
Git學習04----底層數據結構
轉自:https://www.jianshu.com/p/8659c9ae00cb(含部分修改)
現在我們已經基本熟悉了GIT的基本操作了,接下來該執行研究一下GIT的幾個比較重要的組件,GIT有四個常用的組件
- Tag
- Commit
- Tree
- BLOB
最重要的是後面的三個,Tag組件在介紹了標簽之後再來說明。後三個組件管理著GIT的所有版本文件。
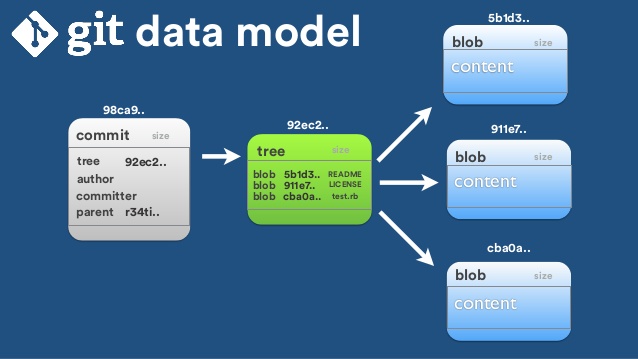 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
如圖所示:Commit組件包含了Tree,Tree組件中又有Blob組件,那麽組件究竟有什麽意義,又是以什麽的方式被應用了,通過具體的實例來說明,首先,初始化一個目錄為GIT的Repository,之後查看一下.git目錄
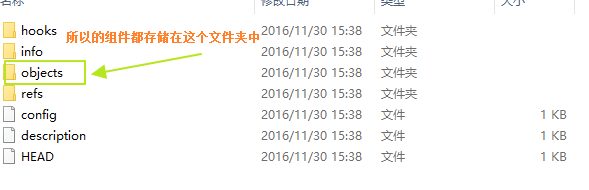 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
所有的組件都存儲在objects文件夾中,初始化之後只會有info和pack兩個文件夾,接著我們使用echo a > a.txt來創建一個文件,並且使用git add .將其提交給GIT的Stage,此時再看一下objects文件夾
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
此時多了一個f5的文件夾,裏面有一個文件名很長的文件,這個文件夾就是一個blob組件,當每次把文件設置為Staged狀態的時候,就會在objects中創建一個Blob組件,這裏需要強調一下,GIT中每個組件都是以hash的二進制方式來存儲,這個組件的名稱就是文件夾名稱+文件夾中的文件的名稱,這個hash碼是唯一的,我們剛才所創建的組件的hash碼就是f5eea678d87a8664e4c76e12d3ef5c4ff775ad58
blob組件並不會對文件信息進行存儲,而是對文件的內容進行記錄的(note:不同的文件a.txt,b.txt,但是文件的內容一致的化,那麽blob對象就是一致; 同一個文件a.txt,因為內容的修改不一樣,從而會生成新的blob對象),我們執行下一個操作,echo b > a.txt添加一個文件,我們把a.txt中的內容替換成b(原來是a),此時文件的狀態變成Modified狀態,再次通過git add .提交文件到Stage。
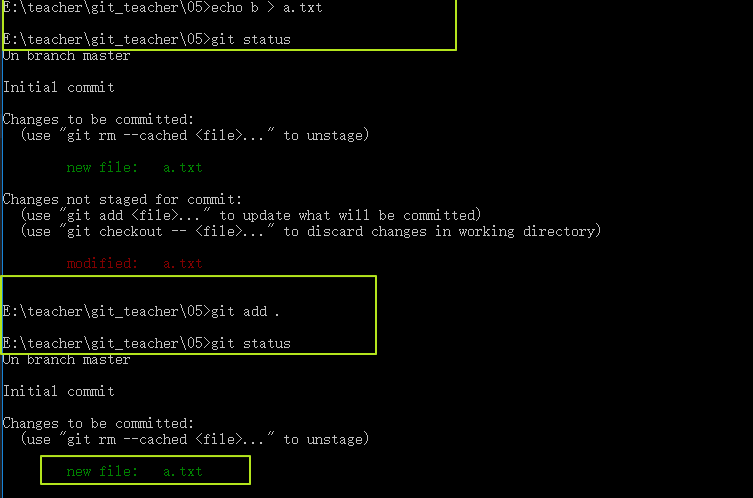 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
此時再觀察objects目錄
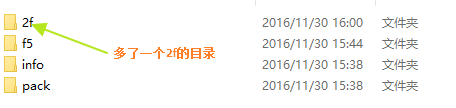 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
多了一個2f的目錄,雖然我們的文件沒有發生變化,但是內容發生了變化,此時git會再次創建一個blob組件存儲到objects文件夾中,我們再次執行下一個操作echo b > b.txt
git add .添加到Stage中
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
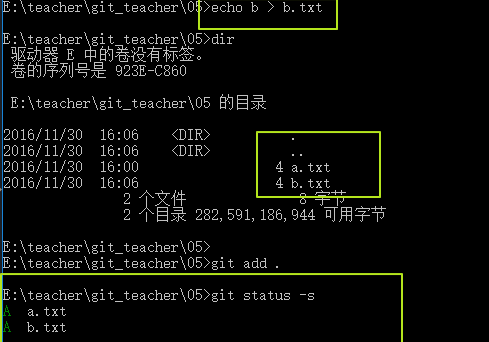
目前a.txt和b.txt都是屬於Staged狀態,此時再去objects文件夾中看一下。
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
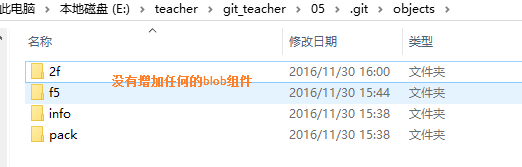
並沒有增加任何blob組件,因為b.txt的內容其實和a.txt一樣,所以git發現這個blob已經存在了,就不會再增加新的組件。
再次強調一下blob組件是在代碼提交到Stage區域的時候生成的,而且是以內容來生成一個字節碼文件
我們可以通過命令git hash-object 文件名查詢文件的hash碼
E:\teacher\git_teacher\05>git hash-object a.txt
2fea07c1b36b55a95b543c7bd0decbd6798bf9b9
E:\teacher\git_teacher\05>git hash-object b.txt
2fea07c1b36b55a95b543c7bd0decbd6798bf9b9
我們的a.txt和b.txt是完全一樣的名稱,這個hash碼就是我們的blob組件的名稱,再去對應一下文件夾和文件夾中的文件名。
了解了blob組件只會,我們執行下面一個操作,我們把Staged中的內容提交到工廠中,提交之前請觀察objects文件夾,執行git commit -m "init"之後。
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
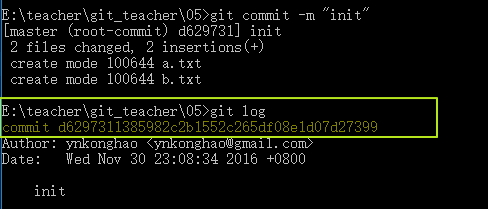
我們會發現多了兩個文件夾d6和f5,這兩個文件夾究竟是什麽呢(note:多的2個,一個是tree對象,一個是commit對象)?我們通過git log看一下
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
我們看到了一個commit d6297311385982c2b1552c265df08e1d07d27399,這就是我們即將要探討的commit組件了,而後面這串hash就是這個組件的id,在git中所有的組件都是以hash來存儲的,剛才講的blob也是一樣,而且都是以hash的前兩位為文件夾,剩余的位數作為文件名。
commit組件在每次提交之後都會生成,當我們進行commit之後,首先會創建一個commit組件,之後把所有的文件信息創建一個tree組件,然後把Stage Area中的blob組件封裝在tree中完成一次提交,我們可以通過如下命令查詢commit組件
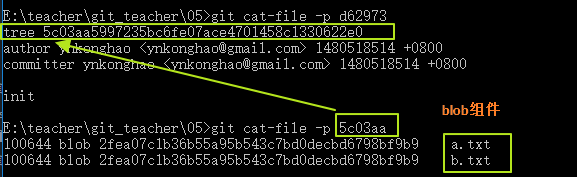
git cat-file -p d6297
cat-file可以獲取這個組件的信息d6297就是組件id的縮寫(只要寫前面的5位git會自動找到這個組件)
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
我們會發現commit組件下有一個tree組件,依然也是用hash來作為這個tree組件的名稱,之後cat-file一下這個tree組件,我們發現了最開始提交的兩個blob組件,而在tree組件中記錄了文件的基本信息。
現在我們應該明白git底層的運行流程了,當我們添加或者修改了文件並且add到Stage Area之後,首先會根據文件內容創建不同的blob,當進行提交之後馬上創建一個tree組件把需要的blob組件添加進去,之後再封裝到一個commit組件中完成本次提交。在將來進行reset的時候可以直接使用git reset --hard xxxxx可以恢復到某個特定的版本,在reset之後,git會根據這個commit組件的id快速的找到tree組件,然後根據tree找到blob組件,之後對倉庫進行還原,整個過程都是以hash和二進制進行操作,所以git執行效率非常之高。
最後我們再看一個例子,我們創建一個文件夾,然後再文件夾中創建一個文件,這裏希望大家跟著我的命令來思考,組件的創建情況。最後來進行驗證,看看我們是否真正掌握了git的組件
mkdir test
cd test
echo hello world >> b.txt
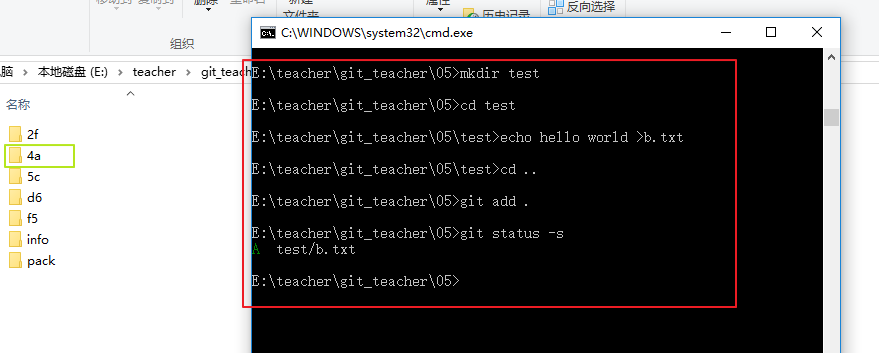
這三個命令之後,會創建一個test的文件夾,之後再創建一個b.txt的文件,並且加入hello world這個內容,我們進行提交之後,想想會創建些什麽組件?
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
由於b.txt的內容不一致,所以會創建一個blob組件,我這裏是以4a開頭的,之後進行提交
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
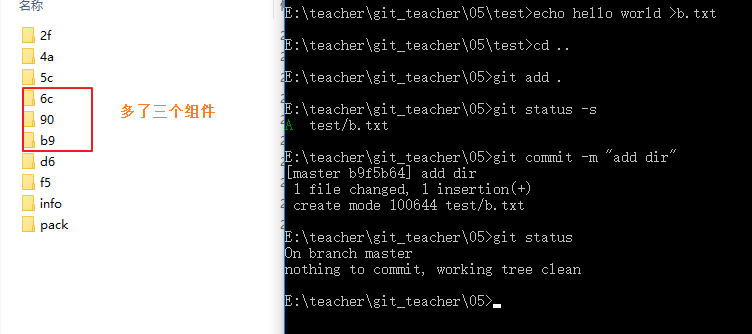
我們會發現多了三個組件,按道理來說應該只會創建一個commit組件,之後根據文件信息生成tree組件,最後把blob組件添加進去,應該只會多1個commit和1個tree,為什麽會有三個呢?我們通過cat-file來進行查詢
 GIT的BLOB、Commit和Tree組件的介紹
GIT的BLOB、Commit和Tree組件的介紹
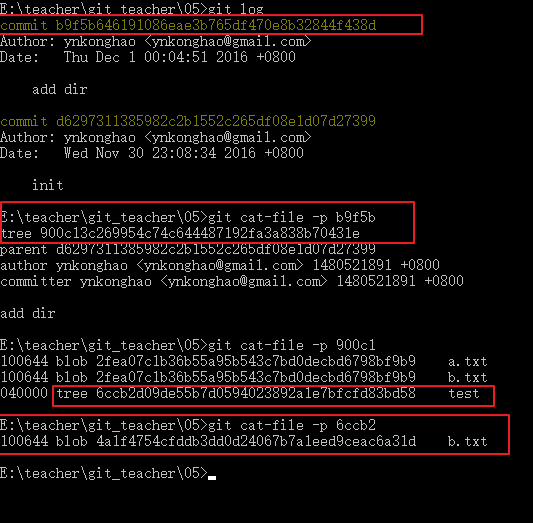
我們會發現首先生成了一個commit組件,這個commit中有一個tree,然後tree中處理a.txt和b.txt外還有一個tree組件,這個組件其實就是我們的文件夾,這個tree下面有新增加的b.txt的blob組件。所以我們如果新增加了一個文件夾,就會為這個文件夾創建一個tree組件。
我的總結:git add後會生成blob對象,然後執行git commit後,首先生成了commit對象,然後生成包含文件信息的tree對象,並將blob對象封裝在tree裏面一塊兒提交;blob對象只是針對內容進行新創建還是不新創建blob對象;而tree只要有新的文件創建,就會多個tree對象,只要commit,就會有個commit對象。
Git學習04----底層數據結構