
Btree索引詳解
Btree索引(或Balanced Tree),是一種很普遍的資料庫索引結構,oracle預設的索引型別(本文也主要依據oracle來講)。其特點是定位高效、利用率高、自我平衡,特別適用於高基數字段,定位單條或小範圍資料非常高效。理論上,使用Btree在億條資料與100條資料中定位記錄的花銷相同。
資料結構利用率高、定位高效
Btree索引的資料結構如下:
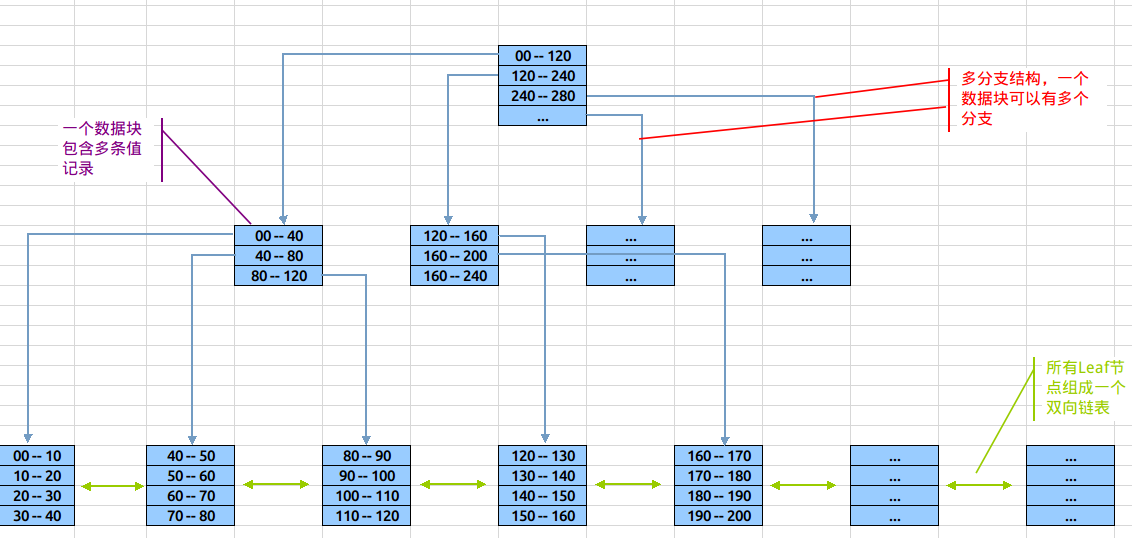
結構看起來Btree索引與Binary Tree相似,但在細節上有所不同,上圖中用不同顏色的標示出了Btree索引的幾個主要特點:
- 樹形結構:由根節(root)、分支(branches)、葉(leaves)三級節點組成,其中分支節點可以有多層。
- 多分支結構:與binary tree不相同的是,btree索引中單root/branch可以有多個子節點(超過2個)。
- 雙向連結串列:整個葉子節點部分是一個雙向連結串列(後面會描述這個設計的作用)
- 單個數據塊中包括多條索引記錄
這裡先把幾個特點羅列出來,後面會說到各自的作用。
結構上Btree與Binary Tree的區別,在於binary中每節點代表一個數值,而balanced中root和Btree節點中記錄了多條”值範圍”條目(如:[60-70][70-80]),這些”值範圍”條目分別指向在其範圍內的葉子節點。既root與branch可以有多個分支,而不一定是兩個,對資料塊的利用率更高
在Leaf節點中,同樣也是存放了多條索引記錄,這些記錄就是具體的索引列值,和與其對應的rowid。另外,在葉節點層上,所有的節點在組成了一個雙向連結串列。
瞭解基本結構後,下圖展示定位數值82的過程:
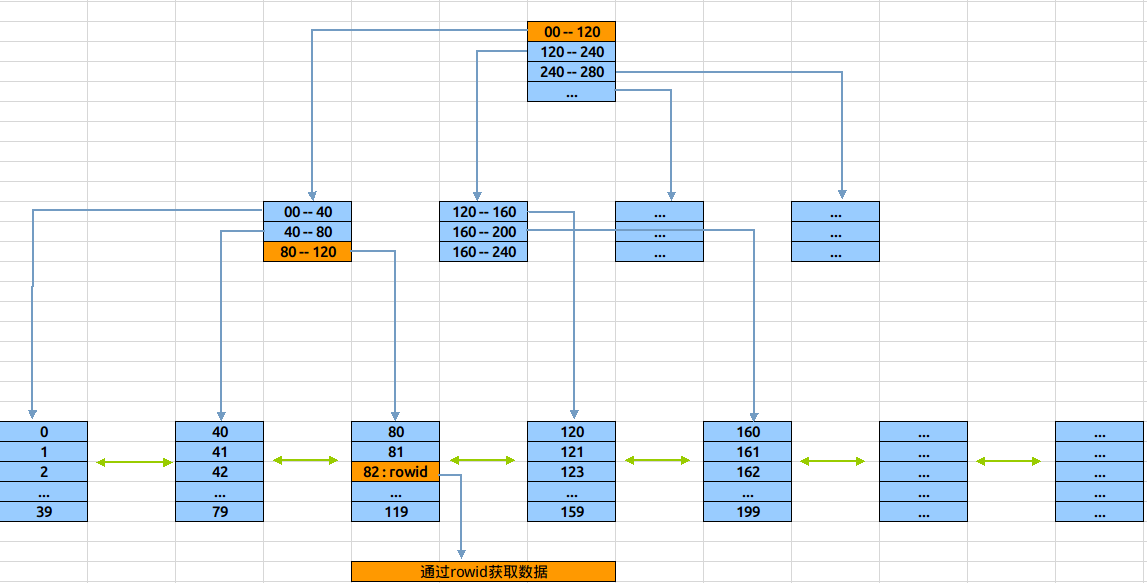
演算如下:
讀取root節點,判斷82大於在0-120之間,走左邊分支。
讀取左邊branch節點,判斷82大於80且小於等於120,走右邊分支。
讀取右邊leaf節點,在該節點中找到資料82及對應的rowid
使用rowid去物理表中讀取記錄資料塊(如果是count或者只select rowid,則最後一次讀取不需要)
在整個索引定位過程中,資料塊的讀取只有3次。既三次I/O後定位到rowid。
而由於Btree索引對結構的利用率很高,定位高效。當1千萬條資料時,Btree索引也是三層結構(依稀記得億級資料才是3層與4層的分水嶺)。定位記錄仍只需要三次I/O,這便是開頭所說的,100條資料和1千萬條資料的定位,在btree索引中的花銷是一樣的。
平衡擴張
除了利用率高、定位高效外,Btree的另一個特點是能夠永遠保持平衡,這與它的擴張方式有關。(unbalanced和hotspot是兩類問題,之前我一直混在一起),先描述下Btree索引的擴張方式:
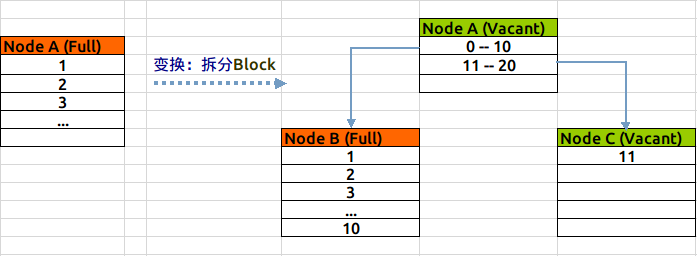
新建一個索引,索引上只會有一個leaf節點,取名為Node A,不斷的向這個leaf節點中插入資料後,直到這個節點滿,這個過程如下圖(綠色表示新建/空閒狀態,紅色表示節點沒有空餘空間):

當Node A滿之後,我們再向表中插入一條記錄,此時索引就需要做拆分處理:會新分配兩個資料塊NodeB & C,如果新插入的值,大於當前最大值,則將Node A中的值全部插入Node B中,將新插入的值放到Node C中;否則按照5-5比例,將已有資料分別插入到NodeB與C中。
無論採用哪種分割方式,之前的leaf節點A,將變成一個root節點,儲存兩個範圍條目,指向B與C,結構如下圖(按第一種拆分形式):
當Node C滿之後,此時 Node A仍有空餘空間存放條目,所以不需要再拆分,而只是新分配一個數據塊Node D,將在Node A中建立指定到Node D的條目:
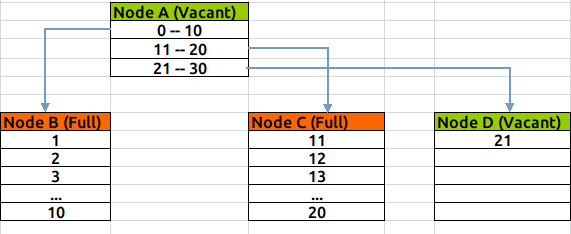
如果當根節點Node A也滿了,則需要進一步拆分:新建Node E&F&G,將Node A中範圍條目拆分到E&F兩個節點中,並建立E&F到BCD節點的關聯,向Node G插入索引值。此時E&F為branch節點,G為leaf節點,A為Root節點:
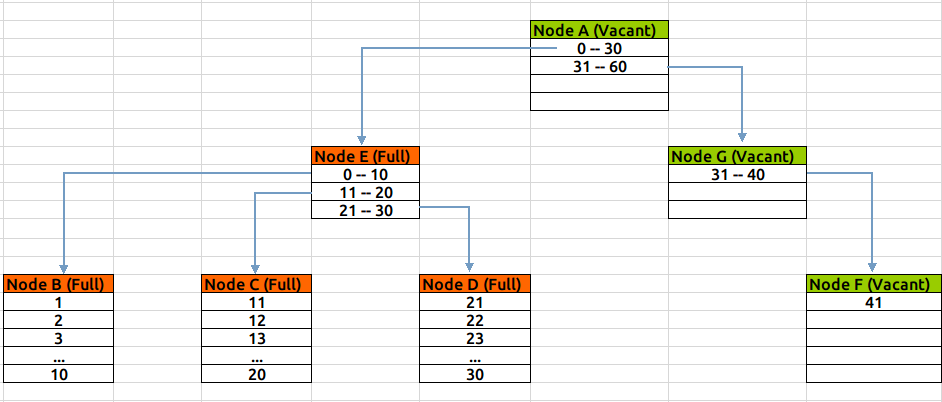
在整個擴張過程中,Btree自身總能保持平衡,Leaf節點的深度能一直保持一致。
實際應用中的一些問題
前面說完了Btree索引的結構與擴張邏輯,接下來講一些Btree索引在應用中的一些問題:
單一方向擴充套件引起的索引競爭(Index Contention)
若索引列使用sequence或者timestamp這類只增不減的資料型別。這種情況下Btree索引的增長方向總是不變的,不斷的向右邊擴充套件,因為新插入的值永遠是最大的。
當一個最大值插入到leaf block中後,leaf block要向上傳播,通知上層節點更新所對應的“值範圍”條目中的最大值,因此所有靠右邊的block(從leaf 到branch甚至root)都需要做更新操作,並且可能因為塊寫滿後執行塊拆分。
如果併發插入多個最大值,則最右邊索引資料塊的的更新與拆分都會存在爭搶,影響效率。在AWR報告中可以通過檢測enq: TX – index contention事件的時間來評估爭搶的影響。解決此類問題可以使用Reverse Index解決,不過會帶來新的問題。
Index Browning 索引枯萎(不知道該怎麼翻譯這個名詞,就是指leaves節點”死”了,樹枯萎了)
其實oracle針對這個問題有優化機制,但優化的不徹底,所以還是要拿出來的說。
我們知道當表中的資料刪除後,索引上對應的索引值是不會刪除的,特別是在一性次刪除大批量資料後,會造成大量的dead leaf掛到索引樹上。考慮以下示例,如果表100以上的資料會部被刪除了,但這些記錄仍在索引中存在,此時若對該列取max():
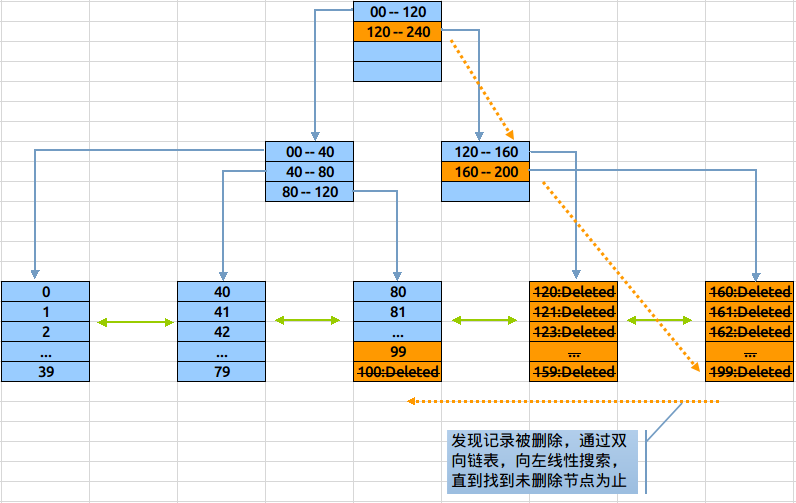
通過與之前相同演算,找到了索引樹上最大的資料塊,按照記錄最大的值應該在這裡,但發現這資料塊裡的資料已經被清空了,與是利用Btree索引的另一個特點:leaves節點是一個雙向列表,若資料沒有找到就去臨近的一個數據塊中看看,在這個資料塊中發現了最大值99。
在計算最大值的過程中,這次的定位多載入了一個數據塊,再極端的情況下,大批量的資料被刪除,就會造成大量訪問這些dead leaves。
針對這個問題的一般解決辦法是重建索引,但記住! 重建索引並不是最優方案,詳細原因可以看看這。使用coalesce語句來整理這些dead leaves到freelist中,就可以避免這些問題。理論上oracle中這步操作是可以自動完成的,但在實際中一次性大量刪除資料後,oracle在短時間內是反應不過來的。
更多資料:
Ask Tom: Possible arcane question on B*Tree indexes as Oracle sees them 有點老了
So When Does An Oracle B-Tree Index Increase In Height
http://docs.oracle.com/cd/E11882_01/server.112/e25789/indexiot.htm#autoId6
http://www.dba-oracle.com/t_index_leaf_block_contention_tuning.htm