
Redis底層詳解(二) 字串

一、sds字串概述
sds 字串即 Simple Dynamic String(即簡單動態字串),其中動態的含義是記憶體的分配是動態的,sds的定義如下:

它採用一段連續的記憶體來儲存 sds 結構。和普通字串 char* 不同,sds 是二進位制安全的,並不以 '\0' 來標識字串結尾,於是必須要有一個 len 欄位來標記這個字串的長度。那麼,我們可以簡單地認為這個字串是由“字串長度”和“字元陣列”組成的。結構如圖所示(實際結構還會稍微複雜一些):

二、Redis 資料結構定義
1、sds 儲存結構
Redis 中的 sds 字串的具體的儲存結構如下圖所示:

其中 sdshdr 含義為“sds header”(sds 頭部),len 欄位就儲存在這個 header 中;buf 則用來儲存位元組陣列,即原始字串。
2、sds 頭部
為了適應不同長度的字串,sds 頭部一共設計了5種結構,分別適應長度在各自範圍內的字串。這五種結構分別為 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64(末尾數字對應的是2的次冪)。例如 sdshdr5 用於儲存長度在2的5次冪以內的,sdshdr16 用於儲存長度在2的16次冪以內的,等等。
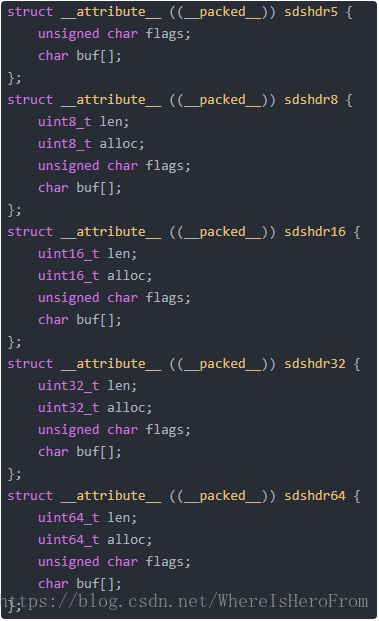
從上面的程式碼可以看出,除了 sdshdr5,其它四個 sds 頭部的結構設定是完全一致的。
先來介紹其它四種頭部,最後介紹 sdshdr5。其中 __attribute__ ((__packed__)) 的作用是告訴編譯器不採用位元組對齊。拿 sdshdr32 來舉例,由於不採用位元組對齊,所以結構體中的每個欄位都是緊湊排列的,len 和 alloc 佔用4個位元組,flags佔用1個位元組,buf 作為字串起始地址,本身不佔用位元組數,所以 sizeof(sdshdr32) 的值就是 4+4+1 = 9。
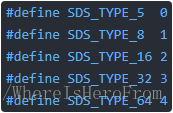
len 欄位就存下了這個 sds 字串的長度;sds字串採用空間預分配機制,alloc 欄位就代表當前這個字串預先分配了多少位元組的可用空間,所以 alloc 一定是大於等於 len 的;flags 的低三位代表 sds 的型別,分別用以下五個巨集表示:
sds 字串詳細的記憶體結構如下圖所示(sdshdr5除外):
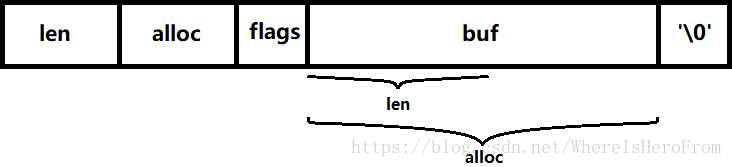
為了相容傳統C字串,需要在 buf 末尾多申請一個位元組用於存放 '\0' 。所以一個 sds 字串佔用的記憶體位元組總數為:sizeof(sdshdr) + alloc + 1。
sdshdr5 的 flags 的低三位儲存 SDS_TYPE,高五位儲存字串的長度 len,詳見下文的 SDS_TYPE_5_LEN 的巨集定義,這個巨集就是計算 sdshdr5 表示的字串的長度。
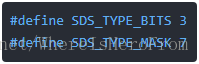
另外兩個巨集分別代表 SDS_TYPE 佔用的位元位數以及它的掩碼,掩碼 SDS_TYPE_MASK 主要用於和 flags進行 "位與" 運算獲取這個字串的 SDS_TYPE:
三、字串資訊
1、長度
字串長度就是這個字串已經使用的空間,即 len 欄位的值。當我們得到一個 sds 結構時,它的真正地址是指向 buf 欄位的(即字串首地址)。有了字串首地址,只要知道這個字串的長度,就能獲取這整個字串資訊了。字串長度獲取是利用 sds.h/sdslen 函式實現的:
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1]; // 1) 偏移獲取flags
switch(flags&SDS_TYPE_MASK) { // 2) 掩碼運算得到SDS_TYPE
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags); // 3) 獲取SDS_TYPE_5型別的字串的len
case SDS_TYPE_8:
return SDS_HDR(8,s)->len; // 4) 獲取非SDS_TYPE_5型別的字串的len
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
} 1) 由於 s 的地址指向 buf,所以只要向前偏移1個位元組,就能得到 flags 欄位了,即 flags = s[-1];
2) flags 正好一個位元組(總共8個位元位),低3位用來儲存 SDS_TYPE,除了 sdshdr5 高5位用來表示字串長度,其它型別的 flags 的高五位是留空的。SDS_TYPE_MASK 的值為7,二進位制表示為(111),和 flags 作“位與”運算就可以獲得 flags 的低3位。
3) SDS_TYPE_5_LEN是一個巨集定義,含義是取 flags 的高5位。再回到之前 sdshdr5 的結構體定義,發現和其它的不同,它沒有 len 欄位,因為它的長度比較短,所以可以把 len 和 SDS_TYPE 統一儲存在 flags 欄位上。即用低3位代表 SDS_TYPE,高5位代表字串長度。這就是為什麼獲取 SDS_TYPE 時要進行掩碼運算的原因。
4) SDS_HDR(T, s) 也是一個巨集,巨集定義中用到了字串連線('##')用於獲取給定型別T的 "sds header" 結構體,用 s 減去 sizeof(sdshdr) 就能得到 "sds header" 結構體的首地址,進而獲得這個字串 buf 的 len 欄位。
2、預留空間
預留空間大小由 alloc 引數指定,用和 sdslen 同樣的方法,獲取字串申請了多少可用空間的函式,是在 sds.h/sdsalloc 函式實現的:
static inline size_t sdsalloc(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->alloc;
case SDS_TYPE_16:
return SDS_HDR(16,s)->alloc;
case SDS_TYPE_32:
return SDS_HDR(32,s)->alloc;
case SDS_TYPE_64:
return SDS_HDR(64,s)->alloc;
}
return 0;
} 3、剩餘空間
sdslen 和 sdsalloc 的區別僅在於欄位的獲取上,前者取的是 len 欄位,後者取的是 alloc 欄位。兩者相減,可以得到當前字串還有多少剩餘空間,在 sds.h/sdsavail 函式中實現:
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0; // 1) alloc == len
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 2) 似 SDS_HDR 的巨集定義
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
} 1) SDS_TYPE_5 的 alloc == len,所以剩餘空間為零;
2) SDS_HDR_VAR 是和 SDS_HDR 類似的巨集定義,只不過它多了一步賦值,將指標的值賦值給了 sh;
四、字串操作
1、字串建立
建立一個給定長度的字串,實現在 sds.c/sdsnewlen 函式中:
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); // 1) 根據長度獲取對應的SDS_TYPE
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; // 2) 空字串採用SDS_TYPE_8
int hdrlen = sdsHdrSize(type); // 3) 根據 SDS_TYPE 獲取 header 佔據的位元組數
unsigned char *fp;
sh = s_malloc(hdrlen+initlen+1); // 4) 分配記憶體空間
if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen; // 5) s指標定位到 buf 首地址
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS); // 6) SDS_TYPE_5 處理
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: ... // 7) sdshdr16、sdshdr32、sdshdr64 和 sdshdr8 的處理一致
case SDS_TYPE_32: ...
case SDS_TYPE_64: ...
}
if (initlen && init)
memcpy(s, init, initlen); // 8) 拷貝記憶體
s[initlen] = '\0';
return s;
}1) sdsReqType 函式根據申請的 initlen 大小,分配相應的 SDS_TYPE。例如,長度在2的5次以內的用SDS_TYPE_5,長度在2的8次以內的用SDS_TYPE_8,以此類推;
2) 空字串的 SDS_TYPE 規定為 SDS_TYPE_8,用 SDS_TYPE_5 難以向上相容;
3) sdsHdrSize 函式是根據 SDS_TYPE 得到相應的位元組數。例如型別為 SDS_TYPE_5,返回值就是 sizeof( struct sdshdr5 ),以此類推;
4) s_malloc 用來申請記憶體空間,為了相容C字串,需要額外多分配一個位元組給'\0';
5) s 指標定位到 buf 的首地址,fp 指標定位到 flags 的地址;
6) SDS_TYPE_5 用一個位元組 flags 存 SDS_TYPE 和 長度,之前已經講過;
7) 非 SDS_TYPE_5 用同樣規則填充 len、alloc、flags 欄位;
8) 呼叫系統API memcpy 拷貝記憶體,最後加上一個 '\0' 相容傳統C字串;
由 sdsnewlen 可以引申出一系列字串的構建函式:空串函式sdsempty、建立函式sdsnew、拷貝函式sdsdup:
sds sdsempty(void) {
return sdsnewlen("",0);
}
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
sds sdsdup(const sds s) {
return sdsnewlen(s, sdslen(s));
} 2、字串銷燬
銷燬一個字串,實現在 sds.c/sdsfree 函式中:
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}字串銷燬就是釋放記憶體,利用 s_free 介面完成。 s_free 是和 s_malloc 相對應的,所以只要指定記憶體首地址,就能進行相應的釋放工作。利用 s[-1] 得到對應的 sdsheader 大小,然後偏移到 sdsheader 的首地址就能正確釋放記憶體了。
3、字串拼接
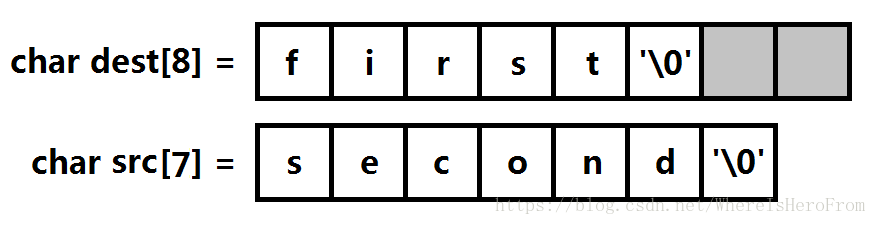
C 字串的字串拼接函式是 strcat,存在緩衝區溢位的風險。如圖所示,現在要將 src 字串拼接到 dest 字串後面,但是 dest 原先分配的最大空間是8個位元組,直接呼叫 strcat 就會造成緩衝區溢位。
而 sds 字串就不會出現這個問題,它的字串拼接函式 sds.c/sdscatlen 實現是這樣的:
sds sdscatlen(sds s, const void *t, size_t len) { // 1) 字串拼接
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len); // 2) 擴充套件空間
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); // 3) 拷貝記憶體
sdssetlen(s, curlen+len); // 4) 設定長度
s[curlen+len] = '\0';
return s;
} 1) 將一個二進位制安全的字串 t 的前 len 個字元拷貝到 sds 字串 s 的末尾,由於這樣一步操作可能導致整個字串的記憶體首地址的改變,所以這個函式需要有一個返回值,指向新的 sds 字串的首地址;
2) 如果剩餘空間不夠,就為 s 再申請 len 個位元組的空間,sdsMakeRoomFor 的實現見下文;
3) 從 t 開始的 len 個位元組拷貝到 s 字串末尾,注意不能使用 strcpy;
4) 設定新字串的長度,並且在末尾加上一個 '\0' 用於相容 C 字串;
由 sdscatlen 引出兩個字串拼接函式:sdscat 用於連線 sds字串 和 傳統C字串;sdscatsds 用於連線兩個 sds 字串。拼接過程中可能會涉及到空間預分配(下一節具體介紹),所以被拼接的字串的首地址可能會發生改變,所以需要有返回值返回拼接後字串的首地址。
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
4、字串空間預分配
在字串拼接前,sds 字串會首先檢測緩衝區大小,看是否能夠承載待拼接的字串,如果空間不夠,則進行擴容。這就是 sds 字串的空間預分配。
分配規則是:如果拼接後的字串長度 newlen 小於1M(即 1024*1024 個位元組,定義在 SDS_MAX_PREALLOC),則需要分配和 newlen 同樣大小的未使用空間;反之,則分配 1M 的 未使用的記憶體空間。換言之,就是需要分配 min {newlen, 1M} 個位元組的記憶體空間。
這麼做的目的是為了減少連續執行字串增長操作時所需的記憶體重分配次數,提高效率。空間預分配的實現如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
if (avail >= addlen) return s; // 1) 空間足夠則直接返回
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen); // 2) 空間預分配的長度計算
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8; // 3) 不使用 SDS_TYPE_5
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1); // 4) 擴大記憶體分配
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+newlen+1); // 5) 分配新的記憶體
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh); // 6) 釋放之前的記憶體
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
} 1) avail 代表剩餘未被使用的空間,如果需要擴充的空間小於等於它,則不需要進行額外空間分配,直接返回即可;
2) newlen 最後會被用於給新的 sds 字串的 alloc 欄位賦值;
3) SDS_TYPE_5 和其它結構不同,無法進行向上相容,所以擴容需要採用 SDS_TYPE_8;
4) 這裡出現一個分支,即擴容後的空間和擴容前,總的記憶體佔用對應的 SDS_TYPE 是否相同,如果相同,則在原 sds header 的首地址處呼叫 s_realloc 重新進行記憶體分配,記得加上一個位元組的空字元;
5) 如果 SDS_TYPE 不同,len 和 alloc 欄位佔用的位元組數都會變大,sds header 結構體佔用記憶體會變大,導致實際字串首地址 buf 向後偏移,所以需要呼叫 s_malloc 重新申請新的空間來儲存字串位元組陣列。
6) 最後,利用 s_free 釋放原地址的空間,否則將引起記憶體洩露。
5、字串比較
sds 字串比較類似傳統C字串的比較。利用 sdslen 獲取兩個字串的長度,然後利用系統API memcmp 進行位元組比較,實現在 sds.c/sdscmp 中:
int sdscmp(const sds s1, const sds s2) {
size_t l1, l2, minlen;
int cmp;
l1 = sdslen(s1);
l2 = sdslen(s2);
minlen = (l1 < l2) ? l1 : l2;
cmp = memcmp(s1,s2,minlen);
if (cmp == 0) return l1>l2? 1: (l1<l2? -1: 0);
return cmp;
}