
用簡單程式碼看卷積組塊發展
摘要: 在本文中,我想帶領大家看一看最近在Keras中實現的體系結構中一系列重要的卷積組塊。
作為一名電腦科學家,我經常在翻閱科學技術資料或者公式的數學符號時碰壁。我發現通過簡單的程式碼來理解要容易得多。因此,在本文中,我想帶領大家看一看最近在Keras中實現的體系結構中一系列重要的卷積組塊。
當你在GitHub網站上尋找常用架構實現時,一定會對它們裡面的程式碼量感到驚訝。如果標有足夠多的註釋並使用額外的引數來改善模型,將會是一個非常好的做法,但與此同時這也會分散體系結構的本質。為了進一步簡化和縮短程式碼,我將使用一些別名函式:
defconv(x, f, k=3, s=1, p='same', d=1, a='relu'): return Conv2D(filters=f, kernel_size=k, strides=s, padding=p, dilation_rate=d, activation=a)(x) def dense(x, f, a='relu'): return Dense(f, activation=a)(x) defmaxpool(x, k=2, s=2, p='same'): return MaxPooling2D(pool_size=k, strides=s, padding=p)(x) defavgpool(x, k=2, s=2, p='same'): return AveragePooling2D(pool_size=k, strides=s, padding=p)(x) defgavgpool(x): return GlobalAveragePooling2D()(x) defsepconv(x, f, k=3, s=1, p='same', d=1, a='relu'): return SeparableConv2D(filters=f, kernel_size=k, strides=s, padding=p, dilation_rate=d, activation=a)(x)
在刪除模板程式碼之後的程式碼更易讀。當然,這隻有在你理解我的首字母縮寫後才有效。
defconv(x, f, k=3, s=1, p='same', d=1, a='relu'): return Conv2D(filters=f, kernel_size=k, strides=s, padding=p, dilation_rate=d, activation=a)(x) def dense(x, f, a='relu'): return Dense(f, activation=a)(x) defmaxpool(x, k=2, s=2, p='same'): return MaxPooling2D(pool_size=k, strides=s, padding=p)(x) defavgpool(x, k=2, s=2, p='same'): return AveragePooling2D(pool_size=k, strides=s, padding=p)(x) defgavgpool(x): return GlobalAveragePooling2D()(x) defsepconv(x, f, k=3, s=1, p='same', d=1, a='relu'): return SeparableConv2D(filters=f, kernel_size=k, strides=s, padding=p, dilation_rate=d, activation=a)(x)
瓶頸(Bottleneck)組塊
一個卷積層的引數數量取決於卷積核的大小、輸入過濾器的數量和輸出過濾器的數量。你的網路越寬,3x3卷積耗費的成本就越大。
def bottleneck(x, f=32, r=4):
x = conv(x, f//r, k=1)
x = conv(x, f//r, k=3)
return conv(x, f, k=1)瓶頸組塊背後的思想是,使用一個低成本的1x1卷積,按照一定比率r將通道的數量降低,以便隨後的3x3卷積具有更少的引數。最後,我們用另外一個1x1的卷積來拓寬網路。
Inception模組
模組提出了通過並行的方式使用不同的操作並且合併結果的思想。通過這種方式網路可以學習不同型別的過濾器。
defnaive_inception_module(x, f=32):
a = conv(x, f, k=1)
b = conv(x, f, k=3)
c = conv(x, f, k=5)
d = maxpool(x, k=3, s=1)
return concatenate([a, b, c, d])在這裡,我們將使用卷積核大小分別為1、3和5的卷積層與一個MaxPooling層進行合併。這段程式碼顯示了Inception模組的原始實現。實際的實現結合了上述的瓶頸組塊思想,這使它稍微的複雜了一些。
definception_module(x, f=32, r=4):
a = conv(x, f, k=1)
b = conv(x, f//3, k=1)
b = conv(b, f, k=3)
c = conv(x, f//r, k=1)
c = conv(c, f, k=5)
d = maxpool(x, k=3, s=1)
d = conv(d, f, k=1)
return concatenate([a, b, c, d])Inception模組
剩餘組塊(ResNet)
ResNet是由微軟的研究人員提出的一種體系結構,它允許神經網路具有任意多的層數,同時還提高了模型的準確度。現在你可能已經習慣使用它了,但在ResNet之前,情況並非如此。
defresidual_block(x, f=32, r=4):
m = conv(x, f//r, k=1)
m = conv(m, f//r, k=3)
m = conv(m, f, k=1)
return add([x, m])
ResNet的思路是將初始的啟用新增到卷積組塊的輸出結果中。利用這種方式,網路可以通過學習過程決定用於輸出的新卷積的數量。值得注意的是,Inception模組連線這些輸出,而剩餘組塊是用於求和。
ResNeXt組塊
根據它的名稱,你可以猜到ResNeXt與ResNet是密切相關的。作者們將術語“基數(cardinality)”引入到卷積組塊中,作為另一個維度,如寬度(通道數量)和深度(網路層數)。
基數是指在組塊中出現的並行路徑的數量。這聽起來類似於以並行的方式出現的4個操作為特徵的Inception模組。然而,基數4不是指的是並行使用不同型別的操作,而是簡單地使用相同的操作4次。
它們做的是同樣的事情,那麼為什麼你還要把它們並行放在一起呢?這個問題問得好。這個概念也被稱為分組卷積,可以追溯到最早的AlexNet論文。儘管當時它主要用於將訓練過程劃分到多個GPU上,而ResNeXt則使用ResNeXt來提高參數的效率。
defresnext_block(x, f=32, r=2, c=4):
l = []
for i in range(c):
m = conv(x, f//(c*r), k=1)
m = conv(m, f//(c*r), k=3)
m = conv(m, f, k=1)
l.append(m)
m = add(l)
return add([x, m])這個想法是把所有的輸入通道分成一些組。卷積將只會在其專用的通道組內進行操作,而不會影響其它的。結果發現,每組在提高權重效率的同時,將會學習不同型別的特徵。
想象一個瓶頸組塊,它首先使用一個為4的壓縮率將256個輸入通道減少到64個,然後將它們再恢復到256個通道作為輸出。如果想引入為32的基數和2的壓縮率,那麼我們將使用並行的32個1x1的卷積層,並且每個卷積層的輸出通道是4(256/(32*2))個。隨後,我們將使用32個具有4個輸出通道的3x3的卷積層,然後是32個1x1的卷積層,每個層則有256個輸出通道。最後一步包括新增這32條並行路徑,在為了建立剩餘連線而新增初始輸入之前,這些路徑會為我們提供一個輸出。
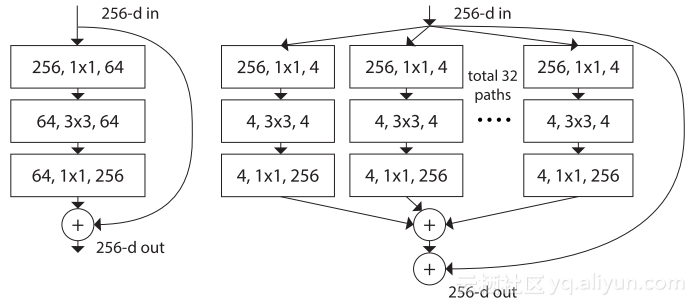
左側: ResNet組塊 右側: 引數複雜度大致相同的RexNeXt組塊
這有不少的東西需要消化。用上圖可以非常直觀地瞭解都發生了什麼,並且可以通過複製這些程式碼在Keras中自己建立一個小型網路。利用上面9行簡單的程式碼可以概括出這些複雜的描述,這難道不是很好嗎?
順便提一下,如果基數與通道的數量相同,我們就會得到一個叫做深度可分卷積(depthwise separable convolution)的東西。自從引入了Xception體系結構以來,這些技術得到了廣泛的應用。
密集(Dense)組塊
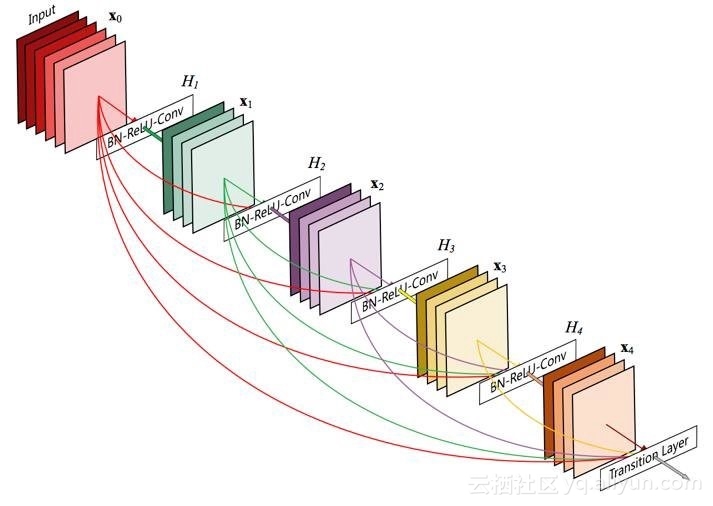
密集組塊是剩餘組塊的極端版本,其中每個卷積層獲得組塊中之前所有卷積層的輸出。我們將輸入啟用新增到一個列表中,然後輸入一個可以遍歷塊深度的迴圈。每個卷積輸出還會連線到這個列表,以便後續迭代獲得越來越多的輸入特徵對映。這個方案直到達到了所需要的深度才會停止。
defdense_block(x, f=32, d=5):
l = x
for i in range(d):
x = conv(l, f)
l = concatenate([l, x])
return l儘管需要數月的研究才能得到一個像DenseNet這樣出色的體系結構,但是實際的構建組塊其實就這麼簡單。
SENet(Squeeze-and-Excitation)組塊
SENet曾經在短期內代表著ImageNet的較高水平。它是建立在ResNext的基礎之上的,主要針對網路通道資訊的建模。在常規的卷積層中,每個通道對於點積計算中的加法操作具有相同的權重。
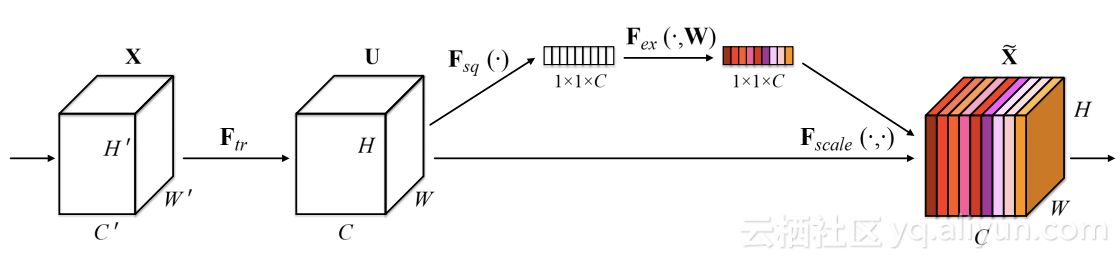
Squeezeand Excitation組塊
SENet引入了一個非常簡單的模組,可以新增到任何現有的體系結構中。它建立了一個微型神經網路,學習如何根據輸入對每個過濾器進行加權。正如你看到的那樣,SENet本身不是一個卷積組塊,但是因為它可以被新增到任何卷積組塊中,並且可能會提高它的效能,因此我想將它新增到混合體中。
defse_block(x, f, rate=16):
m = gavgpool(x)
m = dense(m, f // rate)
m = dense(m, f, a='sigmoid')
return multiply([x, m])每個通道被壓縮為一個單值,並被饋送到一個兩層的神經網路裡。根據通道的分佈情況,這個網路將根據通道的重要性來學習對其進行加權。最後,再用這個權重跟卷積啟用相乘。
SENets只用了很小的計算開銷,同時還可能會改進卷積模型。在我看來,這個組塊並沒有得到應有的重視。
NASNet標準單元
這就是事情變得醜陋的地方。我們正在遠離人們提出的簡捷而有效的設計決策的空間,並進入了一個設計神經網路體系結構的演算法世界。NASNet在設計理念上是令人難以置信的,但實際的體系結構是比較複雜的。我們所瞭解的是,它在ImageNet上表現的很優秀。
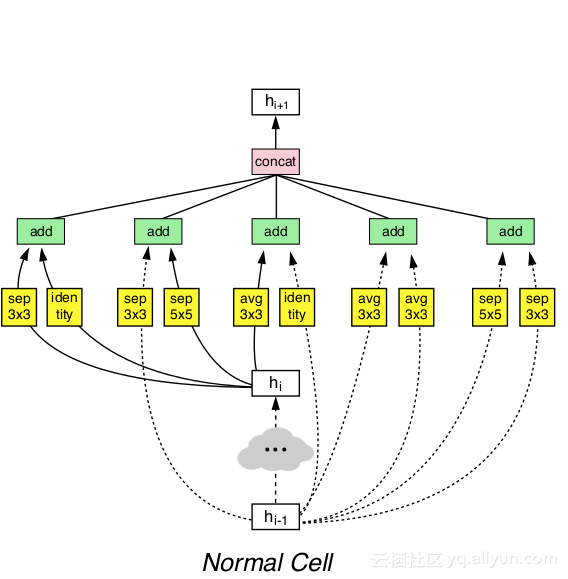
通過人工操作,作者們定義了一個不同型別的卷積層和池化層的搜尋空間,每個層都具有不同的可能性設定。他們還定義瞭如何以並行的方式、順序地排列這些層,以及這些層是如何被新增的或連線的。一旦定義完成,他們會建立一個基於遞迴神經網路的強化學習(Reinforcement Learning,RL)演算法,如果一個特定的設計方案在CIFAR-10資料集上表現良好,就會得到相應的獎勵。
最終的體系結構不僅在CIFAR-10上表現良好,而且在ImageNet上也獲得了相當不錯的結果。NASNet是由一個標準單元(Normal Cell)和一個依次重複的還原單元(Reduction Cell)組成。
defnormal_cell(x1, x2, f=32):
a1 = sepconv(x1, f, k=3)
a2 = sepconv(x1, f, k=5)
a = add([a1, a2])
b1 = avgpool(x1, k=3, s=1)
b2 = avgpool(x1, k=3, s=1)
b = add([b1, b2])
c2 = avgpool(x2, k=3, s=1)
c = add([x1, c2])
d1 = sepconv(x2, f, k=5)
d2 = sepconv(x1, f, k=3)
d = add([d1, d2])
e2 = sepconv(x2, f, k=3)
e = add([x2, e2])
return concatenate([a, b, c, d, e])這就是如何在Keras中實現一個標準單元的方法。除了這些層和設定結合的非常有效之外,就沒有什麼新的東西了。
倒置剩餘(Inverted Residual)組塊
到現在為止,你已經瞭解了瓶頸組塊和可分離卷積。現在就把它們放在一起。如果你做一些測試,就會注意到,因為可分離卷積已經減少了引數的數量,因此進行壓縮可能會損害效能,而不是提高效能。
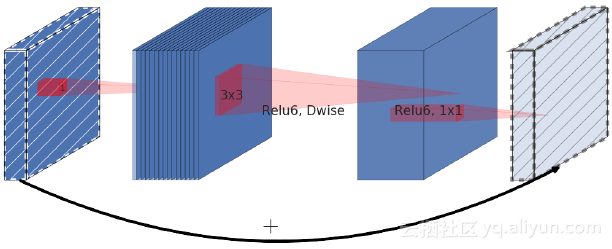
作者們提出了與瓶頸組塊和剩餘組塊相反的想法。他們使用低成本的1x1卷積來增加通道的數量,因為隨後的可分離卷積層已經大大減少了引數的數量。在把通道新增到初始啟用之前,降低了通道的數量。
definv_residual_block(x, f=32, r=4):
m = conv(x, f*r, k=1)
m = sepconv(m, f, a='linear')
return add([m, x])問題的最後一部分是在可分離卷積之後沒有啟用函式。相反,它直接被新增到了輸入中。這個組塊被證明當被放到一個體繫結構中的時候是非常有效的。
AmoebaNet標準單元
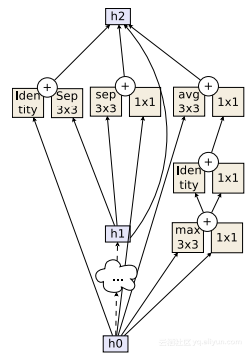
AmoebaNet的標準單元
利用AmoebaNet,我們在ImageNet上達到了當前的最高水平,並且有可能在一般的影象識別中也是如此。與NASNet類似,AmoebaNet是通過使用與前面相同的搜尋空間的演算法設計的。唯一的糾結是,他們放棄了強化學習演算法,而是採用了通常被稱為“進化”的遺傳演算法。但是,深入瞭解其工作方式的細節超出了本文的範疇。故事的結局是,通過進化,作者們能夠找到一個比NASNet的計算成本更低的更好的解決方案。這在ImageNet-A上獲得了名列前五的97.87%的準確率,也是第一次針對單個體繫結構的。
結論
我希望本文能讓你對這些比較重要的卷積組塊有一個深刻的理解,並且能夠認識到實現起來可能比想象的要容易。要進一步瞭解這些體系結構,請檢視相關的論文。你會發現,一旦掌握了一篇論文的核心思想,就會更容易理解其餘的部分了。另外,在實際的實現過程中通常將批量規範化新增到混合層中,並且隨著啟用函式應用的的地方會有所變化。