
Hadoop-2.5.1安裝步驟
目標
在vmware14.1.1中的三個虛擬機器上安裝hadoop 2.5.1 穩定版本。
由於hadoop 2.x.x 都是同一個系列,所以其他hadoop 2.x.x版本的安裝可以參照這篇步驟來做。
環境介紹
三臺vmware-14.1.1中的虛擬機器
作業系統:ubuntu 16.04 LTS
網路配置:
- vm-01 /etc/hosts檔案
127.0.0.1 localhost
#127.0.1.1 vm-01
# The following lines are desirable for IPv6 capable hosts - vm-02 /etc/hosts檔案
127.0.0.1 localhost
#127.0.1.1 vm-02
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#set cluster Ip
192.168.184.131 vm-01
#192.168.184.132 vm-02 - vm-03 /etc/hosts檔案
127.0.0.1 localhost
#127.0.1.1 vm-03
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#set cluster Ip
192.168.184.131 vm-01
192.168.184.132 vm-02
#192.168.184.133 vm-03
192.168.184.131 master
192.168.184.132 slave1
192.168.184.133 slave2
上面的三個hosts檔案中一定要注意第二行哪個127.0.0.1 vm-x的配置,一定要註釋掉,因為後面我們配置hadoop的一些配置檔案時會使用到主機名,如果不註釋掉那一行,hadoop則會依據主機名找到127.0.0.1這個ip地址,那麼最後就是會報錯的。
java配置:
三個虛擬機器器中java版本都是java version “1.8.0_181”,安裝路徑都是/opt/java,java的安裝步驟可以參看網上等相關資料,或者看自己的筆記,這裡就不再細講了。
使用者: hduser
使用者組: hadoop
下載hadoop
現在百度搜索"apache官網",進入到官網後,下載路徑是:
apache->project->Hadoop->頁面的Dowload按鈕,可以看到下面的頁面:
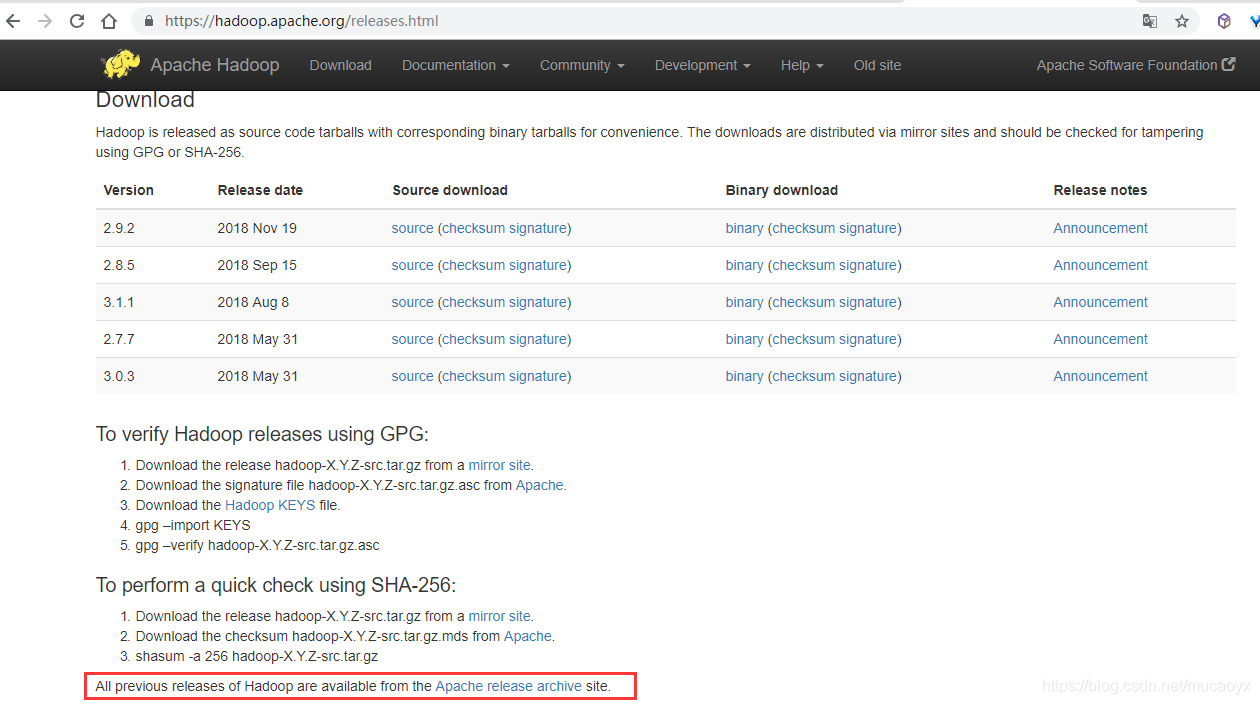
由於我們想安裝的是hadoop 2.5.1,在這個頁面的下載項中沒有這個版本,所以我們點選紅框中的那個連結在以前版本中找到hadoop 2.5.1。
點選之後進入到頁面https://archive.apache.org/dist/hadoop/common/
然後選擇hadoop 2.5.1 專案,進入到下載頁面https://archive.apache.org/dist/hadoop/common/hadoop-2.5.1/,頁面如下所示:
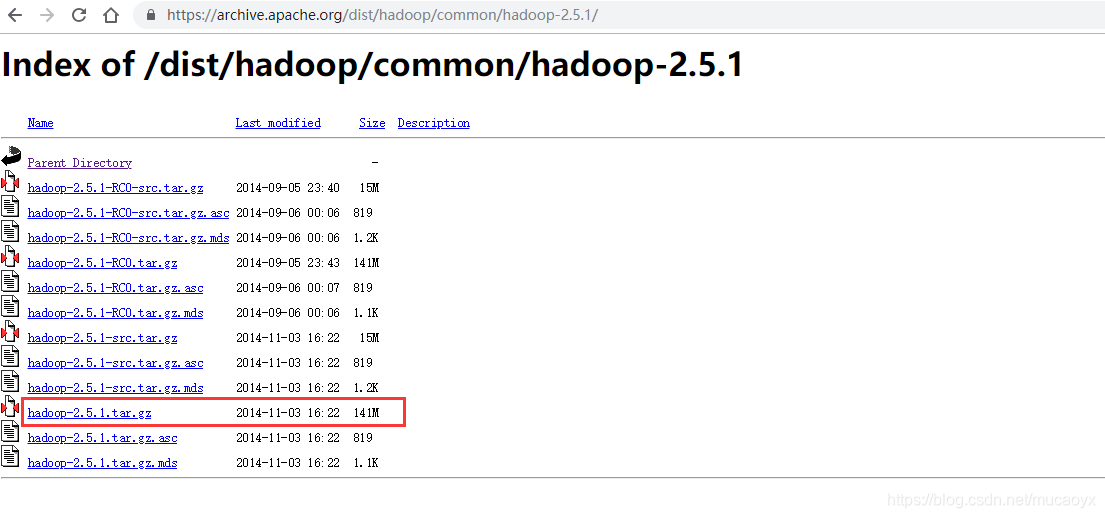
由於打算在ubuntu16.04中使用安裝包安裝,所以我們選擇hadoop-2.5.1.tar.gz檔案選項,接下來就是等著下載完成吧。如果想要對下載後的檔案進行驗證,那麼下載這個頁面中對應的校驗碼檔案進行驗證就可以了。
接下的操作主要是在主機vm-01上執行的。
解壓檔案並更改許可權
在/opt下建立資料夾hadoop
~$ mkdir /opt/hadoop
如果遇到許可權問題,那麼就在語句的前面加上sudo獲得超級許可權就好了。
然後對下載的hadoop-2.5.1.tar.gz檔案在/opt/hadoop下進行擠壓
/opt/hadoop$ tar -zxvf hadoop-2.5.1.tar.gz
將hadoop檔案的許可權賦給hduser使用者:
/opt/$ sudo chown -R hduser:hadoop hadoop/
新增tmp資料夾
因為HDFS預設把namenode的格式化資訊存在了系統的tmp目錄下,該目錄每次開機會被清空,因此每次重新啟動機器,都需要重新格式化HDFS。解決方案是配置一個新的tmp目錄給hadoop,這樣就無需每次重新格式化hdfs。
/opt/$ mkdir /opt/hadoop/hadoop-2.5.1/tmp
修改環境配置
在家目錄下的.bashrc檔案下配置環境變數:
~$ vim .bashrc
在底部增加下面的內容:
#set hadoop path
export HADOOP_HOME=/opt/hadoop/hadoop-2.5.1
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
修改hadoop配置
core-site.xml和hdfs-site.xml是站在HDFS角度上的配置檔案;core-site.xml和mapred-site.xml是站在MapReduce角度上的配置檔案
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/hadoop-env.sh
在文件鐘找到“export JAVA_HOME”,將其更改為:
export JAVA_HOME=/opt/java/jdk1.8.0_181 #自己java的home
配置core-site.xml
核心配置檔案,設定臨時目錄及配置的是HDFS的地址和埠號,注:須將下面配置中的value中ip修改為192.168.184.131,也就是master節點的IP地址。
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/core-site.xml
在標籤configuration中新增如下的內容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.5.1/tmp</value>
<description>A base for other temporary directories.</description>
<!-- file system properties -->
</property>
<property>
<name>fs.default.name</name>
<!-- 下面要配置成自己master節點的IP地址 -->
<value>hdfs://192.168.184.131:9000</value>
</property>
</configuration>
配置hdfs-site.xml
修改Hadoop中HDFS的配置,配置的備份方式預設為3,Salve少於3則會報錯
~$ vim /opt/hadoop/hadoop-2.5.1/etc/hadoop/hdfs-site.xml
配置檔案內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value><!-- 有幾個salve,這兒就配置成幾個 -->
</property>
</configuration>
配置mapred-site.xml
/opt/hadoop/hadoop-2.5.1/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml
新增下面的內容:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.184.131:9001</value>
</property>
</configuration>
配置salves檔案
由於是hadoop-2.5.1版本,所以不再需要配置master檔案,直接配置salves檔案
Master主機特有:
/opt/hadoop/hadoop-2.5.1/etc/hadoop$ vim salves
如果salves檔案裡面有localhost,記得一定要移除,然後再新增下面的內容:
192.168.184.132
192.168.184.133
目前是打算讓192.168.184.131當作master,其餘的192.168.184.132和192.168.184.133當作從節點。
配置Salve的hadoop,可以單機採用上述1-5;也可直接將master節點上的hadoop資料夾複製過去,salve機器上的slaves檔案是無需配置的,但無所謂。
分發hadoop檔案檔案到vm-02
/opt$ scp -r hadoop/ [email protected]:software/
由於vm-02上的/opt是root使用者所擁有,所以不能直接拷貝到vm-02的/opt下。先拷貝到vm-02的~/software,然後再進行移動到/opt/下。
ssh登入到slave機器vm-02上。如果沒有配置三臺機器的免密碼登陸,可以參看百度的“配置ssh免密碼登入”教程。這裡不再細說。
/opt$ ssh vm-02
在vm-02上配置環境:
~$ vim .bashrc
在底部加入:
#set hadoop path
export HADOOP_HOME=/opt/hadoop/hadoop-2.5.1
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
然後儲存並退出。
要想讓上面配置的環境生效,可以執行. ~/.bashrc或source ~/.bashrc命令,或者重新登陸終端。
啟動和驗證
啟動hadoop
(1) 格式化namenode
[email protected]:~/ hadoop namenode -format
(2)啟動
[email protected]:~/ start-all.sh
驗證是否啟動成功
使用jps命令來檢視相關程序是不是已經都啟動了。
master顯示:
[email protected]:~$ jps
98468 Jps
95757 ResourceManager
95420 NameNode
95615 SecondaryNameNode
slave顯示:
vm-02上:
[email protected]:~$ jps
32353 NodeManager
32535 Jps
32251 DataNode
vm-03上:
[email protected]:~$ jps
12338 DataNode
12698 Jps
12430 NodeManager
也可以執行命令檢視各個節點資訊:
hadoop dfsadmin -report
或者登入資訊網頁檢測:
http:192.168.184.131:50070
執行mapreduce示例程式(wordcount)
啟動hadoop叢集
[email protected]:~$ start-all.sh
建立hdfs目錄
[email protected]:~$ hadoop fs -mkdir /input
上傳檔案
hadoop fs -put pg132.txt /input/
[email protected]:~/tmp/$ hadoop fs -put pg132.txt /input/
檢視檔案
[email protected]:~/tmp/$ hadoop fs -ls /input
輸出資料夾為output,無需新建,若已存在需刪除
執行hadoop自帶例子
[email protected]:~/tmp/$ hadoop jar /opt/hadoop/hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /input/ /output/
檢視檔案輸出結果
[email protected]:~/tmp/$ hadoop fs -ls /output
檢視詞頻統計結果
[email protected]:~/tmp/$ hadoop fs -cat /output/part-r-00000
將hdfs上檔案匯出到本地
[email protected]:~/tmp/$ hadoop fs -get /output/part-r-00000 ./
總結
到這裡就完成在vmware14.1.1的三臺ubuntu 16.04 LTS 虛擬機器上對hadoop-2.5.1的搭建了。在搭建的過程中一定要慢一點,遇到問題一定要看看日誌資訊。