
如何快速全面建立自己的大資料知識體系?
很多人都看過不同型別的書,也接觸過很多有關大資料方面的文章,但都是很零散不成系統,對自己也沒有起到多大的作用,所以作者第一時間,帶大家從整體體系思路上,瞭解大資料產品設計架構和技術策略。
大資料產品,從系統性和體系思路上來做,主要分為五步:
針對前端不同渠道進行資料埋點,然後根據不同渠道的採集多維資料,也就是做大資料的第一步,沒有全量資料,何談大資料分析;
第二步,基於採集回來的多維度資料,採用ETL對其各類資料進行結構化處理及載入;
然後第三步,對於ETL處理後的標準化結構資料,建立資料儲存管理子系統,歸集到底層資料倉庫,這一步很關鍵,基於資料倉庫,對其內部資料分解成基礎的同類資料集市;
然後基於歸集分解的不同資料集市,利用各類R函式包對其資料集進行資料建模和各類演算法設計,裡面演算法是需要自己設計,個別演算法可以用R函式分享大資料學習扣扣群:498856122零基礎.進階.實戰歡迎加入,每天分享最新學習視訊。這個過程產品和運營參與最多;這一步做好了,也是很多公司使用者畫像系統的底層。
最後根據建立的各類資料模型及演算法,結合前端不同渠道不同業務特徵,根據渠道觸點自動匹配後端模型自動展現使用者個性化產品和服務。
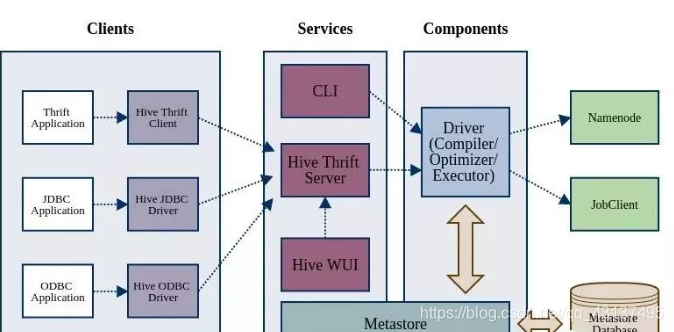
分為五步
建立系統性資料採集指標體系
建立資料採集分析指標體系是形成營銷資料集市的基礎,也是營銷資料集市覆蓋使用者行為資料廣度和深度的前提,資料採集分析體系要包含使用者全活動行為觸點資料,使用者結構化相關資料及非結構化相關資料,根據資料分析指標體系才能歸類彙總形成篩選使用者條件的屬性和屬性值,也是發現新的營銷事件的基礎。
構建營銷資料指標分析模型,完善升級資料指標採集,依託使用者全流程行為觸點,建立使用者行為消費特徵和個體屬性,從使用者行為分析、商業經營資料分析、營銷資料分析三個維度,形成使用者行為特徵分析模型。使用者維度資料指標是不同維度分析要素與使用者全生命週期軌跡各觸點的二維交叉得出。
目前做大資料平臺的公司,大多數採集的資料指標和輸出的視覺化報表,都存在幾個關鍵問題:
採集的資料都是以渠道、日期、地區統計,無法定位到具體每個使用者;
計算統計出的資料都是規模資料,針對規模資料進行挖掘分析,無法支援;
資料無法支撐系統做使用者獲客、留存、營銷推送使用。
所以,要使系統採集的資料指標能夠支援平臺前端的個性化行為分析,必須圍繞使用者為主線來進行畫像設計,在初期視覺化報表成果基礎上,將統計出來的不同規模資料,細分定位到每個使用者,使每個資料都有一個使用者歸屬。
將分散無序的統計資料,在依據使用者來銜接起來,在現有產品介面上,每個統計資料都增加一個標籤,點選標籤,可以展示對應每個使用者的行為資料,同時可以連結到其他統計資料頁面。
由此可以推匯出,以使用者為主線來建立資料採集指標維度:使用者身份資訊、使用者社會生活資訊、使用者資產資訊、使用者行為偏好資訊、使用者購物偏好、使用者價值、使用者反饋、使用者忠誠度等多個維度,依據建立的採集資料維度,可以細分到資料指標或資料屬性項。
① 使用者身份資訊維度
性別,年齡,星座,居住城市,活躍區域,證件資訊,學歷,收入,健康等。
② 使用者社會生活資訊維度
行業,職業,是否有孩子,孩子年齡,車輛,住房性質,通訊情況,流量使用情況……
③ 使用者行為偏好資訊
是否有網購行為,風險敏感度,價格敏感度,品牌敏感度,收益敏感度,產品偏好,渠道偏好……
④ 使用者購物偏好資訊
品類偏好,產品偏好,購物頻次,瀏覽偏好,營銷廣告喜好,購物時間偏好,單次購物最高金額……
⑤ 使用者反饋資訊維度
使用者參與的活動,參與的討論,收藏的產品,購買過的商品,推薦過的產品,評論過的產品……
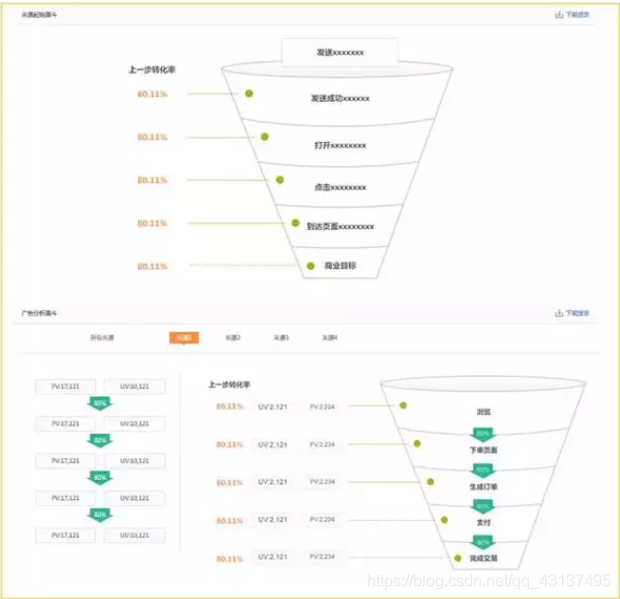
廣告分析漏斗
基於採集回來的多維度資料,採用ETL對其各類資料進行結構化處理及載入
資料補缺:對空資料、缺失資料進行資料補缺操作,無法處理的做標記
資料替換:對無效資料進行資料的替換
格式規範化:將源資料抽取的資料格式轉換成為便於進入倉庫處理的目標資料格式
主外來鍵約束:通過建立主外來鍵約束,對非法資料進行資料替換或匯出到錯誤檔案重新處理
資料合併:多用表關聯實現(每個欄位加索引,保證關聯查詢的效率)
資料拆分:按一定規則進行資料拆分
行列互換、排序/修改序號、去除重複記錄
資料處理層 由 Hadoop叢集 組成 , Hadoop叢集從資料採集源讀取業務資料,通過平行計算完成業務資料的處理邏輯,將資料篩選歸併形成目標資料。
資料建模、使用者畫像及特徵演算法
提取與營銷相關的客戶、產品、服務資料,採用聚類分析和關聯分析方法搭建資料模型,通過使用者規則屬性配置、規則模板配置、使用者畫像打標籤,形成使用者資料規則集,利用規則引擎實現營銷推送和條件觸發的實時營銷推送,同步到前端渠道互動平臺來執行營銷規則,並將營銷執行效果資訊實時返回到大資料系統。
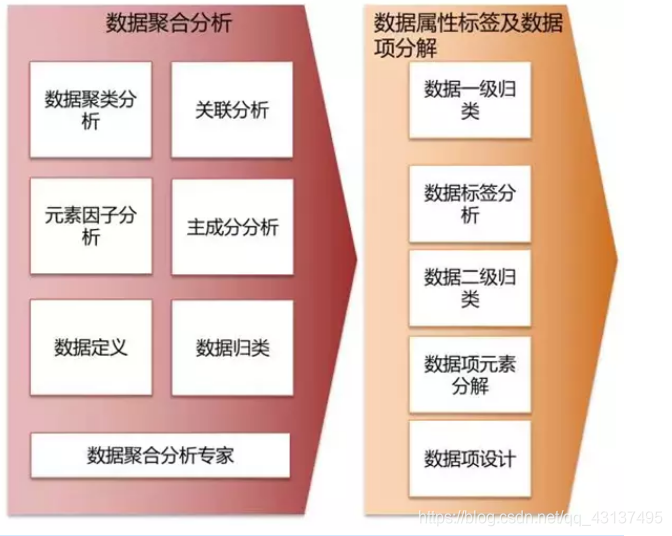
大資料系統
根據前端使用者不同個性化行為,自動匹配規則並觸發推送內容
根據使用者全流程活動行為軌跡,分析使用者與線上渠道與線下渠道接觸的所有行為觸點,對營銷使用者打標籤,形成使用者行為畫像,基於使用者畫像提煉彙總營銷篩選規則屬性及屬性值,最終形成細分使用者群體的條件。每個使用者屬性對應多個不同屬性值,屬性值可根據不同活動個性化進行配置,支援使用者黑白名單的管理功能。
可以預先配置好基於不同使用者身份特性的活動規則和模型,當前端使用者來觸發配置好的營銷事件,資料系統根據匹配度最高的原則來實時自動推送營銷規則,並通過實時推送功能來配置推送的活動內容、優惠資訊和產品資訊等,同時彙總前端反饋回的效果資料,對推送規則和內容進行優化調整。
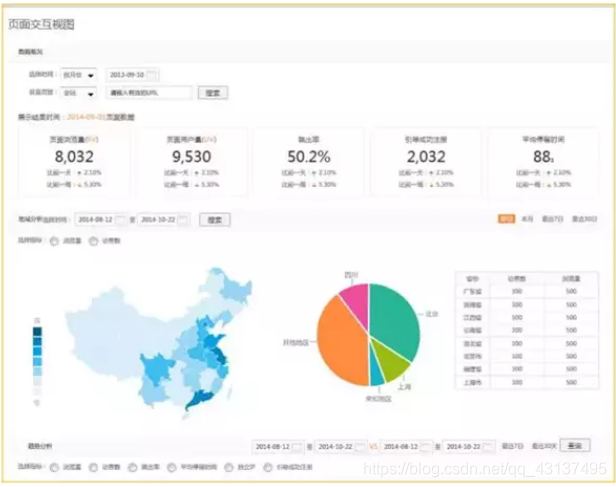
頁面互動檢視
大資料系統結合客戶營銷系統在現有使用者畫像、使用者屬性打標籤、客戶和營銷規則配置推送、同類型使用者特性歸集分庫模型基礎上,未來將逐步擴充套件機器深度學習功能,通過系統自動蒐集分析前端使用者實時變化資料,依據建設的機器深度學習函式模型,自動計算匹配使用者需求的函式引數和對應規則,營銷系統根據計算出的規則模型,實時自動推送高度匹配的營銷活動和內容資訊。
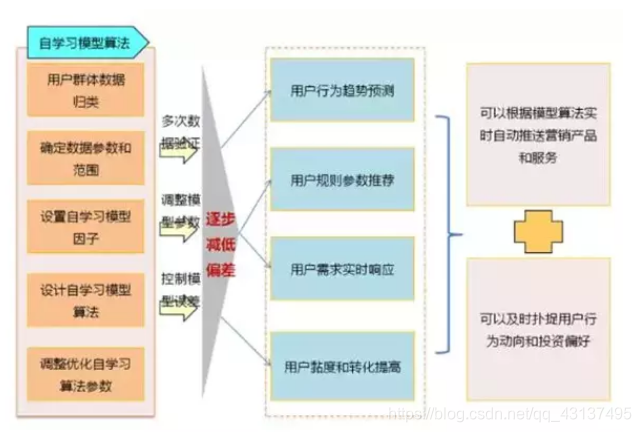
自學習模型演算法
機器自學習模型演算法是未來大資料系統深度學習的核心,通過系統大量取樣訓練,多次資料驗證和引數調整,才能最終確定相對精準的函式因子和引數值,從而可以根據前端使用者產生的實時行為資料,系統可自動計算對應的營銷規則和推薦模型。
大資料系統在深度自學習外,未來將通過逐步開放合作理念,對接外部第三方平臺,擴充套件客戶資料範圍和行為觸點,儘可能覆蓋使用者線上線下全生命週期行為軌跡,掌握使用者各行為觸點資料,擴大客戶資料集市和事件庫,才能深層次挖掘客戶全方位需求,學習環境很重要歡迎大家加入498856122結合機器自學習功能,從根本上提升產品銷售能力和客戶全方位體驗感知。