
神經網路訓練中,傻傻分不清Epoch、Batch Size和迭代
你肯定經歷過這樣的時刻,看著電腦螢幕抓著頭,困惑著:「為什麼我會在程式碼中使用這三個術語,它們有什麼區別嗎?」因為它們看起來實在太相似了。
為了理解這些術語有什麼不同,你需要了解一些關於機器學習的術語,比如梯度下降,以幫助你理解。
這裡簡單總結梯度下降的含義…
梯度下降
這是一個在機器學習中用於尋找最佳結果(曲線的最小值)的迭代優化演算法。
梯度的含義是斜率或者斜坡的傾斜度。
下降的含義是代價函式的下降。
演算法是迭代的,意思是需要多次使用演算法獲取結果,以得到最優化結果。梯度下降的迭代性質能使欠擬合的圖示演化以獲得對資料的最佳擬合。
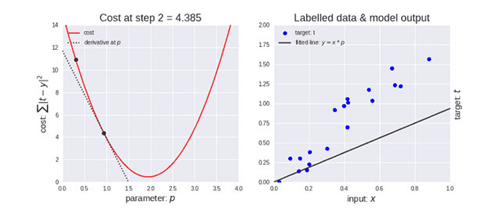
梯度下降中有一個稱為學習率的參量。如上圖左所示,剛開始學習率更大,因此下降步長更大。隨著點下降,學習率變得越來越小,從而下降步長也變小。同時,代價函式也在減小,或者說代價在減小,有時候也稱為損失函式或者損失,兩者都是一樣的。(損失/代價的減小是一件好事)
只有在資料很龐大的時候(在機器學習中,幾乎任何時候都是),我們才需要使用 epochs,batch size,迭代這些術語,在這種情況下,一次性將資料輸入計算機是不可能的。因此,為了解決這個問題,我們需要把資料分成小塊,一塊一塊的傳遞給計算機,在每一步的末端更新神經網路的權重,擬合給定的資料。
EPOCHS
當一個完整的資料集通過了神經網路一次並且返回了一次,這個過程稱為一個 epoch。
然而,當一個 epoch 對於計算機而言太龐大的時候,就需要把它分成多個小塊。
為什麼要使用多於一個 epoch?
我知道這剛開始聽起來會很奇怪,在神經網路中傳遞完整的資料集一次是不夠的,而且我們需要將完整的資料集在同樣的神經網路中傳遞多次。但是請記住,我們使用的是有限的資料集,並且我們使用一個迭代過程即梯度下降,優化學習過程和圖示。因此僅僅更新權重一次或者說使用一個 epoch 是不夠的。
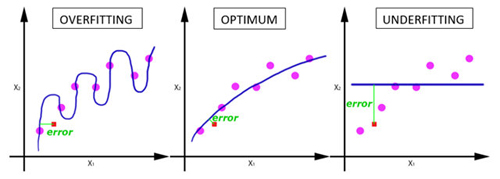
隨著 epoch 數量增加,神經網路中的權重的更新次數也增加,曲線從欠擬合變得過擬合。
那麼,幾個 epoch 才是合適的呢?
不幸的是,這個問題並沒有正確的答案。對於不同的資料集,答案是不一樣的。但是資料的多樣性會影響合適的 epoch 的數量。比如,只有黑色的貓的資料集,以及有各種顏色的貓的資料集。
BATCH SIZE
一個 batch 中的樣本總數。記住:batch size 和 number of batches 是不同的。
BATCH 是什麼?
在不能將資料一次性通過神經網路的時候,就需要將資料集分成幾個 batch。
正如將這篇文章分成幾個部分,如介紹、梯度下降、Epoch、Batch size 和迭代,從而使文章更容易閱讀和理解。
迭代
理解迭代,只需要知道乘法表或者一個計算器就可以了。迭代是 batch 需要完成一個 epoch 的次數。記住:在一個 epoch 中,batch 數和迭代數是相等的。
比如對於一個有 2000 個訓練樣本的資料集。將 2000 個樣本分成大小為 500 的 batch,那麼完成一個 epoch 需要 4 個 iteration。