
【尋優演算法】遺傳演算法(Genetic Algorithm) 引數尋優的python實現
【尋優演算法】遺傳演算法(Genetic Algorithm) 引數尋優的python實現
本博文首先簡單介紹遺傳演算法(GA)的基礎知識,然後以為非線性SVM為例給出遺傳演算法多引數尋優的python實現。
一、遺傳演算法簡介
遺傳演算法介紹部分主要參考(資料【1】),介紹過程中為方便大家理解相關概念,會有部分本人的理解,如有錯誤,請在評論區指正。
1、遺傳演算法由來
本人之前的兩篇博文(資料【2,3】)分別介紹瞭如何用交叉驗證方法進行單一引數和多引數尋優,交叉驗證其實只是計算模型的評價指標的方法,引數的搜尋過程其實是根據提前給出的取值範圍進行窮舉,如果引數取值範圍給定的不合理,最優化引數就無從談起。有沒有一種方法,引數的取值範圍可以隨機設定,並在優化過程中不斷變化,直到找到最優引數?
遺傳演算法是模擬達爾文生物進化論的自然選擇和遺傳學機理的生物進化過程的計算模型,是一種通過模擬自然進化過程搜尋最優解的方法。
2、遺傳演算法名詞概念
染色體(個體):在引數尋優問題中一個染色體代表一個引數,染色體的十進位制數值,用於獲取待尋優引數實際輸入到模型中的值。
基因:每一個染色體都對應多個基因,基因是二進位制數,基因的取值長度是染色體的長度。遺傳演算法的交叉、變異操作都是對染色體的基因進行的。
種群:初始化的染色體取值範圍。
適應度函式:表徵每一組染色體(每一組引數)對應的模型評價指標(本博文的python例項中,採用3-flod 交叉檢驗的平均值作為適應度函式值)。
假設對於兩個引數的尋優,我們設定染色體長度為20,種群數為200,就是說初始化兩個染色體,每個染色體初始化200個可能的值,每一個染色體的十進位制數值用20位二進位制數表示。
3、遺傳演算法中對染色體的操作
隨機產生的初始化染色體取值範圍中,不一定包含最優的引數取值,為了找到最優的染色體,需要不斷對適應度函式值表現優秀的染色體進行操作,直到找到最優的染色體。具體操作如下:
3.1、選擇
染色體選擇是為了把適應度函式值表現好的染色體選出來,保持種群數量不變,就是將適應度函式值表現好的染色體按照更高的概率儲存到下一代種群中(下一代種群中更多的染色體是上一代適應度函式值表現好的染色體),具體方法可參考【資料1】
3.2、交叉
交叉操作是為了產生新的染色體,將不同染色體的部分基因進行交換,具體方法有單點交叉和多點交叉。
3.3、變異
變異操作同樣是為了產生新的染色體,通過改變部分染色體的部分基因。
選擇、交叉、變異這三種操作,既保證了適應度函式值表現好的染色體儘可能的保留到下一代種群,又能保證下一代種群的變化,可以產生新的染色體。
二、遺傳演算法多引數尋優思路
多引數尋優和單一引數尋優的基本思路是相同的,不過在種群初始化時,每次需要初始化兩個染色體,並且在選擇、交叉、變異操作時,兩個染色體是分別進行的。
步驟一:種群、染色體、基因初始化。
步驟二:計算種群中每一組染色體對應的適應度函式值。
步驟三:對種群中的染色體進行選擇、交叉、變異操作,產生新的種群。
步驟四:判斷是否滿足終止條件?如果不滿足,跳轉到步驟二;如果滿足,輸出最優引數。
步驟五:結束。
三、遺傳演算法多引數尋優的python實現
完整的python程式碼及資料樣本地址:https://github.com/shiluqiang/GA_python-for-multi-parameters-optimization
## 2. GA優化演算法
class GA(object):
###2.1 初始化
def __init__(self,population_size,chromosome_num,chromosome_length,max_value,iter_num,pc,pm):
'''初始化引數
input:population_size(int):種群數
chromosome_num(int):染色體數,對應需要尋優的引數個數
chromosome_length(int):染色體的基因長度
max_value(float):作用於二進位制基因轉化為染色體十進位制數值
iter_num(int):迭代次數
pc(float):交叉概率閾值(0<pc<1)
pm(float):變異概率閾值(0<pm<1)
'''
self.population_size = population_size
self.choromosome_length = chromosome_length
self.chromosome_num = chromosome_num
self.iter_num = iter_num
self.max_value = max_value
self.pc = pc ##一般取值0.4~0.99
self.pm = pm ##一般取值0.0001~0.1
def species_origin(self):
'''初始化種群、染色體、基因
input:self(object):定義的類引數
output:population(list):種群
'''
population = []
## 分別初始化兩個染色體
for i in range(self.chromosome_num):
tmp1 = [] ##暫存器1,用於暫存一個染色體的全部可能二進位制基因取值
for j in range(self.population_size):
tmp2 = [] ##暫存器2,用於暫存一個染色體的基因的每一位二進位制取值
for l in range(self.choromosome_length):
tmp2.append(random.randint(0,1))
tmp1.append(tmp2)
population.append(tmp1)
return population
###2.2 計算適應度函式值
def translation(self,population):
'''將染色體的二進位制基因轉換為十進位制取值
input:self(object):定義的類引數
population(list):種群
output:population_decimalism(list):種群每個染色體取值的十進位制數
'''
population_decimalism = []
for i in range(len(population)):
tmp = [] ##暫存器,用於暫存一個染色體的全部可能十進位制取值
for j in range(len(population[0])):
total = 0.0
for l in range(len(population[0][0])):
total += population[i][j][l] * (math.pow(2,l))
tmp.append(total)
population_decimalism.append(tmp)
return population_decimalism
def fitness(self,population):
'''計算每一組染色體對應的適應度函式值
input:self(object):定義的類引數
population(list):種群
output:fitness_value(list):每一組染色體對應的適應度函式值
'''
fitness = []
population_decimalism = self.translation(population)
for i in range(len(population[0])):
tmp = [] ##暫存器,用於暫存每組染色體十進位制數值
for j in range(len(population)):
value = population_decimalism[j][i] * self.max_value / (math.pow(2,self.choromosome_length) - 10)
tmp.append(value)
## rbf_SVM 的3-flod交叉驗證平均值為適應度函式值
## 防止引數值為0
if tmp[0] == 0.0:
tmp[0] = 0.5
if tmp[1] == 0.0:
tmp[1] = 0.5
rbf_svm = svm.SVC(kernel = 'rbf', C = abs(tmp[0]), gamma = abs(tmp[1]))
cv_scores = cross_validation.cross_val_score(rbf_svm,trainX,trainY,cv =3,scoring = 'accuracy')
fitness.append(cv_scores.mean())
##將適應度函式值中為負數的數值排除
fitness_value = []
num = len(fitness)
for l in range(num):
if (fitness[l] > 0):
tmp1 = fitness[l]
else:
tmp1 = 0.0
fitness_value.append(tmp1)
return fitness_value
###2.3 選擇操作
def sum_value(self,fitness_value):
'''適應度求和
input:self(object):定義的類引數
fitness_value(list):每組染色體對應的適應度函式值
output:total(float):適應度函式值之和
'''
total = 0.0
for i in range(len(fitness_value)):
total += fitness_value[i]
return total
def cumsum(self,fitness1):
'''計算適應度函式值累加列表
input:self(object):定義的類引數
fitness1(list):適應度函式值列表
output:適應度函式值累加列表
'''
##計算適應度函式值累加列表
for i in range(len(fitness1)-1,-1,-1): # range(start,stop,[step]) # 倒計數
total = 0.0
j=0
while(j<=i):
total += fitness1[j]
j += 1
fitness1[i] = total
def selection(self,population,fitness_value):
'''選擇操作
input:self(object):定義的類引數
population(list):當前種群
fitness_value(list):每一組染色體對應的適應度函式值
'''
new_fitness = [] ## 用於儲存適應度函歸一化數值
total_fitness = self.sum_value(fitness_value) ## 適應度函式值之和
for i in range(len(fitness_value)):
new_fitness.append(fitness_value[i] / total_fitness)
self.cumsum(new_fitness)
ms = [] ##用於存檔隨機數
pop_len=len(population[0]) ##種群數
for i in range(pop_len):
ms.append(random.randint(0,1))
ms.sort() ## 隨機數從小到大排列
##儲存每個染色體的取值指標
fitin = 0
newin = 0
new_population = population
## 輪盤賭方式選擇染色體
while newin < pop_len & fitin < pop_len:
if(ms[newin] < new_fitness[fitin]):
for j in range(len(population)):
new_population[j][newin]=population[j][fitin]
newin += 1
else:
fitin += 1
population = new_population
### 2.4 交叉操作
def crossover(self,population):
'''交叉操作
input:self(object):定義的類引數
population(list):當前種群
'''
pop_len = len(population[0])
for i in range(len(population)):
for j in range(pop_len - 1):
if (random.random() < self.pc):
cpoint = random.randint(0,len(population[i][j])) ## 隨機選擇基因中的交叉點
###實現相鄰的染色體基因取值的交叉
tmp1 = []
tmp2 = []
#將tmp1作為暫存器,暫時存放第i個染色體第j個取值中的前0到cpoint個基因,
#然後再把第i個染色體第j+1個取值中的後面的基因,補充到tem1後面
tmp1.extend(population[i][j][0:cpoint])
tmp1.extend(population[i][j+1][cpoint:len(population[i][j])])
#將tmp2作為暫存器,暫時存放第i個染色體第j+1個取值中的前0到cpoint個基因,
#然後再把第i個染色體第j個取值中的後面的基因,補充到tem2後面
tmp2.extend(population[i][j+1][0:cpoint])
tmp2.extend(population[i][j][cpoint:len(population[i][j])])
#將交叉後的染色體取值放入新的種群中
population[i][j] = tmp1
population[i][j+1] = tmp2
### 2.5 變異操作
def mutation(self,population):
'''變異操作
input:self(object):定義的類引數
population(list):當前種群
'''
pop_len = len(population[0]) #種群數
Gene_len = len(population[0][0]) #基因長度
for i in range(len(population)):
for j in range(pop_len):
if (random.random() < self.pm):
mpoint = random.randint(0,Gene_len - 1) ##基因變異位點
##將第mpoint個基因點隨機變異,變為0或者1
if (population[i][j][mpoint] == 1):
population[i][j][mpoint] = 0
else:
population[i][j][mpoint] = 1
### 2.6 找出當前種群中最好的適應度和對應的引數值
def best(self,population_decimalism,fitness_value):
'''找出最好的適應度和對應的引數值
input:self(object):定義的類引數
population(list):當前種群
fitness_value:當前適應度函式值列表
output:[bestparameters,bestfitness]:最優引數和最優適應度函式值
'''
pop_len = len(population_decimalism[0])
bestparameters = [] ##用於儲存當前種群最優適應度函式值對應的引數
bestfitness = 0.0 ##用於儲存當前種群最優適應度函式值
for i in range(0,pop_len):
tmp = []
if (fitness_value[i] > bestfitness):
bestfitness = fitness_value[i]
for j in range(len(population_decimalism)):
tmp.append(abs(population_decimalism[j][i] * self.max_value / (math.pow(2,self.choromosome_length) - 10)))
bestparameters = tmp
return bestparameters,bestfitness
### 2.7 畫出適應度函式值變化圖
def plot(self,results):
'''畫圖
'''
X = []
Y = []
for i in range(self.iter_num):
X.append(i + 1)
Y.append(results[i])
plt.plot(X,Y)
plt.xlabel('Number of iteration',size = 15)
plt.ylabel('Value of CV',size = 15)
plt.title('GA_RBF_SVM parameter optimization')
plt.show()
### 2.8 主函式
def main(self):
results = []
parameters = []
best_fitness = 0.0
best_parameters = []
## 初始化種群
population = self.species_origin()
## 迭代引數尋優
for i in range(self.iter_num):
##計算適應函式數值列表
fitness_value = self.fitness(population)
## 計算當前種群每個染色體的10進製取值
population_decimalism = self.translation(population)
## 尋找當前種群最好的引數值和最優適應度函式值
current_parameters, current_fitness = self.best(population_decimalism,fitness_value)
## 與之前的最優適應度函式值比較,如果更優秀則替換最優適應度函式值和對應的引數
if current_fitness > best_fitness:
best_fitness = current_fitness
best_parameters = current_parameters
print('iteration is :',i,';Best parameters:',best_parameters,';Best fitness',best_fitness)
results.append(best_fitness)
parameters.append(best_parameters)
## 種群更新
## 選擇
self.selection(population,fitness_value)
## 交叉
self.crossover(population)
## 變異
self.mutation(population)
results.sort()
self.plot(results)
print('Final parameters are :',parameters[-1])
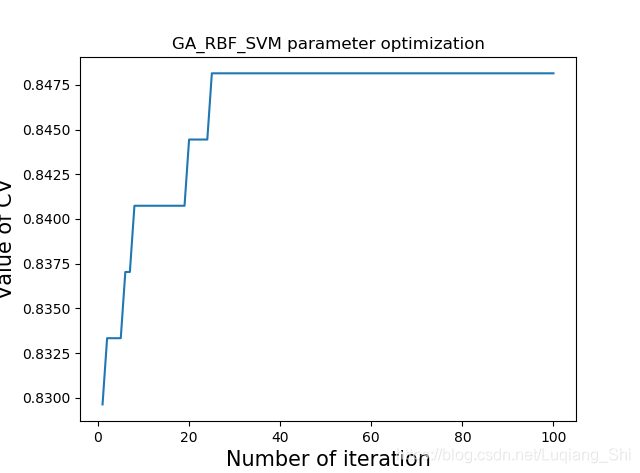
最優的適應度函式值隨迭代次數的變化如下圖所示。由圖可知,在第24次迭代時,引數達到最優,最優引數為[7.79372018547235, 0.010538201696412052]。
參考資料
1、https://blog.csdn.net/quinn1994/article/details/80501542
2、https://blog.csdn.net/Luqiang_Shi/article/details/84570133
3、https://blog.csdn.net/Luqiang_Shi/article/details/84579052