
第2章聚集索引的表和索引
聚集索引
聚集索引指示表中資料的物理順序,根據聚集排序索引鍵。該表只能定義一個聚集索引。假設您想要在具有資料的堆表上建立叢集索引。作為第一步,如圖2-5所示,SQL Server建立了資料的另一個副本,然後根據叢集金鑰的值對其進行排序。資料頁連結在雙鏈接列表中,其中每個頁都包含指向鏈中的下一頁和前一頁的指標。這個列表稱為索引的葉子級別,它包含實際的表資料。
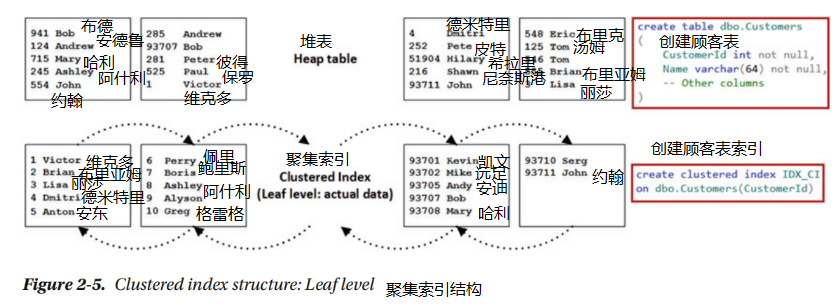
注意,頁面上的排序順序由插槽陣列控制。頁面上的實際資料沒有排序。
當葉子層包含多個頁面時,SQL Server開始構建索引的中間層,如圖2-6所示。

中間級儲存每個葉級頁的一行。它儲存兩段資訊:實體地址和它引用的頁面中的索引鍵的最小值。唯一的例外是第一頁的第一行,其中SQL Server儲存空值而不是最小索引鍵值。通過這種優化,當在表中插入具有最低鍵值的行時,SQL Server不需要更新非葉級行。中間層次的頁面也連結到雙鏈表。SQL Server添加了越來越多的中間級別,直到有一個僅包含單個頁面的級別。這個級別稱為根級別,並且它成為索引的入口點,如圖2-7所示。
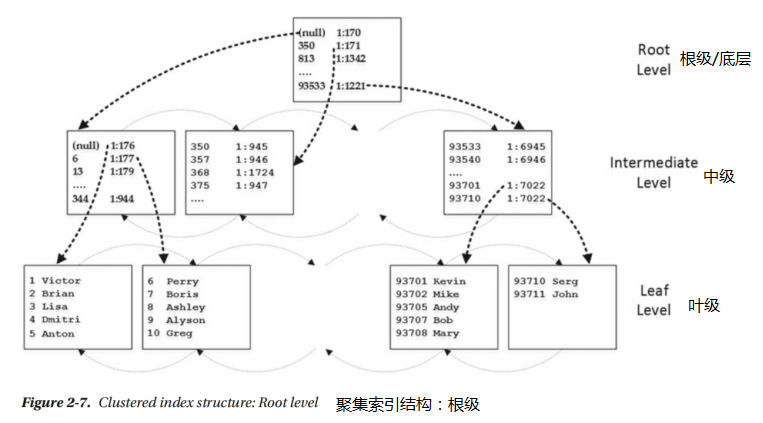
如您所見,索引總是具有一個葉子級別、一個根級別和零個或多箇中間級別。唯一的例外是當索引資料適合單個頁面時。在這種情況下,SQL Server不建立單獨的根級頁面,而索引僅由單個葉級頁面組成。索引中的級別數量很大程度上取決於行和索引鍵的大小。例如,4位元組整數列上的索引在中間級別和根級別上每行需要13個位元組。這13個位元組由一個2位元組的時隙陣列條目、一個4位元組的索引鍵值、一個6位元組的頁指標和一個1位元組的行開銷組成,這足夠了,因為索引鍵不包含可變長度和空列。
因此,您可以容納每行8060位元組/13位元組=每頁620行。這意味著,使用一箇中間級別,可以儲存最多620*620=384400個葉級頁面的資訊。如果資料行大小是200位元組,那麼可以在索引中儲存每頁40行,最多15376000行,只有三個級別。向索引中新增另一箇中間級別將基本上覆蓋所有可能的整數值。
注意,在實際生活中,索引碎片會減少這些數字。我們將在第6章中討論索引碎片。
SQL Server可以以三種不同的方式從索引讀取資料。第一個是通過有序掃描。假設我們要執行SELECT Name from dbo.Customers ORDER BY.CustomerId query。索引的葉級資料已經基於CustomerId列值進行了排序。因此,SQL Server可以掃描索引從第一頁到最後一頁的葉子級別,並按照儲存行的順序返回行。
SQL Server從索引的根頁開始,然後從那裡讀取第一行。該行引用表中具有最小鍵值的中間頁。SQL Server讀取該頁面,並重復該過程,直到在葉級找到第一個頁面。然後,SQL Server開始逐行讀取,遍歷頁面的連結列表,直到所有行都被讀取。圖2-8說明了這個過程。
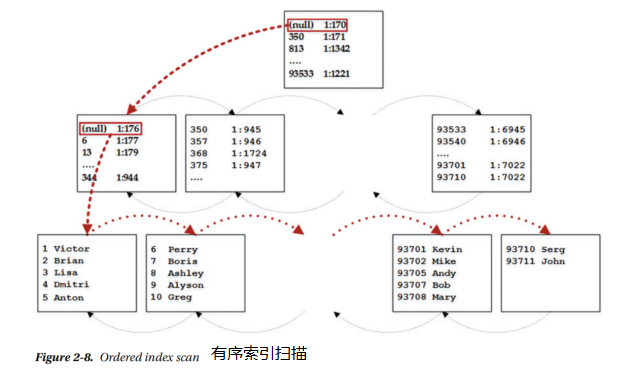
前面查詢的執行計劃顯示了叢集索引掃描操作符,Ordered屬性設定為true,如圖2-9所示。

值得一提的是,觸發有序掃描不需要order by子句。有序掃描僅僅意味著SQL Server根據索引鍵的順序讀取資料。
SQL Server可以在兩個方向上(向前和向後)瀏覽索引。但是,您必須記住一個重要方面:SQL Server在反向索引掃描期間不使用並行性.
提示您可以通過檢查執行計劃中的索引掃描或索引查詢操作符屬性來檢查掃描方向。但是,請記住,企業管理器並不在執行計劃的圖形表示中顯示這些屬性。您需要在執行計劃中選擇操作符並選擇檢視 /屬性視窗選單項或通過按F4鍵。企業版的SQL Server有一個稱為旋轉掃描的優化特性,允許多個任務共享相同的索引掃描。假設您有會話S1,它正在掃描索引。在掃描中間的某個時刻,另一個會話S2執行需要掃描相同索引的查詢。通過旋轉木馬掃描,S2在其當前掃描位置連線S1。SQLServer只讀取每個頁面一次,將行傳遞給兩個會話。
當S1掃描到達索引的結束時,S2從索引的開始開始掃描資料,直到S2掃描開始的點。旋轉木馬掃描是另一個示例,它說明了為什麼您不能依賴於索引鍵的順序,以及為什麼在需要時應該始終指定ORDER BY子句。
排序掃描之後的下一個訪問方法稱為分配順序掃描。SQL Server通過IAM頁面訪問表資料,類似於使用堆表的方式。來自dbo.Customers WITH(NOLOCK)查詢的SELECT Name和圖2-10說明了這種方法。圖2-11顯示了查詢執行計劃。
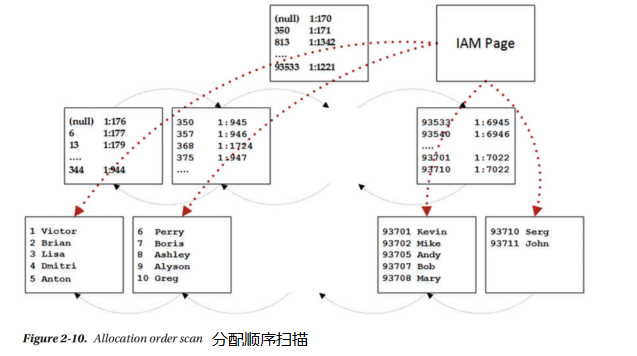
不幸的是,很難檢測SQL Server何時使用分配順序掃描。儘管執行計劃中的Ordered屬性顯示為false,但它表明SQL Server並不關心行是否按索引鍵的順序讀取,而不關心使用分配順序掃描。
分配順序掃描可以更快地掃描大表,儘管它的啟動成本較高。當表小時,SQLServer不使用此訪問方法。另一個重要的考慮因素是資料一致性。SQL Server在具有叢集索引的表中不使用轉發指標,並且分配順序掃描可能產生不一致的結果。由於分頁導致的資料移動,可以多次跳過或讀取行。因此,SQLServer通常避免使用分配順序掃描。除非它以未提交讀取或可序列化的事務隔離級別讀取資料。
注意:我們將在第6章“索引分段”中討論分頁和分段,在第三部分“鎖定、阻塞和併發”中討論鎖定和資料一致性。
最後一個索引訪問方法稱為索引查詢。從dbo.CustomersWhhereCustomerId BETWEEN 4.7查詢中的SELECT Name,圖2-12說明了該操作

為了從表中讀取行的範圍,SQL Server需要從範圍中找到具有最小鍵值的行,即SQL Server從根頁面開始,其中第二行引用具有最小鍵值350的頁面。它大於我們正在尋找的鍵值(4),並且SQL Server讀取由根頁面上的第一行引用的中間級資料頁(1:170)。
類似地,中間頁面將SQL Server引導到第一個葉級頁面(1:176)。SQL Server讀取該頁,然後讀取CustomerIds等於4和5的行,最後,從第二頁讀取剩餘的兩行。
執行計劃如圖2-13所示。

可以猜到,索引查詢比索引掃描更有效,因為SQL Server只處理行和資料頁的子集,而不掃描整個表。
從技術上講,有兩種索引查詢操作。第一個稱為單例查詢,有時稱為點查詢,其中SQL Server查詢並返回單行。您可以想到Cuffer-Id= 2謂詞在哪裡。另一種型別的索引查詢操作稱為範圍掃描,它要求SQL Server查詢鍵的最低值或最高值,並掃描(向前或向後)行集合,直到到達掃描範圍的末尾。客戶機介於4和7之間的謂詞到範圍掃描。兩種情況都顯示為執行計劃中的索引查詢操作。
正如您所猜到的,範圍掃描完全可能迫使SQL Server處理索引中的大量資料頁甚至所有資料頁。例如,如果將查詢更改為使用WHERE CustomerId>0謂詞,SQL Server將讀取所有行/頁,儘管在執行計劃中將顯示Index Seek操作符。您必須牢記這種行為,並在查詢效能優化期間始終分析範圍掃描的效率。
在關係資料庫中有一個稱為SARGable謂詞的概念,它代表可搜尋引數。如果SQL Server可以利用索引查詢操作(如果存在索引),則謂詞是SARGable。簡言之,當SQL Server可以隔離要處理的索引鍵值的單個值或範圍時,謂詞就是SARGable,從而限制了謂詞評估期間的搜尋。顯然,寫作是有益的。使用sgabess謂詞進行查詢,並儘可能使用索引查詢。
SARGable謂詞包括下列操作符:=、>、>=、<、<=、IN、BETWEEN和LIKE(在字首匹配的情況下)。非SARGable操作符包括NOT、<>、LIKE(在非字首匹配的情況下)和NOT IN。
使謂詞不可SARGable的另一種情況是對錶列使用函式或數學計算。SQL Server必須呼叫該函式或對其處理的每行執行計算。幸運的是,在某些情況下,您可以重構查詢以使得這樣的謂詞SARGable。表2-1顯示了一些例子。

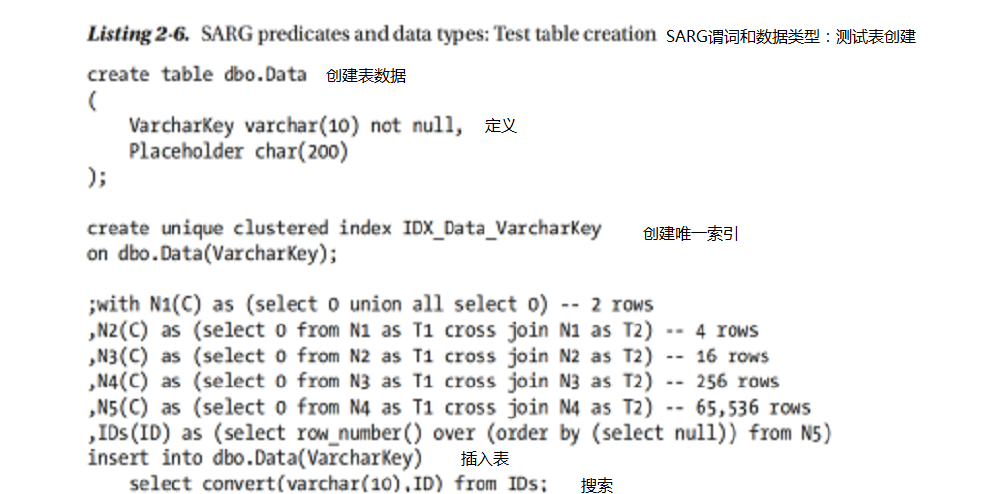
您必須牢記的另一個重要因素是型別轉換。 在某些情況下,您可以使用不正確的資料型別使謂詞非SARGable。 讓我們建立一個帶有varchar列的表,並用一些資料填充它,如清單2-6所示。

聚簇索引鍵列定義為varchar,即使它儲存整數值。 現在,讓我們執行兩個選擇,如清單2-7所示,並檢視執行計劃
如圖2-14所示,對於整數引數,SQL Server掃描聚簇索引,將varchar轉換為每行的整數。 在第二種情況下,SQL Server在開始時將整數引數轉換為varchar,並使用更高效的聚簇索引查詢操作。

提示請注意連線謂詞中的列資料型別。 隱式或顯式資料型別轉換可能會顯著降低查詢的效能。
在unicode字串引數的情況下,您將觀察到非常類似的行為。 讓我們執行清單2-8中所示的查詢。 圖2-15顯示了語句的執行計劃
清單2-8 SARG謂詞和資料型別:使用字串引數選擇。

圖2-15。 SARG謂詞和資料型別:帶字串引數的執行計劃
如您所見,對於varchar列,unicode字串引數是非SARGable。 這是一個比看起來更大的問題。 雖然您很少以這種方式編寫查詢,如清單2-8所示,但現在大多數應用程式開發環境都將字串視為unicode。 因此,除非引數資料,否則SQL Server客戶端庫會為字串物件生成unicode(nvarchar)引數type顯式指定為varchar。 這使得謂詞不具有SARG,並且由於不必要的掃描,它可能導致主要的效能命中,即使對varchar列進行索引也是如此。
)。Value=stringVariable而不是Parameters.Add(\"@ParamName\")。Value=stringVariable過載。在ORM框架中使用對映來顯式地指定類中的非Unicode屬性。" >重要的是始終在客戶端應用程式中指定引數資料型別。例如,在ADO.Net中,使用Parameters.Add("@ParamName)、SqlDbType.Varchar、<Size>)。Value=stringVariable而不是Parameters.Add("@ParamName")。Value=stringVariable過載。在ORM框架中使用對映來顯式地指定類中的非Unicode屬性。
還值得一提的是,VARCHAR引數對於NVARCHAR Unicode資料列是可處理的
綜合指數
具有多個鍵列的索引稱為複合(或複合)索引。複合索引中的資料按每列從最左到最右的列進行排序。圖2-16顯示了複合索引的結構。