
理解OpenShift(3):網路之 SDN
理解OpenShift(1):網路之 Router 和 Route
1. 概況
OpenShift SDN 實現了符合Kubernetes CNI 要求的 OpenShift 叢集中 pod 之間的網路通訊。當前OpenShift 支援兩種SDN網路外掛:ovs-subnet 和 ovs-multitenant。ovs-subnet 未實現租戶之間的網路隔離,這意味著所有租戶之間的pod 都可以互訪,這使得該實現無法用於絕大多數的生產環境。本文中的說明都是針對 ovs-multitenant,它基於 OVS 和 VxLAN 等技術實現了基於專案(project)之間的網路隔離。當使用 ansible 部署 OpenShift 時,預設會啟用ovs-subnet,但是可以在部署完成後修改為 ovs-multitenant。
1.1 OpenShift 叢集的網路設計
要部署一個OpenShift 生產環境,主要的網路規劃和設計如下圖所示:

節點角色:
- Master 節點:只承擔 Master 角色,不承擔Node 角色。主要執行 API 服務、controller manager 服務、etcd 服務、web console 服務等。
- Infra 節點:作為 Node 角色,並設定節點標籤,只用於部署系統基礎服務,包括Registry、Router、Prometheus 以及 EFK 等。
- Node 節點:作為 Node 角色,用於執行使用者業務系統的Pod/容器。
網路型別:
- 外部網路:用於外部訪問。和該網路連線的伺服器或元件需要被分配公網IP地址。
- 管理網路:這是一個內部網路,用於叢集內部 API 訪問。
- IPMI網路:這是一個內部網路,用於管理物理伺服器。
- SDN網路:這是一個內部網路,用於叢集內部Pod 之間的通訊,承載 VxLAN Overlay 流量。
- 儲存網路:這是一個內部網路,用於各節點訪問IP儲存伺服器。
在PoC 或開發測試環境中,管理/SDN/儲存網路可以合併為一個網路。
1.2 Node節點中的網路
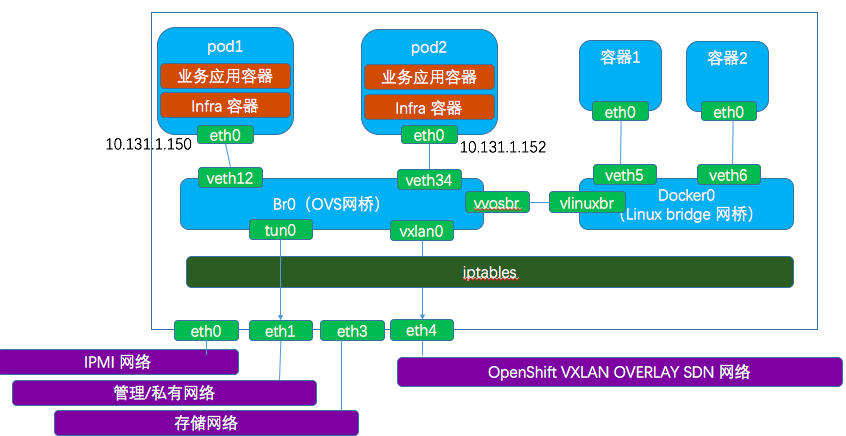
節點上的主要網路裝置:
- br0 - OpenShift 建立和管理的 Open vSwitch 網橋, 它會使用 OpenFlow 規則來實現網路隔離
- vethXXXXX - veth 對,它負責將 pod 的網路名字空間連線到 br0 網橋
- tun0 - 一個 OVS 內部埠,它會被分配本機的 pod 子網的閘道器IP 地址,用於與叢集外部的通訊。iptables 的 NAT 規則會作用於tun0。
- docker0 - Docker 管理和使用的 linux bridge 網橋,通過 veth 對將不受 OpenShift 管理的Docker 容器的網路地址空間連線到 docker0 上。
- vovsbr/vlinuxbr - 將 docker0 和 br0 連線起來的 veth 對,使得Docker 容器能和 OpenShift pod 通訊,以及通過 tun0 訪問外部網路
- vxlan0 - 一個 OVS VXLAN 隧道端點,用於叢集內部 pod 之間的網路通訊。
2. 實現
2.1 pod 網路總體設定流程
Pod 網路總體設定流程如下(來源:OpenShift原始碼簡析之pod網路配置(上)):

簡單說明:
- OpenShift 使用執行在每個節點上的 kubelet 來負責pod 的建立和管理,其中就包括網路配置部分。
- 當 kubelet 接受到 pod 建立請求時,會首先呼叫docker client 來建立容器,然後再呼叫 docker api介面啟動上一步中建立成功的容器。kubelet 在建立 pod 時是先建立一個 infra 容器,配置好該容器的網路,然後建立真正用於業務的應用容器,最後再把業務容器的網路加到infra容器的網路名稱空間中,相當於業務容器共享infra容器的網路名稱空間。業務應用容器和infra容器共同組成一個pod。
- kubelet 使用 CNI 來建立和管理Pod網路(openshift在啟動kubelet時傳遞的引數是--netowrk-plugin=cni)。OpenShift 實現了 CNI 外掛(由 /etc/cni/net.d/80-openshift-network.conf 檔案指定),其二進位制檔案是 /opt/cni/bin/openshift-sdn 。因此,kubelet 通過 CNI 介面來呼叫 openshift sdn 外掛,然後具體做兩部分事情:一是通過 IPAM 獲取 IP 地址,二是設定 OVS(其中,一是通過呼叫 ovs-vsctl 將 infra 容器的主機端虛擬網絡卡加入 br0,二是呼叫 ovs-ofctl 命令來設定規則)。
2.2 OVS 網橋 br0 中的規則
本部分內容主要引用自 OVS 在雲專案中的使用:
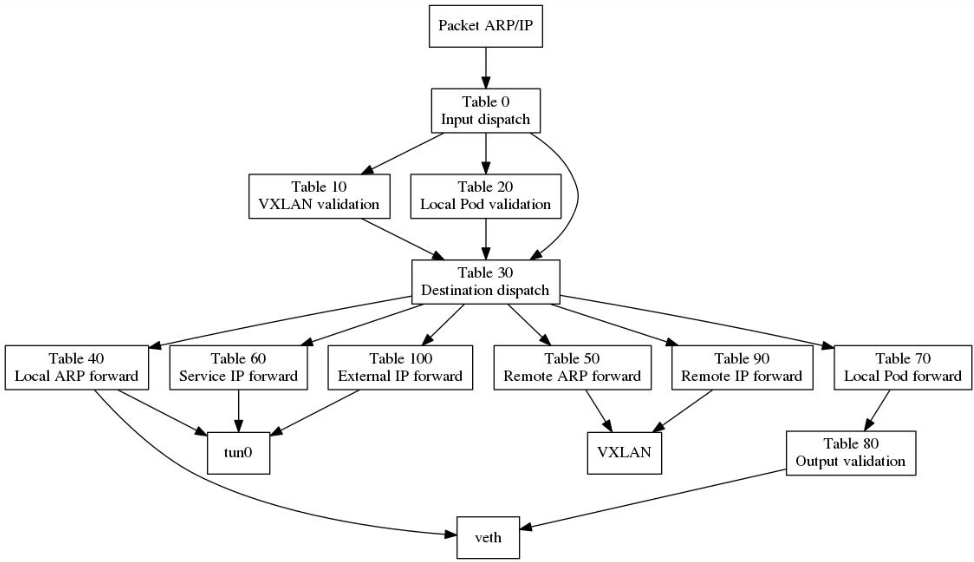
流量規則表:
- table 0: 根據輸入埠(in_port)做入口分流,來自VXLAN隧道的流量轉到表10並將其VXLAN VNI 儲存到 OVS 中供後續使用,從tun0過阿里的(來自本節點或進本節點來做轉發的)流量分流到表30,將剩下的即本節點的容器(來自veth***)發出的流量轉到表20;
- table 10: 做入口合法性檢查,如果隧道的遠端IP(tun_src)是某叢集節點的IP,就認為是合法,繼續轉到table 30去處理;
- table 20: 做入口合法性檢查,如果資料包的源IP(nw_src)與來源埠(in_port)相符,就認為是合法的,設定源專案標記,繼續轉到table 30去處理;如果不一致,即可能存在ARP/IP欺詐,則認為這樣的的資料包是非法的;
- table 30: 資料包的目的(目的IP或ARP請求的IP)做轉發分流,分別轉到table 40~70 去處理;
- table 40: 本地ARP的轉發處理,根據ARP請求的IP地址,從對應的埠(veth)發出;
- table 50: 遠端ARP的轉發處理,根據ARP請求的IP地址,設定VXLAN隧道遠端IP,並從隧道發出;
- table 60: Service的轉發處理,根據目標Service,設定目標專案標記和轉發出口標記,轉發到table 80去處理;
- table 70: 對訪問本地容器的包,做本地IP的轉發處理,根據目標IP,設定目標專案標記和轉發出口標記,轉發到table 80去處理;
- table 80: 做本地的IP包轉出合法性檢查,檢查源專案標記和目標專案標記是否匹配,或者目標專案是否是公開的,如果滿足則轉發;(這裡實現了 OpenShift 網路層面的多租戶隔離機制,實際上是根據專案/project 進行隔離,因為每個專案都會被分配一個 VXLAN VNI,table 80 只有在網路包的VNI和埠的VNI tag 相同才會對網路包進行轉發)
- table 90: 對訪問遠端容器的包,做遠端IP包轉發“定址”,根據目標IP,設定VXLAN隧道遠端IP,並從隧道發出;
- table 100: 做出外網的轉出處理,將資料包從tun0發出。
3. 流程
3.1 同一個節點上的兩個pod 之間的互訪
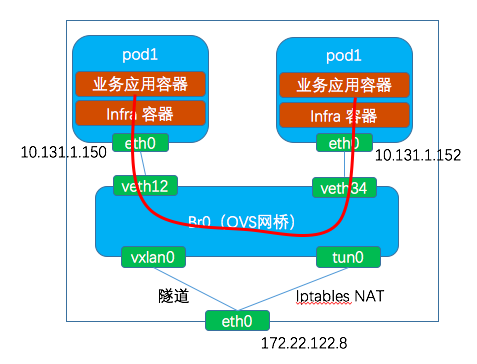
訪問:pod 1 (ip:10.131.1.150)訪問 pod2(10.131.1.152)
網路路徑::pod1的eth0 → veth12 → br0 → veth34 → pod2的eth0。
OVS 流表:
table=0, n_packets=14631632, n_bytes=1604917617, priority=100,ip actions=goto_table:20 table=20, n_packets=166585, n_bytes=12366463, priority=100,ip,in_port=96,nw_src=10.131.1.152 actions=load:0xbe3127->NXM_NX_REG0[],goto_table:21 table=21, n_packets=14671413, n_bytes=1606835395, priority=0 actions=goto_table:30 table=30, n_packets=8585493, n_bytes=898571869, priority=200,ip,nw_dst=10.131.0.0/23 actions=goto_table:70 table=70, n_packets=249967, n_bytes=16177300, priority=100,ip,nw_dst=10.131.1.152 actions=load:0xbe3127->NXM_NX_REG1[],load:0x60->NXM_NX_REG2[],goto_table:80
table=80, n_packets=0, n_bytes=0, priority=100,reg0=0xbe3127,reg1=0xbe3127 actions=output:NXM_NX_REG2[]
table=80, n_packets=0, n_bytes=0, priority=0 actions=drop #不合法的包會被丟棄
表 20 會判斷包型別(IP)、來源地址(nw_src)、進來的埠ID(96),將其 VNI ID(這裡是 0xbe3127)儲存在 REG0 中。
表 70 會根據目的地址,也就是目的 pod 的地址,設定網路包的目的出口標記(REG2)為 0x60,即其ID為 96,同時設定其專案的 VNI ID 到 REG1.
96(veth0612e07f): addr:66:d0:c3:e3:be:cf config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max
我們來查詢其對應的容器中的網絡卡。
[[email protected] cloud-user]# ip link | grep veth0612e07f 443: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue master ovs-system state UP mode DEFAULT
這與pod2容器中的 eth0 正好吻合:
3: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc noqueue state UP link/ether 0a:58:0a:83:01:98 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.131.1.152/23 brd 10.131.1.255 scope global eth0 valid_lft forever preferred_lft forever
表80 會檢查報的來源 VNI ID (REG0)和目的埠的 VNI ID (REG1),將合法的包轉發到表70 設定的出口而已。
3.2 不同節點上的兩個pod 之間的互訪
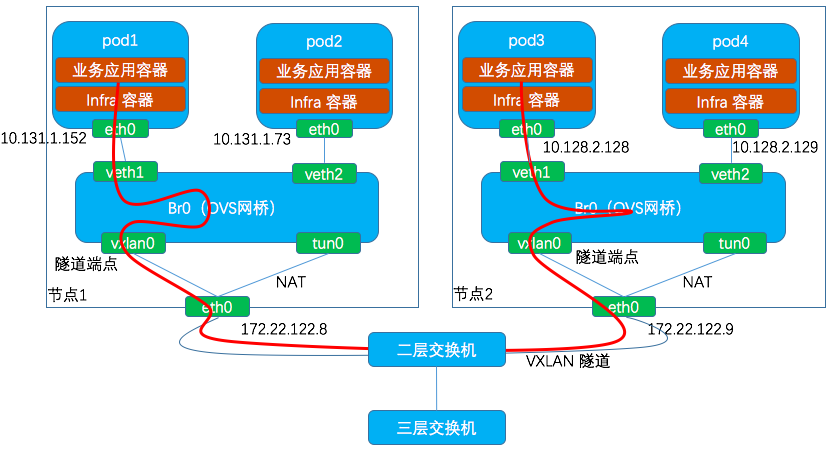
網路路徑:節點1上的Pod1的eth0→veth1→br0→vxlan0→ 節點1的eth0網絡卡→ 節點2的eth0網絡卡→vxlan0→br0→veth1→ Pod3的eth0流表:
傳送端(node1)的OVS 流表:
table=0, n_packets=14703186, n_bytes=1612904326, priority=100,ip actions=goto_table:20
table=20, n_packets=167428, n_bytes=12428845, priority=100,ip,in_port=96,nw_src=10.131.1.152 actions=load:0xbe3127->NXM_NX_REG0[],goto_table:21
table=21, n_packets=14736461, n_bytes=1613954556, priority=0 actions=goto_table:30
table=30, n_packets=1143761, n_bytes=1424533777, priority=100,ip,nw_dst=10.128.0.0/14 actions=goto_table:90
table=90, n_packets=0, n_bytes=0, priority=100,ip,nw_dst=10.128.2.0/23 actions=move:NXM_NX_REG0[]->NXM_NX_TUN_ID[0..31],set_field:172.22.122.9->tun_dst,output:1
- 表20 同樣是將源pod 的 VNI ID 儲存在 REG0 中。
- 表30 會判斷目的地址是不是叢集的大的 pod 的 IP CIDR。
- 表90會設定 VNI ID 為之前儲存在 REG0 中的值,然後根據目的地址的網段(這裡是 10.128.2.0/23),計算出其所在的節點的IP 地址(這裡是 172.22.122.9)並設定為tun_dst,然後發到 vxlan0.
接收端(node2)的OVS 流表:
table=0, n_packets=1980863, n_bytes=1369174876, priority=200,ip,in_port=1,nw_src=10.128.0.0/14 actions=move:NXM_NX_TUN_ID[0..31]->NXM_NX_REG0[],goto_table:10 table=10, n_packets=0, n_bytes=0, priority=100,tun_src=172.22.122.8 actions=goto_table:30
table=30, n_packets=16055284, n_bytes=1616511267, priority=200,ip,nw_dst=10.128.2.0/23 actions=goto_table:70
table=70, n_packets=248860, n_bytes=16158751, priority=100,ip,nw_dst=10.128.2.128 actions=load:0xbe3127->NXM_NX_REG1[],load:0x32->NXM_NX_REG2[],goto_table:80
table=80, n_packets=0, n_bytes=0, priority=100,reg0=0xbe3127,reg1=0xbe3127 actions=output:NXM_NX_REG2[]
- 表0 會將傳送到儲存在 NXM_NX_TUN_ID[0..31] 中的源 VNI ID 取出來儲存到 REG0.
- 表10 會檢查包的來源節點的地址。
- 表30 會檢查包的目的地址是不是本機上 pod 的網段。
- 表70 會根據目的地址,將目的 VNI ID 儲存到 REG1,將目的埠 ID 儲存到 REG2
- 表80 會檢查目的 VNI ID 和源 VNI ID,如果相符的話,則將包轉發到儲存在 REG2 中的目的埠ID 指定的埠。然後包就會通過 veth 管道進入目的 pod。
3.3 pod 內訪問外網
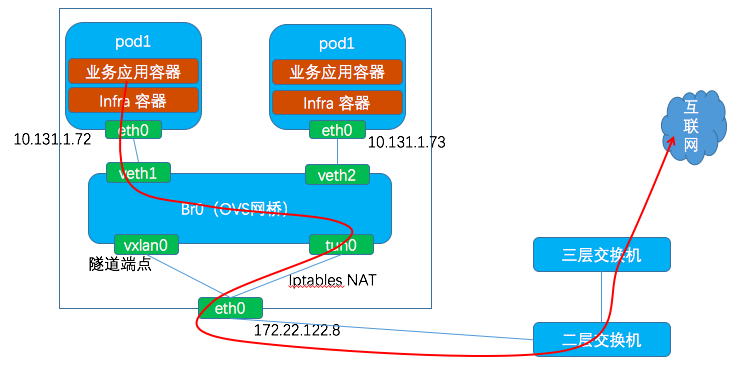
網路路徑:PodA的eth0 → vethA → br0 → tun0 → 通過iptables實現SNAT → 物理節點的 eth0 → 網際網路
NAT:將容器發出的IP包的源IP地址修改為宿主機的 eth0 網絡卡的IP 地址。
OVS 流表:
table=0, n_packets=14618128, n_bytes=1603472372, priority=100,ip actions=goto_table:20 table=20, n_packets=0, n_bytes=0, priority=100,ip,in_port=17,nw_src=10.131.1.73 actions=load:0xfa9a3->NXM_NX_REG0[],goto_table:21 table=21, n_packets=14656675, n_bytes=1605262241, priority=0 actions=goto_table:30 table=30, n_packets=73508, n_bytes=6820206, priority=0,ip actions=goto_table:100 table=100, n_packets=44056, n_bytes=3938540, priority=0 actions=goto_table:101 table=101, n_packets=44056, n_bytes=3938540, priority=0 actions=output:2
表20 會檢查 IP 包的來源埠和IP 地址,並將源專案的 VNI ID 儲存到 REG0.
表101 會將包傳送到埠2 即 tun0. 然後被 iptables 做 NAT 然後傳送到 eth0.
3.4 外網訪問 pod
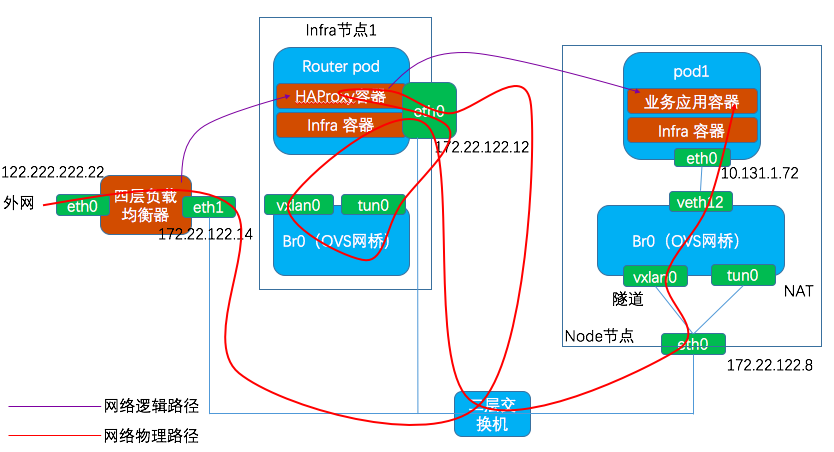
因為 Infra 節點上的 HAproxy 容器採用了 host-network 模式,因此它是直接使用宿主機的 eth0 網絡卡的。
下面是宿主機的路由表:
[[email protected] /]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.22.122.1 0.0.0.0 UG 100 0 0 eth0 10.128.0.0 0.0.0.0 255.252.0.0 U 0 0 0 tun0 169.254.169.254 172.22.122.1 255.255.255.255 UGH 100 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.22.122.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0 172.30.0.0 0.0.0.0 255.255.0.0 U 0 0 0 tun0
從 HAProxy 容器內出來目的地址為業務pod(ip:10.128.2.128)的網路包,根據上面的路由表,其下一跳是 tun0,也就是說它又進入了 OVS 網橋 br0. 對應的 OVS 流表規則為:
ip,in_port=2 actions=goto_table:30
ip,nw_dst=10.128.0.0/14 actions=goto_table:90
ip,nw_dst=10.128.2.0/23 actions=move:NXM_NX_REG0[]->NXM_NX_TUN_ID[0..31],set_field:172.22.122.9->tun_dst,output:1
可見它最終又被髮到了埠1 即 vxlan0,它會負責做 vxlan 封包,並通過 eth0 網絡卡發出去。
3.5 彙總
總體來說,OVS 中的流表根據網路包的目的地址將其分為四類:
- 到本地pod的,直接在 br0 中轉發。
- 到本叢集pod 的,經過 br0 後發到 vxlan0,封裝為 vxlan udp 包經物理網絡卡發到對方節點。
- 到本地不受OpenShift SDN管理的docker容器的,還未研究。
- 到叢集外的,經過 br0 後發到 tun0,做 SNAT,然後經物理網絡卡發出。

4. 專案(project)級別的網路隔離
4.1 原理
OpenShift 中的網路隔離是在專案(project)級別實現的。OpenShfit 預設的專案 『default』的 VNID (Virtual Network ID )為0,表明它是一個特權專案,因為它可以發動網路包到其它所有專案,也能接受其它所有專案的pod發來的網路包。其它專案都會有一個非0的 VNID。在 OpenShift ovs-multitenant 實現中,非0 VNID 的專案之間的網路是不通的。
從一個本地 pod 發出的所有網路流量,在它進入 OVS 網橋時,都會被打上它所通過的 OVS 埠ID相對應的 VNID。port:VNID 對映會在pod 建立時通過查詢master 上的 etcd 來確定。從其它節點通過 VXLAN發過來的網路包都會帶有發出它的pod 所在專案的 VNID。
根據上面的分析,OVS 網橋中的 OpenFlow 規則會阻止帶有與目標埠上的 VNID 不同的網路包的投遞(VNID 0 除外)。這就保證了專案之間的網路流量是互相隔離的。
4.2 實驗
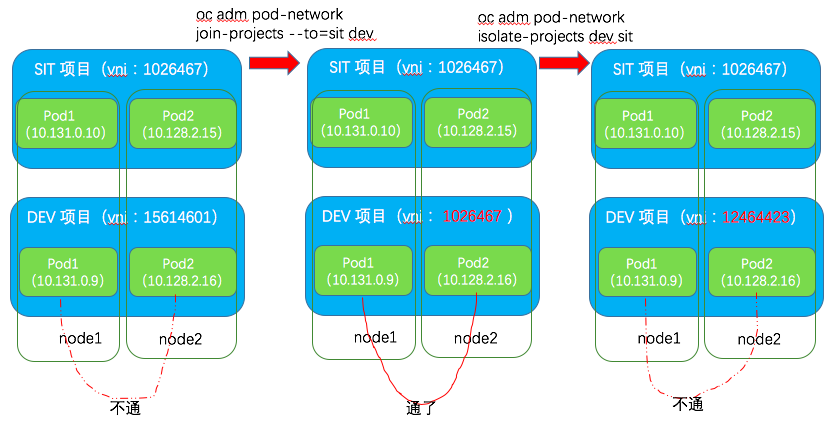
下圖顯示了兩個專案之間的三種網路狀態:
- 左圖顯示的是預設狀態:SIT 專案和 Dev 專案之間的 pod 無法訪問。根據前面對 OVS 流表的分析,表80 會檢查IP 包的來源Pod的專案 VNI ID 和目標Pod的專案 VNI ID。如果兩者不符合,這些IP網路包就會被丟棄。
- 中間圖顯示的是打通這兩個專案的網路:通過執行 oc adm pod-network join-projects 命令,將兩個專案連線在一起,結果就是 DEV 專案的 VNI ID 變成了 SIT 專案的 VNI ID。這時候兩個專案中的 pod 網路就通了。
- 右圖顯示的是分離這兩個專案的網路:通過執行 oc adm pod-network isolate-projects 命令,將兩個專案分離,其結果是 DEV 專案被分配了新的 VNI ID。此時兩個專案中的pod 又不能互通了。
參考文件:
- http://www.openvswitch.org/support/dist-docs-2.5/ovs-ofctl.8.html
- OVS 在雲專案中的使用 (https://medoc.readthedocs.io/en/latest/docs/ovs/sharing/cloud_usage.html)
- 解析 | OpenShift原始碼簡析之pod網路配置
- Troubeshooting OpenShift SDN (https://docs.openshift.com/container-platform/3.11/admin_guide/sdn_troubleshooting.html)
- https://blog.openshift.com/openshift-container-platform-reference-architecture-implementation-guides/
- https://github.com/openshift/openshift-sdn/blob/master/ISOLATION.md
感謝您的閱讀,歡迎關注我的微信公眾號:
