及從CSDN/簡書/掘金/公眾號等相關渠道搜集到的面試題,從中整理出一些高頻的面試題庫,幫助大家更加省力從容的應付面試。更全的整理題庫,可以通過搜索微信小程序【Java職場範兒
Java面試題
反射篇
一、Java獲取Class文件的幾種方式?
//1.通過Object類中的getClass()方法的。
public static void getClassObject_1() {
Person p = new Person();
Class clazz = p.getClass();
} //2.任何數據類型都具備一個靜態的屬性.class來獲取其對應的Class對象 public static void getClassObject_1() { Class clazz = Person.class; }
//3.只要通過給定的類的字符串名稱就可以獲取該類
public static void getClassObject_1() {
String className = "Person";
Class clazz = Class.forName(className);
} 二、如何獲取Class中的私有方法?
Method method = e.getClass().getDeclaredMethod("私有方法名",String.class);集合+並發篇
一、 HashMap和ConcurrentHashMap的原理(並發必問)
HashMap:
1.7版本,使用一個Entry數組來存儲數據,用key的hashcode取模來決定key會被放到數組裏的位置,如果hashcode相同,或者hashcode取模後的結果相同(hash collision),那麽這些key會被定位到Entry數組的同一個格子裏,這些key會形成一個鏈表。在hashcode特別差的情況下,比方說所有key的hashcode都相同,這個鏈表可能會很長,那麽put/get操作都可能需要遍歷這個鏈表。也就是說時間復雜度在最差情況下會退化到O(n)
ConcurrentHashMap:
在多線程環境下,使用HashMap進行put操作時存在丟失數據的情況,為了避免這種bug的隱患,強烈建議使用ConcurrentHashMap代替HashMap。
1.7版本,使用Segment + HashEntry方式進行實現。
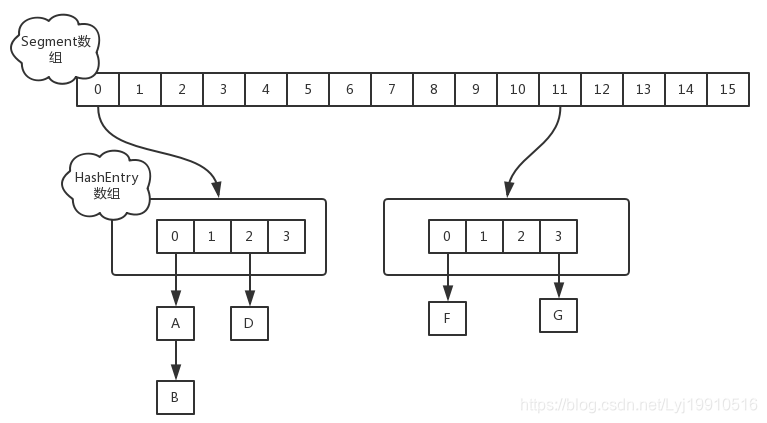
1.8版本,1.8中放棄了Segment臃腫的設計,取而代之的是采用Node + CAS + Synchronized來保證並發安全進行實現,結構如下:
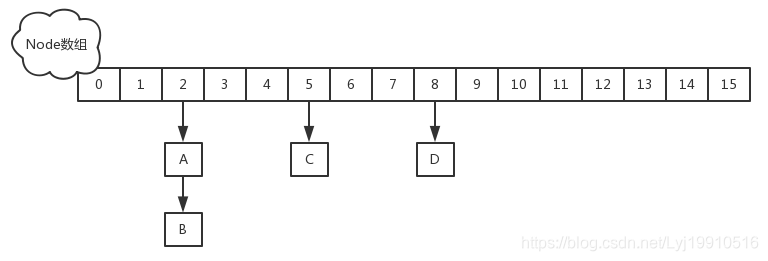
更詳細的內容請參考《Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析》
二、 常見的線程池及應用場景
- newCacheThreadPool 無大小,適合時間段速度快的
- newFixedThreadPool 有大小,負載比較重的
- newSingleThreadExecutor 單個有序
- newScheduleThreadPool 周期性的任務
三、 阻塞隊列
- arrayblockingqueue:有界,不公平的阻塞(可以通過構造器設置成公平的)
- linkedblockingqueue:有界,先進先出
- priorityblockingqueue:按照特定字段排序
- delayqueue:延遲(緩存是否過期,定時調度)
- synchronousqueue:不存儲元素,充當傳球手
- linkedtransferqueue:×××,如果有消費者等待,就直接傳給消費者,否則放入隊列
-
linkedblockingdeque:雙向阻塞
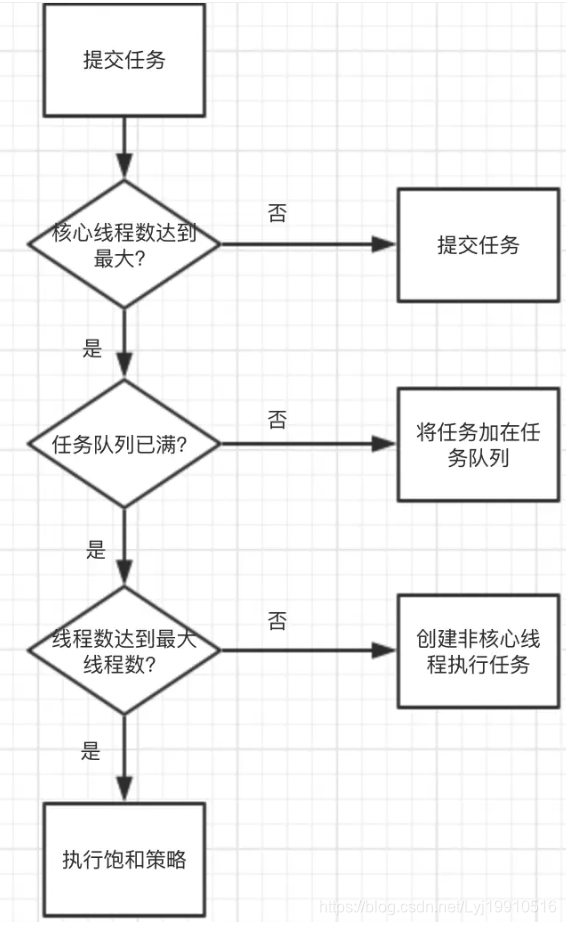
四、 線程池的處理流程
五、Lock與synchronized 的區別
synchronized:
在資源競爭不是很激烈的情況下,偶爾會有同步的情形下,synchronized是很合適的。原因在於,編譯程序通常會盡可能的進行優化synchronize,另外可讀性非常好,不管用沒用過5.0多線程包的程序員都能理解。
ReentrantLock:
ReentrantLock提供了多樣化的同步,比如有時間限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在資源競爭不激烈的情形下,性能稍微比synchronized差點點。但是當同步非常激烈的時候,synchronized的性能一下子能下降好幾十倍。而ReentrantLock確還能維持常態。JVM
一、 JVM內存分哪幾個區,每個區的作用是什麽
Java虛擬機主要分為以下一個區:
-
方法區:
- 有時候也成為永久代,在該區內很少發生垃圾回收,但是並不代表不發生GC,在這裏進行的GC主要是對方法區裏的常量池和對類型的卸載
- 方法區主要用來存儲已被虛擬機加載的類的信息、常量、靜態變量和即時編譯器編譯後的代碼等數據。
- 該區域是被線程共享的。
- 方法區裏有一個運行時常量池,用於存放靜態編譯產生的字面量和符號引用。該常量池具有動態性,也就是說常量並不一定是編譯時確定,運行時生成的常量也會存在這個常量池中。
-
虛擬機棧:
- 虛擬機棧也就是我們平常所稱的棧內存,它為java方法服務,每個方法在執行的時候都會創建一個棧幀,用於存儲局部變量表、操作數棧、動態鏈接和方法出口等信息。
- 虛擬機棧是線程私有的,它的生命周期與線程相同。
- 局部變量表裏存儲的是基本數據類型、returnAddress類型(指向一條字節碼指令的地址)和對象引用,這個對象引用有可能是指向對象起始地址的一個指針,也有可能是代表對象的句柄或者與對象相關聯的位置。局部變量所需的內存空間在編譯器間確定
- 操作數棧的作用主要用來存儲運算結果以及運算的操作數,它不同於局部變量表通過索引來訪問,而是壓棧和出棧的方式
- 每個棧幀都包含一個指向運行時常量池中該棧幀所屬方法的引用,持有這個引用是為了支持方法調用過程中的動態連接.動態鏈接就是將常量池中的符號引用在運行期轉化為直接引用。
-
本地方法棧
- 本地方法棧和虛擬機棧類似,只不過本地方法棧為Native方法服務。
-
堆
- java堆是所有線程所共享的一塊內存,在虛擬機啟動時創建,幾乎所有的對象實例都在這裏創建,因此該區域經常發生垃圾回收操作。
- 程序計數器
- 內存空間小,字節碼解釋器工作時通過改變這個計數值可以選取下一條需要執行的字節碼指令,分支、循環、跳轉、異常處理和線程恢復等功能都需要依賴這個計數器完成。該內存區域是唯一一個java虛擬機規範沒有規定任何OOM情況的區域。
二、java中垃圾收集的方法有哪些?
- 標記-清除:
這是垃圾收集算法中最基礎的,根據名字就可以知道,它的思想就是標記哪些要被回收的對象,然後統一回收。這種方法很簡單,但是會有兩個主要問題:1.效率不高,標記和清除的效率都很低;2.會產生大量不連續的內存碎片,導致以後程序在分配較大的對象時,由於沒有充足的連續內存而提前觸發一次GC動作。 - 復制算法:
為了解決效率問題,復制算法將可用內存按容量劃分為相等的兩部分,然後每次只使用其中的一塊,當一塊內存用完時,就將還存活的對象復制到第二塊內存上,然後一次性清楚完第一塊內存,再將第二塊上的對象復制到第一塊。但是這種方式,內存的代價太高,每次基本上都要浪費一般的內存。
於是將該算法進行了改進,內存區域不再是按照1:1去劃分,而是將內存劃分為8:1:1三部分,較大那份內存交Eden區,其余是兩塊較小的內存區叫Survior區。每次都會優先使用Eden區,若Eden區滿,就將對象復制到第二塊內存區上,然後清除Eden區,如果此時存活的對象太多,以至於Survivor不夠時,會將這些對象通過分配擔保機制復制到老年代中。(java堆又分為新生代和老年代) - 標記-整理
該算法主要是為了解決標記-清除,產生大量內存碎片的問題;當對象存活率較高時,也解決了復制算法的效率問題。它的不同之處就是在清除對象的時候現將可回收對象移動到一端,然後清除掉端邊界以外的對象,這樣就不會產生內存碎片了。 - 分代收集
現在的虛擬機垃圾收集大多采用這種方式,它根據對象的生存周期,將堆分為新生代和老年代。在新生代中,由於對象生存期短,每次回收都會有大量對象死去,那麽這時就采用復制算法。老年代裏的對象存活率較高,沒有額外的空間進行分配擔保,所以可以使用標記-整理 或者 標記-清除。
三、java內存分配與回收策率以及Minor GC和Major GC
- 對象優先在堆的Eden區分配。
- 大對象直接進入老年代.
- 長期存活的對象將直接進入老年代.
- 當Eden區沒有足夠的空間進行分配時,虛擬機會執行一次Minor GC.Minor Gc通常發生在新生代的Eden區,在這個區的對象生存期短,往往發生Gc的頻率較高,回收速度比較快;Full Gc/Major GC 發生在老年代,一般情況下,觸發老年代GC的時候不會觸發Minor GC,但是通過配置,可以在Full GC之前進行一次Minor GC這樣可以加快老年代的回收速度。
Java高頻面試題匯總--Java職場範兒