
Hadoop-(wordcount升級版)分析日誌統計IP地址來源
阿新 • • 發佈:2018-12-04
1. 前言
由於隱私問題,這裡不提供日誌,可自行準備或隨機生成。
下面給出的程式碼統計的資料檔案格式是定的,如果格式與博主不同,請適當修改程式碼。
2. 分析
- 分析日誌統計出IP地址來源,重點無非是IP地址,如下圖:
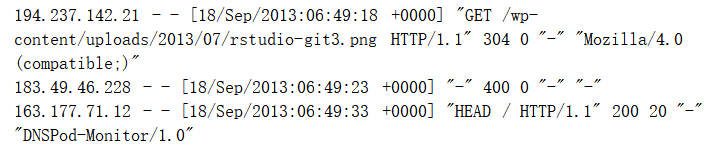
- 通過正則表示式提取合理IP地址:
正則表示式線上測試網站:http://tool.oschina.net/regex/
如下圖:

- 將提取出的IP地址查詢其地址來源
批量IP地址查詢網站:http://ip.soshoulu.com/
如下圖:
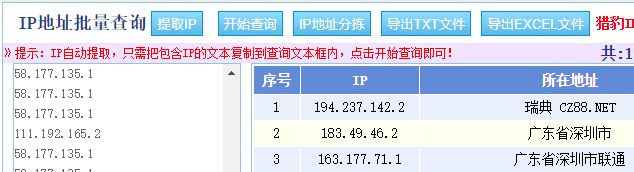
- 匯出TXT檔案
將匯出的檔案上傳至Hadoop叢集。
程式碼中共執行了三個 job 任務:
- 根據IP分類、計數
- 根據地址來源分類、計數
- 按照省、市、國家等分類、計數(注:該job的輸入為第2個job的輸出)
因此,程式碼設定了 main 函式的引數(可根據自身叢集設定):
右鍵 Run As -> Run Configures

剖析:
hdfs://master:9000/data/logfile/access.log.10 ===> 第一個job的輸入 hdfs://master:9000/output/logAnalysisOutput/IPAndCount ===> 第一個job的輸出 hdfs://master:9000/data/logfile/IPaddressAll.txt ===> 第二個job的輸入 hdfs://master:9000/output/logAnalysisOutput/area ===> 第二個job的輸出、第三個job的輸入 hdfs://master:9000/output/logAnalysisOutput/detail ===> 第三個job的輸出
注:
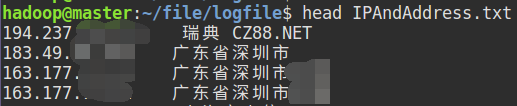
兩個輸入檔案的格式如下:

下圖檔案內容是先使用正則提取IP,然後使用批量查詢IP地址後匯出的檔案:
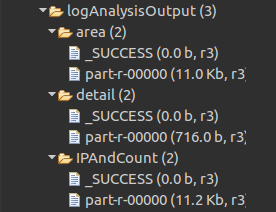
HDFS輸出:(注:logAnalysisOutput需要先建立,area、detail、IPAndCount自動生成)
程式碼見 GitHub:https://github.com/GYT0313/LogAnalysis
實驗日誌輸出結果示例:
- IPAndCount:
1.xxx.203.1 2
1.xxx.186.3 53
1.xxx.222.1 1
1.xxx.70.7 1
1.xxx.126.5 41
- area:
---- 1 上海市xxxxxx公司上海電信節點 7 上海市xxxxxx公司電信節點 28 上海市xxxx公司(中山南路xxx號) 33 烏克蘭 5 雲南省xxxx電信 1 雲南省xxxx 1
- detail
上海市 3336
烏克蘭 5
雲南省 35
俄羅斯 8
其他國家和地區 17
內蒙古 19
加拿大 57