
【任務排程系統第一篇】:大資料任務排程框架
阿新 • • 發佈:2018-12-04
1.前言
任務排程系統在大資料平臺架構中扮演著比較重要的角色。下圖是引自網易的猛獁大資料平臺lambda架構圖。
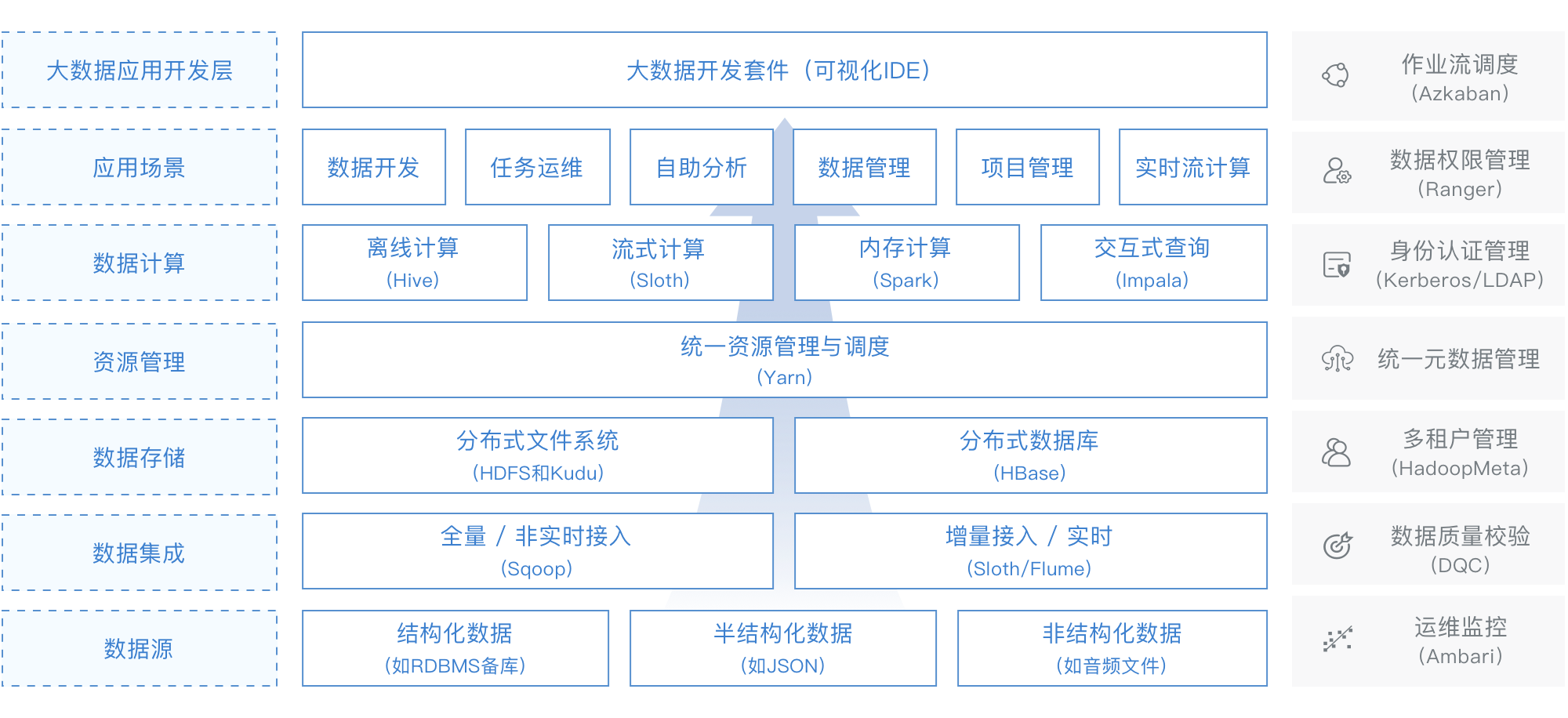
其中的Azkaban就是其任務排程元件。概括來說,任務排程在大資料平臺中所扮演的角色主要有:
-
任務編排:對任務流按照一定的邏輯串起來。這在大資料開發中,顯得比較重要,對於一個工作任務,可能有不同的子任務串起來的,並且有些子任務是並行執行的。舉個例子,在做一個機器學習的模型時,可能第一步就是資料清洗,然後是提取特徵,接著才是模型預測。然後提取特徵的過程中,可能要分為提取屬性特徵和行為特徵。那麼這裡用拓撲圖可以表示為如下圖:
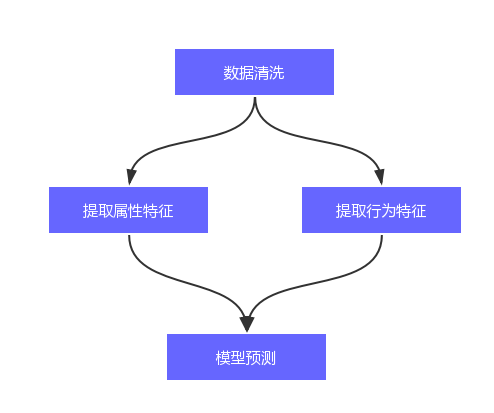
-
任務排程執行
:任務排程元件的核心使命肯定是讓離線任務按照我們既定的執行計劃去週期排程地執行。那麼任務排程系統就需要能夠按照任務的排程計劃去自動執行任務。 -
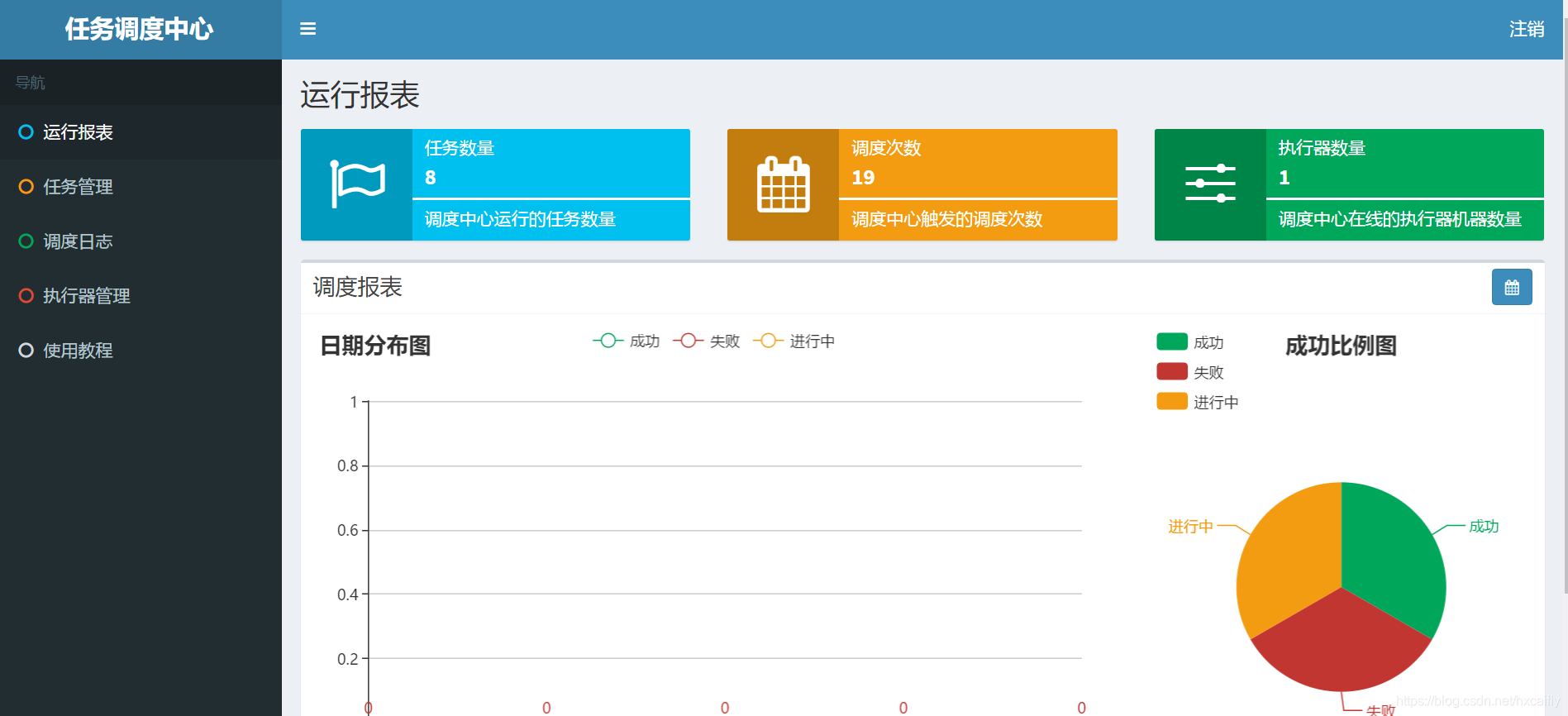
運維功能:作為一個系統肯定要有健全的運維功能,比如說提供任務執行報表功能,排程日誌等等。類似於下圖:
2.目前主流的任務排程系統
目前主流的任務排程框架有:
- xxl job: XXL-JOB 是一個輕量級分散式任務排程框架,支援通過 Web 頁面對任務進行 CRUD 操作,支援動態修改任務狀態、暫停/恢復任務,以及終止執行中任務,支援線上配置排程任務入參和線上檢視排程結果。其官網: http://www.xuxueli.com/xxl-job/#/
- Azkaban:Azkaban是由Linkedin公司推出的一個批量工作流任務排程器,主要用於在一個工作流內以一個特定的順序執行一組工作和流程。官網:https://azkaban.github.io/
- elastic Job:Elastic-Job 是一個分散式排程解決方案,由兩個相互獨立的子專案 Elastic-Job-Lite 和 Elastic-Job-Cloud 組成。定位為輕量級無中心化解決方案,使用 jar 包的形式提供分散式任務的協調服務。支援分散式排程協調、彈性擴容縮容、失效轉移、錯過執行作業重觸發、並行排程、自診斷和修復等等功能特性。官網:http://elasticjob.io/
- Apache Oozie:Oozie 是一個工作流排程系統,用來管理 Hadoop 任務。官網:http://oozie.apache.org/
以上只列舉四種吧。對於這些排程框架,雖然基本原理相似,但是在細節功能點上各有千秋。因為筆者在實際開發中,有幸接觸了xxl job和azkaban。所以本專欄也主要介紹和分析這兩個框架。
3. azkaban和xxl job的異同點
不同點:
- azkaban的最大亮點是任務的編排,類似阿里雲的odps裡的任務流開發,感覺是基於azkaban的。可以把一個大任務拆分成不同的子任務,然後按照一定的邏輯編排起來。但是xxl job基本上沒有任務編排功能,僅僅是支援某個任務可以設定他的子任務,這其實靈活性就沒有那麼強。
- xxl job的分散式效能要比azkaban好。xxl job在設計的時候就考慮了高可用性(HA),採用了執行器和排程中心分離的方式。執行器可以分別部署在不同的機器上,他們之間通過資料庫維護著彼此的心跳。然後排程中心是分別部署在不同的機器上,執行器都分別向各個存活著的排程中心註冊。但是azkaban的高可用性相比於xxl job就要差點,其僅僅保證了執行器的HA效能,排程中心不支援。當排程中心掛掉之後,使用者就不能提交任務了,但是已經提交了的任務的正常排程還是可以繼續。
- 從原始碼級別看,xxl job更輕量級。其採用spring boot, Mybatis的主體框架,程式碼量相比於azkaban少了好多。azkaban的程式碼很少用框架,連MVC, 資料庫ORM等都是在程式碼裡自己實現,所以程式碼量較多。不過筆者的建議是,多讀讀azkaban的原始碼,對提高java的能力更有幫助。不過出於維護,xxl job肯定更好,可以減少很多維護成本。
- Web UI不同。xxl job的Web UI 基本上很完善,可以開箱即用。在web介面上可以線上開發任務。但是azkaban的Web介面就比較簡單,需要我們線下自己壓縮好任務包,通過介面上傳任務。所以對於產品化來說,xxl job的成本更低。
相同點:
- 其底層的任務排程外掛都是依賴於quartz。這點也然我認識到quartz應該是通用的排程外掛。
- 都是採用排程排程中心和執行器分離的方式。其中執行器的高可用性原理是一樣的。都是各個執行器節點每隔一點時間間隔(比如5s)向共同依賴的資料庫寫如心跳,然後彼此通過心跳來感知對方是否存活。
後記
本專題後續的文章也主要是圍繞這兩個框架來展開,希望對他們的原理和用法做一番剖析。