
tensorflow和Python關係
轉載自http://m.elecfans.com/article/704947.html。若侵權,告知即刪
編者按:2017年夏季,CMU CS碩士生Jacob Buckman入選Google AI居留計劃,在谷歌總部開啟了自己為期12月的培訓生活,主攻NLP和強化學習。Jacob擁有豐富的程式設計經驗,而且在機器學習上也造詣頗多。雖然從未接觸過Tensorflow,但他相信依靠自己的學識背景,掌握一個工具是很輕鬆的一件事。很可惜,現實打了他的臉……
簡介
自發布三年來,Tensorflow已經成為深度學習生態系統的基石,然而相比PyTorch、DyNet這樣基於動態圖“define-by-run”的庫,它對初學者來說卻並不直觀。
從線性迴歸、MNIST分類到機器翻譯,Tensorflow的教程無處不在,它們是幫助新手開啟專案的優質資源,也是新人接觸機器學習的敲門磚。但對於機器學習還未涉足的空白領域,如果開發者想做一些原創性的突破,Tensorflow可能會讓他們望而生畏。
本文的目的是填補這一領域的空白,文章內容將緊緊圍繞一般方法,並解釋支撐Tensorflow的基本概念,而不是專注於某個特定任務。掌握這些概念後,開發者可以更直觀地用Tensorflow進行深度學習研究。
注:本教程適合在程式設計和機器學習上有一定經驗,且必須要用到Tensorflow的開發者。
瞭解Tensorflow
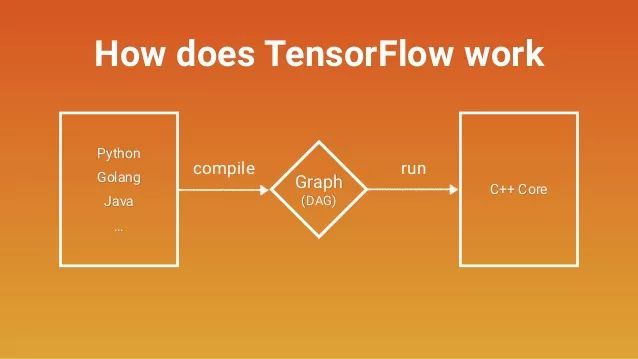
Tensorflow不是一個普通的Python庫
大多數Python庫其實是Python的擴充套件。當你匯入一個庫時,你得到的是一組變數、函式和類,它們實際上只是充當程式碼的“工具箱”,滿足開發者的現實需要。但Tensorflow不是。如果我們一開始就抱著如何和程式碼互動的想法去研究Tensorflow,那就相當於在本質上走入歧途。
要說Python和Tensorflow之間的關係,我們可以把它簡單類比成Javascript和HTML。Javascript是一種用途廣泛的程式語言,我們可以用它實現很多東西。而HTML是一個框架,可以表示一些抽象計算(比如描述網頁上呈現的內容)。當用戶開啟一個網頁時,Javascript的作用是使他看到HTML物件,並且在網頁迭代時用新的HTML物件代替舊的物件。
和HTML類似,Tensorflow也是一個用於表示抽象計算的框架。當我們用Python操作Tensorflow時,程式碼做的第一件事是組裝計算圖,第二件事是和計算圖進行互動(Tensorflow裡的會話sessions)。但計算圖不在變數內部,而在全域性名稱空間中。正如莎士比亞當年說過:所有RAM都是一個階段,所有變數都只是指標。(莎士比亞一臉懵逼)
第一個關鍵概念:計算圖
在瀏覽Tensorflow文件時,你會發現其中有大量關於“graphs”和“nodes”的描述。如果足夠細心,也許你也已經在圖和會話這個頁面找到了所有關於資料流圖的詳細介紹。這個頁面的內容是我們下文要重點解釋的,不同的是,官方文件的表述充滿“技術感”,而我們會犧牲一些技術細節,重點捕捉其中的直覺。
那麼什麼是計算圖?事實上,計算圖表示的是全域性資料結構:它一個有向圖,包含資料計算流程的所有資訊。
我們先來看一個示例:
import tensorflow as tf
計算圖:

匯入Tensorflow後,我們得到了一個空白的計算圖,表示一個孤立的、空白的全域性變數。在這個基礎上,我們再進行一些“Tensorflow操作”:
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
print two_node
輸出:
Tensor("Const:0", shape=(), dtype=int32)
計算圖:
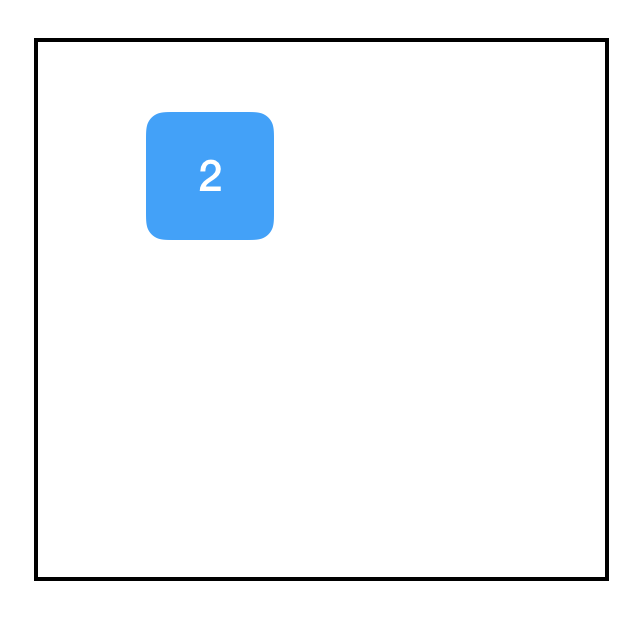
這裡我們得到了一個節點(node),它包含常數2,這個2是函式tf.constant帶來的。當我們print變數時,可以看到它返回了一個tf.Tensor物件,它是我們剛建立的節點的指標。為了驗證這一點,這裡是另一個例子:
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
another_two_node = tf.constant(2)
two_node = tf.constant(2)
tf.constant(3)
計算圖:
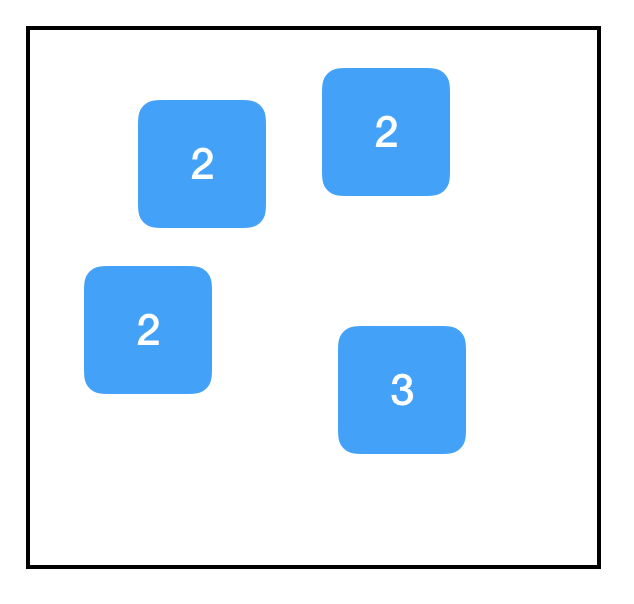
即便前後函式功能一致,即便這些函式只是簡單地給同一個物件重複賦值,甚至即便它們根本沒有被分配給變數,對於每次呼叫函式tf.constant,計算圖中都會建立一個新節點。
相反地,如果我們建立了一個新變數,並把它賦值一個存在的節點,這就相當於把指標複製到該節點,這時計算圖上是不會出現新節點的:
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
another_pointer_at_two_node = two_node
two_node = None
print two_node
print another_pointer_at_two_node
輸出:
None
Tensor("Const:0", shape=(), dtype=int32)
計算圖:

接下來,我們嘗試一些有趣的東西:
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node ## 相當於 tf.add(two_node, three_node)
計算圖:
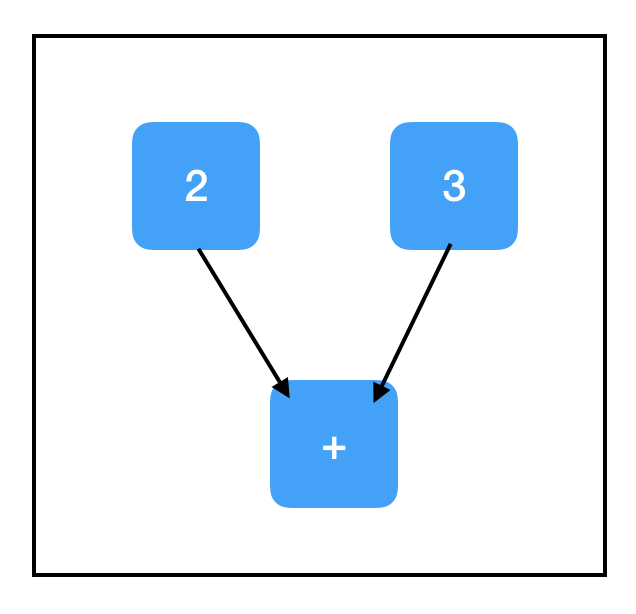
上圖已經是一幅真正意義上的計算圖了。需要注意的是,TensorFlow對常見數學運算子進行了過載,比如上面的tf.add。雖然它表面上沒有新增節點,但它確實把兩個張量一起新增進了一個新節點。
所以two_node指向包含2的節點,three_node指向包含3的節點,sum_node指向包含+的節點——是不是覺得有些不尋常,為什麼sum_node裡會是+,而不是5呢?
事實上,計算圖只包含步驟,不包含結果!至少……現在還不包含!
第二個關鍵概念:會話
如果說TensorFlow中存在bug重災區,那會話(session)一定排名首位。由於缺乏明確的命名,再加上函式的通用性,幾乎每個Tensorflow程式都要呼叫不止一次tf.Session()。
會話的作用是管理程式執行時的所有資源,如記憶體分配和優化,以便我們能按照計算圖的指示進行實際計算。你可以把計算圖想象成計算“模板”,上面列出了所有詳細步驟。所以每次在啟動計算圖前,我們都要先進行一個會話,分配資源,完成任務;在計算結束後,我們又得關閉會話來幫助系統回收資源,防止資源洩露。
會話包含一個指向全域性的指標,這個指標會基於計算圖中所有指向節點的指標不斷更新。這意味著會話和節點的建立不存在時間先後問題。
建立會話物件後,我們可以用sess.run(node)返回節點的值,並且Tensorflow會執行確定該值所需的所有計算。
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print sess.run(sum_node)
輸出:
5
計算圖:
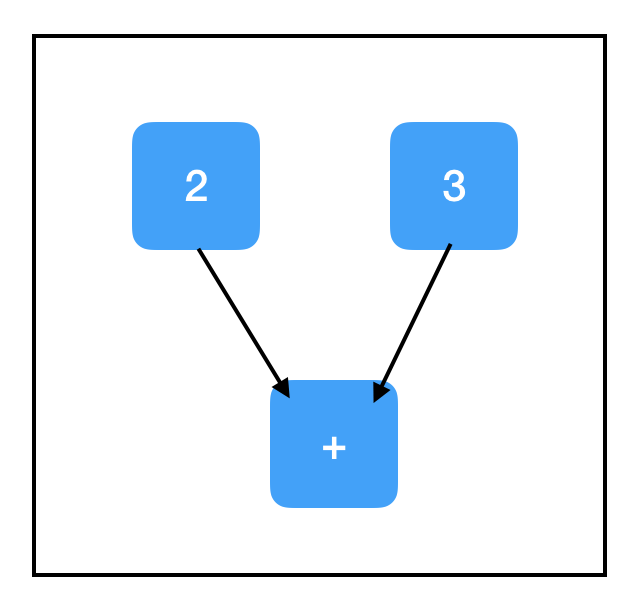
我們也可以寫成sess.run([node1, node2,...]),讓它返回多個輸出:
程式碼:
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print sess.run([two_node, sum_node])
輸出:
[2, 5]
計算圖:
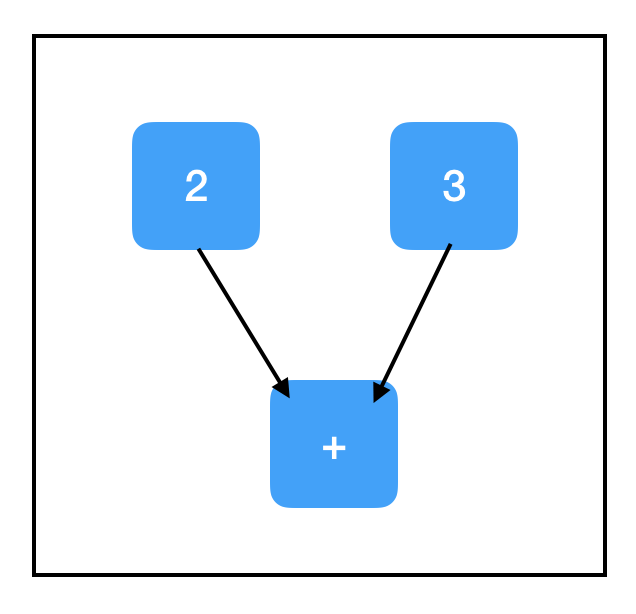
一般來說,sess.run()是TensorFlow的最大瓶頸,你用的越少,程式就越好。只要有可能,我們應該讓它一次性輸出多個結果,而不是頻繁使用,千萬不要把它放進複雜迴圈。
佔位符和feed_dict
到目前為止,我們做的計算沒有輸入,所以一直得到相同的輸出。下面我們會進行更有意義的探索,比如構建一個能接受輸入的計算圖,讓它經過某種方式的處理,最後返回一個輸出。
要做到這一點,最直接的方法是使用佔位符(Placeholders),這是一種用於接受外部輸入的節點。
程式碼:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
sess = tf.Session()
print sess.run(input_placeholder)
輸出:
Traceback (most recent call last):
...
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'Placeholder'with dtype int32
[[Node: Placeholder = Placeholder[dtype=DT_INT32, shape=, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
計算圖:

...不是個好兆頭。這是一個典型的失敗案例,因為佔位符本身沒有初始值,再加上我們沒有對它賦值,Tensorflow出現了個bug。
在會話sess.run()中,佔位符可以用feed_dict饋送資料。
程式碼:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
sess = tf.Session()
print sess.run(input_placeholder, feed_dict={input_placeholder: 2})
輸出:
2
計算圖:

注意feed_dict的格式,它是一個字典,對於計算圖中所有存在的佔位符,它都要給出相應的取值(如前所述,它其實是指向圖中佔位符節點的指標),這些值一般是標量或Numpy陣列。
第三個關鍵概念:計算路徑
讓我們試試另一個涉及佔位符的例子:
程式碼:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
three_node = tf.constant(3)
sum_node = input_placeholder + three_node
sess = tf.Session()
print sess.run(three_node)
print sess.run(sum_node)
輸出:
3
Traceback (most recent call last):
...
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'Placeholder_2'with dtype int32
[[Node: Placeholder_2 = Placeholder[dtype=DT_INT32, shape=, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
計算圖:
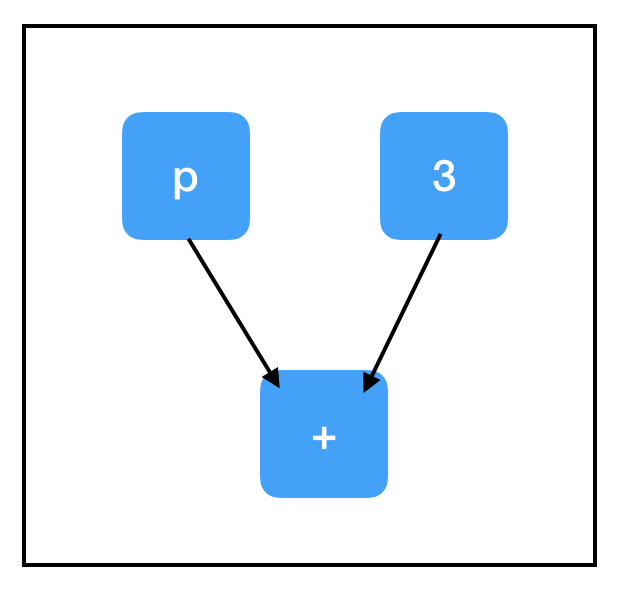
我們又在輸出中看到了失敗標誌...,那麼為什麼第二個sess.run這次出現bug了呢?為什麼我們沒有評估input_placeholder,最後卻引發了一個關於它的錯誤?這兩個問題的答案就在於Tensorflow的第三個關鍵概念:計算路徑。好在這塊內容總體比較直觀。
當我們呼叫sess.run()時,我們計算的不只是當前節點,還有一些和它相關的節點的值。如果這個節點依賴於其他節點,那我們就要一步步上溯計算,直到達到計算圖的“頂端”,也就是不再有其他節點會對目標節點施加影響。
下圖是sum_node節點的計算路徑:
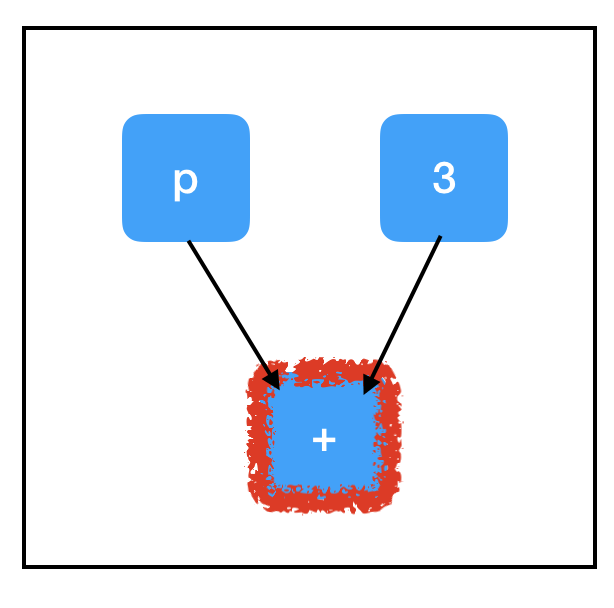
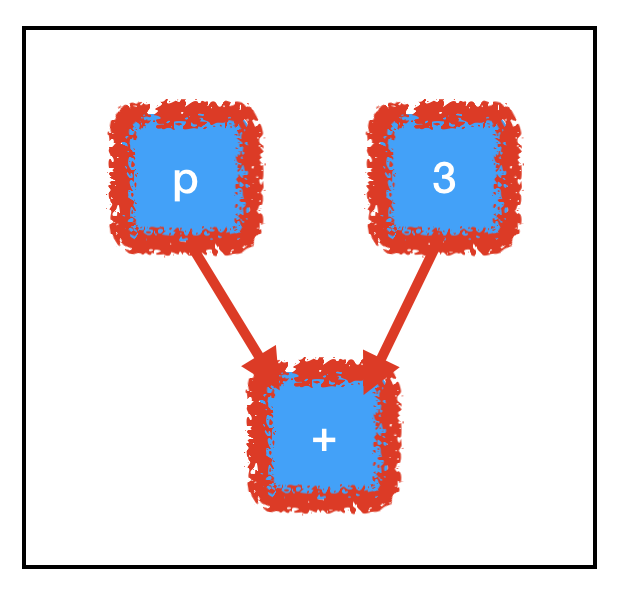
為了計算sum_node,我們要評估所有三個節點的值,其中包括我們沒有賦值的佔位符,這解釋了出現錯誤的原因。
相反地,three_node的計算路徑比較單一:
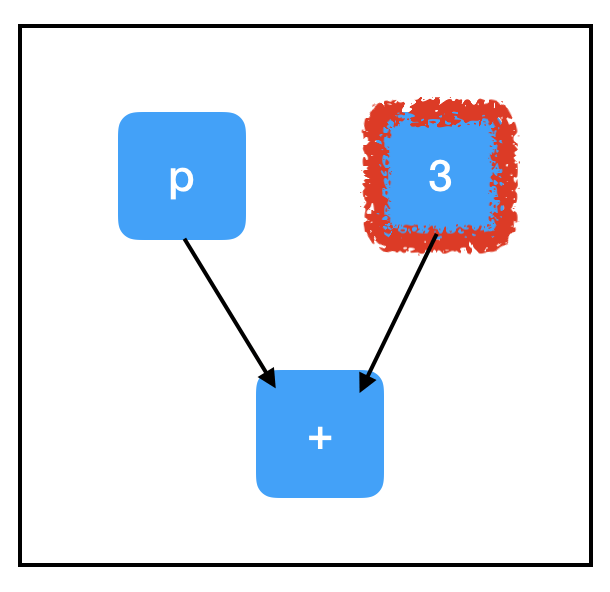
只要評估一個節點就夠了,所以即便input_placeholder沒有賦值,它也不會對sess.run(three_node)造成影響。
Tensorflow的框架優勢離不開計算路徑設計。想象一下,如果我們手裡有一幅巨型計算圖,其中包含大量不必要的節點,通過這樣的計算方式,我們可以繞過大多數點,只計算必要內容,這就為節省大量執行時間提供了可能性。此外,它還允許我們構建大型的“多用途”計算圖,這些圖中可以有一些共享的核心節點,但我們可以通過不同計算路徑來進行不同的計算。
變數和副作用
截至目前,我們接觸了兩種“沒有祖先”的節點:tf.constant和tf.placeholder。其中前者每輪都是一個定值;後者每輪都不一樣。除此之外,我們還需要考慮第三種情況:它可以連續幾輪都是個定製,但如果出現了一個新值,它也可以更新。這就是我們要引入的變數(Variables)概念。
如果想用Tensorflow進行深入學習,瞭解變數至關重要,因為模型的引數基本上都是變數。在訓練期間,我們會用梯度下降更新引數;但在評估過程中,我們卻要保持引數不變,並將大量不同的測試集輸入模型中。所以如果有可能的話,我們會希望所有可訓練的引數都是變數。
建立變數的方法是tf.get_variable(),其中前兩個引數tf.get_variable(name, shape)是固定的,其他的都是可選引數。name是標識變數物件的字串,它必須是獨一無二的,要確保沒有重複名稱。shape是與張量形狀對應的整數矩陣,它按順序排列,每個維度只有一個整數,例如一個3×8矩陣的shape應該是[3, 8]。如果建立的是標量,記得符號是[]。
程式碼:
import tensorflow as tf
count_variable = tf.get_variable("count", [])
sess = tf.Session()
print sess.run(count_variable)
輸出:
Traceback (most recent call last):
...
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _Retval[T=DT_FLOAT, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](count)]]
計算圖:
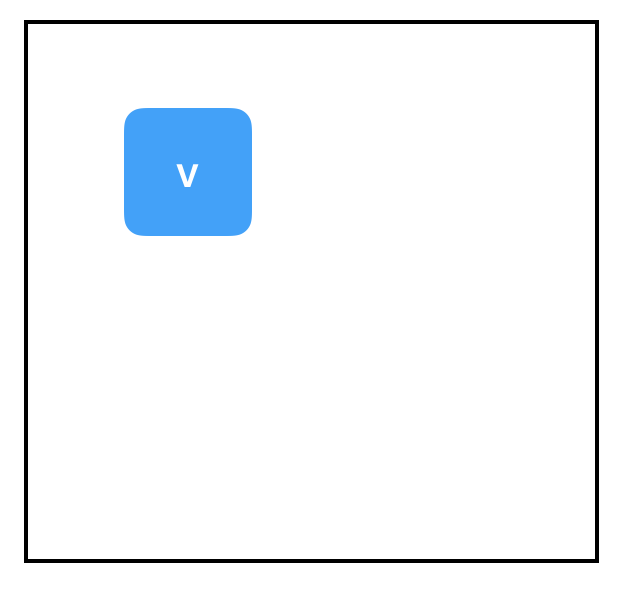
又出問題了,這次又是為什麼呢?當我們首次建立變數時,它的初始值是“Null”,這時評估它都是會出bug的。變數要先賦值,再評估。這裡賦值的方法有兩種,一是設定一個初始值,二是tf.assign()。我們來看tf.assign():
程式碼:
import tensorflow as tf
count_variable = tf.get_variable("count", [])
zero_node = tf.constant(0.)
assign_node = tf.assign(count_variable, zero_node)
sess = tf.Session()
sess.run(assign_node)
print sess.run(count_variable)
輸出:
0
計算圖:
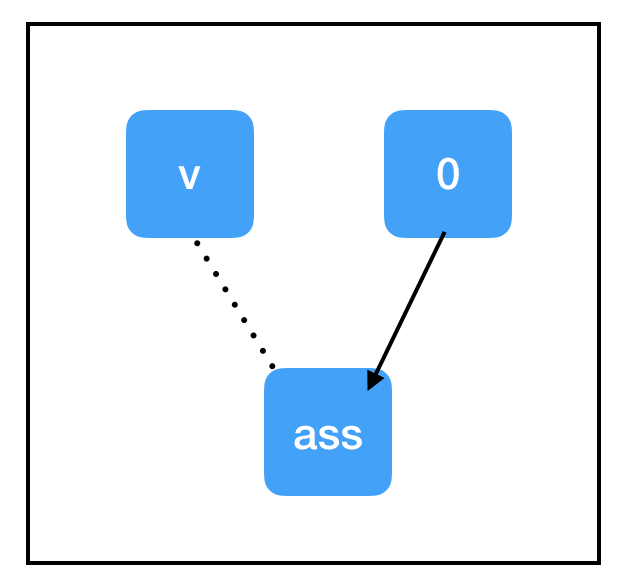
和上文提到的節點相比,tf.assign(target, value)這個節點有點特殊:
它不做計算,總是等於value;
副作用(Side Effects)。上圖顯示了這個操作的副作用,當計算流通過assign_node時,count_variable節點裡的值被強行替換成了zero_node節點的值;
即便count_variable節點和assign_node之間存在連線,但兩者互不依賴(虛線)。
因為“副作用”節點支撐著大部分Tensorflow深度學習計算流,所以真正理解其中的原理是很有必要的,當我們執行sess.run(assign_node)時,計算路徑經過assign_node和zero_node:
計算圖:
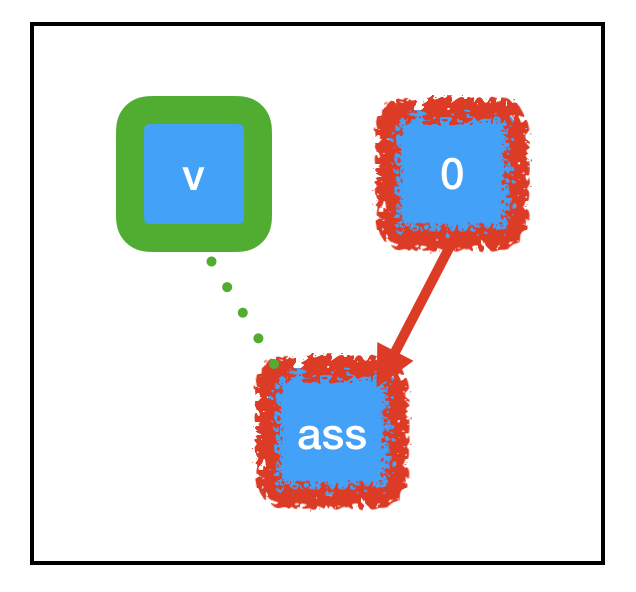
之前提到了,我們計算目標節點時會一起計算和它相關的節點,這之中包括副作用。如上圖中的綠色部分所示,由於tf.assign帶來的特定副作用,原先儲存“Null”的count_variable現在已經被永久設定成了0,這意味著下次我們呼叫sess.run(count_variable)時,它會輸出0,而不是反饋bug。
接下來,讓我們看看設定初始值:
程式碼:
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable("count", [], initializer=const_init_node)
sess = tf.Session()
print sess.run([count_variable])
輸出:
Traceback (most recent call last):
...
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _Retval[T=DT_FLOAT, index=0, _device="/job:localhost/replica:0/task:0/device:CPU:0"](count)]]
計算圖:
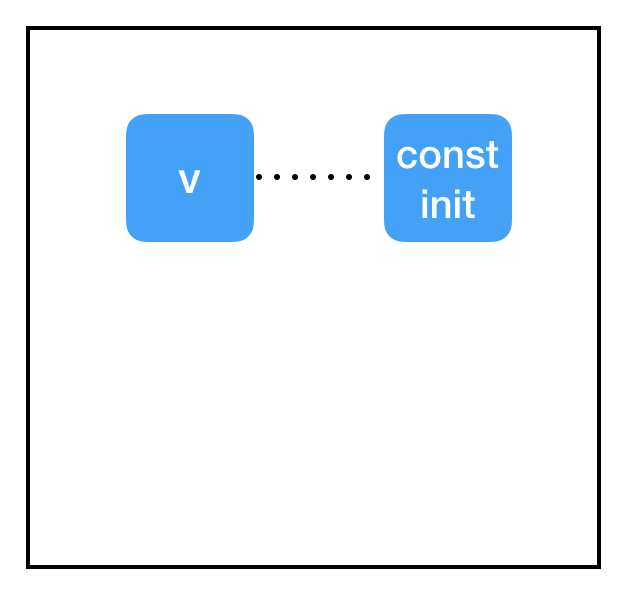
好的,為什麼這裡又沒有初始化呢?
答案在於會話和計算圖之間的割裂。我們為變數設定了一個初始值const_init_node,但它反映在計算圖上卻只是兩個節點間的虛線連線。這是因為我們在會話中根本沒有初始化操作,沒有為它分配計算資源。我們需要在會話中把變數更新成const_init_node。
程式碼:
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable("count", [], initializer=const_init_node)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print sess.run(count_variable)
輸出:
0.
計算圖:
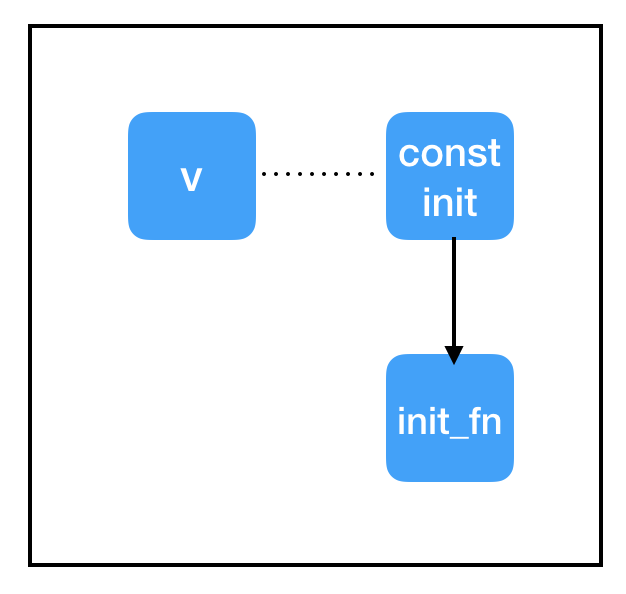
為此,我們添加了另一個特殊節點:init = tf.global_variables_initializer()。和tf.assign()類似,這也是一個帶有副作用的節點,但它不需要指定輸入內容。tf.global_variables_initializer()從建立之初就縱觀全圖,並自動為圖中的每個tf.initializer新增依賴關係。當我們開始執行sess.run(init)時,它會完成全圖初始化,從而避免報錯。
變數共享
在實際操作中,有時我們也會遇到Tensorflow程式碼與變數共享,它涉及建立範圍並設定“reuse = True”,但我們強烈不建議你這麼做。如果你想在多個地方使用單個變數,只需以程式設計方式跟蹤指向該變數節點的指標,並在需要時重新使用它。換句話說,對於你打算儲存在記憶體中的每個引數,你應該只調用一次tf.get_variable()。
除了以上三點,文章還介紹了優化和debug過程中容易遇到的錯誤,考慮到程式碼過長影響閱讀體驗,如果讀者感興趣,可以關注【論智】知乎專欄,明天小編會整理更新。
希望這篇文章能夠幫助你更好地理解Tensorflow是什麼、它是如何工作的,以及如何使用它。