
Mysql面試指南(一)
阿新 • • 發佈:2018-12-06
什麼是資料庫索引?資料庫索引型別有哪些?什麼是最左字首原則?索引演算法有哪些?有什麼區別?
資料庫索引
定義:索引是對資料庫表中一列或多列的值進行排序的一種結構。一個非常恰當的比喻就是書的目錄頁與書的正文內容之間的關係,為了方便查詢書中的內容,通過對內容建立索引形成目錄。索引是一個檔案,它是要佔據物理空間的。
資料庫索引型別
- 主鍵索引:資料列不能重複,不允許有NULL,一個表只能有一個主鍵
- 唯一索引:資料列表不允許重複,允許為NULL,一個表可以建立多個唯一索引
- 普通索引:基本的索引型別,沒有唯一性的限制,允許為NULL
- 全文索引:通過
Alter TABLE table_name ADD FULLTEXT(column);建立全文索引
最左字首
- 定義:就是最左優先,在建立多列索引時,要根據業務需求,where子句中使用最頻繁的一列放在最左邊
- 生效原則:組合索引的生效原則是 從前往後依次使用生效,如果中間某個索引沒有使用,那麼斷點前面的索引部分起作用,斷點後面的索引沒有起作用
比如:
where a=3 and b=45 and c=5 .... 這種三個索引順序使用中間沒有斷點,全部發揮作用;
where a=3 and c=5... 這種情況下b就是斷點,a發揮了效果,c沒有效果
where b=3 and c=4... 這種情況下a就是斷點,在a後面的索引都沒有發揮作用,這種寫法聯合索引沒有發揮任何效果;
where 索引演算法
- BTree:BTree是最常用的mysql資料庫索引演算法,也是mysql預設的演算法。因為它不僅可以被用在=,>,>=,<,<=和between這些比較操作符上,而且還可以用於like操作符,只要它的查詢條件是一個不以萬用字元開頭的常量
- Hash:Hash索引只能用於對等比較,例如=,<=>(相當於=)操作符。由於是一次定位資料,不像BTree索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次IO訪問,所以檢索效率遠高於BTree索引
- 區別:BTree索引不僅可以用在=,>,>=,<,<=和between這些比較操作符上,而且還可以用於like操作符,而Hash索引只能用於對等比較,例如=,<=>(相當於=)操作符
索引設計的原則是什麼?
- 適合索引的列是出現在where子句中的列,或者連線子句中指定的列
- 基數較小的類,索引效果較差,沒有必要在此列建立索引
- 使用短索引,如果長字串列進行索引,應該指定一個字首長度,這樣能夠節省大量索引空間
- 不用過度索引。索引需要額外的磁碟空間,並降低寫操作的效能。在修改表內容的時候,索引會進行更新甚至重構,索引列越多,這個時間就會越長。所以只保持需要的索引有利於查詢即可
如何定位和優化SQL語句的效能問題?
- 對於低效能的SQL語句的定位,最重要也是最有效的方法就是使用執行計劃
- 我們知道,不管是哪種資料庫或者哪種資料庫引擎,在對一條SQL語句進行執行的過程中都會做很多相關的優化,對於查詢語句,最重要的優化方式就是使用索引
- 而執行計劃,就是顯示資料庫引擎對於SQL語句的執行的詳細情況,其中包含是否使用索引,使用了什麼索引,使用索引的相關資訊等
執行計劃:
定義:explain主要是用來獲取一個query的執行計劃,描述mysql如何執行查詢操作、執行順序,使用到的索引,以及mysql成功返回結果集需要執行的行數。可以幫助我們分析 select 語句,讓我們知道查詢效率低下的原因,從而改進我們的查詢,讓查詢優化器能夠更好的工作。

- id:包含一組數字,表示查詢中執行select子句或操作表的順序
id相同執行順序由上至下。 id不同,id值越大優先順序越高,越先被執行。 id為null時表示一個結果集,不需要使用它查詢,常出現在包含union等查詢語句中。 - select_type:表示每個子查詢的查詢型別,一些常見的查詢型別
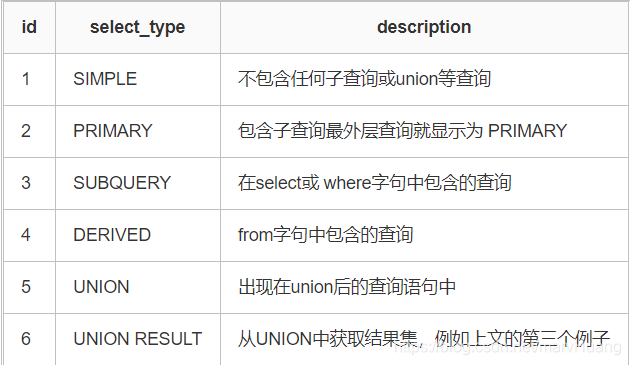
- table:顯示的查詢表名,如果查詢使用了別名,那麼這裡顯示的是別名,如果不涉及對資料表的操作,那麼這顯示為null,如果顯示為尖括號括起來的
<derived N>就表示這個是臨時表,後邊的N就是執行計劃中的id,表示結果來自於這個查詢產生。如果是尖括號括起來的<union M,N>,與<derived N>類似,也是一個臨時表,表示這個結果來自於union查詢的id為M,N的結果集 - partitions:表分割槽、表建立的時候可以指定通過那個列進行表分割槽,例如:
create table tmp ( id int unsigned not null AUTO_INCREMENT, name varchar(255), PRIMARY KEY (id) ) engine = innodb partition by key (id) partitions 5; - type:表示MySQL在表中找到所需行的方式,又稱“訪問型別”,常見型別如下:

- possible_keys:可能使用的索引,注意不一定會使用。查詢涉及到的欄位上若存在索引,則該索引將被列出來。當該列為 NULL時就要考慮當前的SQL是否需要優化了
- key:在查詢中實際使用的索引,若沒有使用索引,顯示為NULL
- key_len:用於處理查詢的索引長度,如果是單列索引,那就整個索引長度算進去,如果是多列索引,那麼查詢不一定都能使用到所有的列,具體使用到了多少個列的索引,這裡就會計算進去,沒有使用到的列,這裡不會計算進去。另外,key_len只計算where條件用到的索引長度,而排序和分組就算用到了索引,也不會計算到key_len中
- ref:表示上述表的連線匹配條件,即哪些列或常量被用於查詢索引列上的值。如果是使用的常數等值查詢,這裡會顯示const,如果是連線查詢,被驅動表的執行計劃這裡會顯示驅動表的關聯欄位,如果是條件使用了表示式或者函式,或者條件列發生了內部隱式轉換,這裡可能顯示為func
- rows:執行計劃中估算的掃描行數,不是精確值
- filtered:表示儲存引擎返回的資料在server層過濾後,剩下多少滿足查詢的記錄數量的比例,注意是百分比,不是具體記錄數
- extra:可以顯示的資訊非常多,有幾十種,常用的有:

某個表有近千萬資料,CRUD比較慢,如何優化?分庫分表了是怎麼做的?分表分庫了有什麼問題?有用到中介軟體麼?他們的原理知道麼?
- 資料有千萬級別之多,佔用的儲存空間比較大,可想而知它不會儲存在一塊連續的物理空間上,而是鏈式儲存在多個碎片的物理空間。可能對於長字串的比較,就用更多的時間查詢和比較,這就導致用更多的時間。因此,優化方法有:
1、可以做表拆分,減少單表字段數量,優化表結構
2、在保證主鍵有效的情況下,檢查主鍵索引的欄位順序,使得查詢語句中條件的欄位順序和主鍵索引的欄位順序保持一致 - 垂直分表
垂直分表也就是“大表拆小表”,基於列欄位進行的。一般是表中的欄位較多,將不常用的, 資料較大,長度較長(比如text型別欄位)的拆分到“擴充套件表“。 一般是針對那種幾百列的大表,也避免查詢時,資料量太大造成的“跨頁”問題。
垂直分庫針對的是一個系統中的不同業務進行拆分,比如使用者User一個庫,商品Producet一個庫,訂單Order一個庫。 切分後,要放在多個伺服器上,而不是一個伺服器上。為什麼? 我們想象一下,一個購物網站對外提供服務,會有使用者,商品,訂單等的CRUD。沒拆分之前, 全部都是落到單一的庫上的,這會讓資料庫的單庫處理能力成為瓶頸。按垂直分庫後,如果還是放在一個數據庫伺服器上, 隨著使用者量增大,這會讓單個數據庫的處理能力成為瓶頸,還有單個伺服器的磁碟空間,記憶體,tps等非常吃緊。 所以我們要拆分到多個伺服器上,這樣上面的問題都解決了,以後也不會面對單機資源問題。
資料庫業務層面的拆分,和服務的“治理”,“降級”機制類似,也能對不同業務的資料分別的進行管理,維護,監控,擴充套件等。 資料庫往往最容易成為應用系統的瓶頸,而資料庫本身屬於“有狀態”的,相對於Web和應用伺服器來講,是比較難實現“橫向擴充套件”的。 資料庫的連線資源比較寶貴且單機處理能力也有限,在高併發場景下,垂直分庫一定程度上能夠突破IO、連線數及單機硬體資源的瓶頸。 - 水平分表
針對資料量巨大的單張表(比如訂單表),按照某種規則(RANGE,HASH取模等),切分到多張表裡面去。 但是這些表還是在同一個庫中,所以庫級別的資料庫操作還是有IO瓶頸。不建議採用,因此使用:
水平分庫分表
將單張表的資料切分到多個伺服器上去,每個伺服器具有相應的庫與表,只是表中資料集合不同。 水平分庫分表能夠有效的緩解單機和單庫的效能瓶頸和壓力,突破IO、連線數、硬體資源等的瓶頸
水平分庫分表切分規則
1、RANGE從0到10000一個表,10001到20000一個表;
2、HASH取模:例如一個商場系統,一般都是將使用者,訂單作為主表,然後將和它們相關的作為附表,這樣不會造成跨庫事務之類的問題。 取使用者id,然後hash取模,分配到不同的資料庫上;
3、地理區域:比如按照華東,華南,華北這樣來區分業務,七牛雲應該就是如此;
4、時間:按照時間切分,就是將6個月前,甚至一年前的資料切出去放到另外的一張表,因為隨著時間流逝,這些表的資料 被查詢的概率變小,所以沒必要和“熱資料”放在一起,這個也是“冷熱資料分離”; - 分庫分表後面臨的問題
- 事務支援:分庫分表後,就成了分散式事務了。如果依賴資料庫本身的分散式事務管理功能去執行事務,將付出高昂的效能代價; 如果由應用程式去協助控制,形成程式邏輯上的事務,又會造成程式設計方面的負擔
- 跨庫join:只要是進行切分,跨節點Join的問題是不可避免的。但是良好的設計和切分卻可以減少此類情況的發生。解決這一問題的普遍做法是分兩次查詢實現。在第一次查詢的結果集中找出關聯資料的id,根據這些id發起第二次請求得到關聯資料
- 跨節點的count,order by,group by以及聚合函式問題:這些是一類問題,因為它們都需要基於全部資料集合進行計算。多數的代理都不會自動處理合並工作。解決方案:與解決跨節點join問題的類似,分別在各個節點上得到結果後在應用程式端進行合併。和join不同的是每個結點的查詢可以並行執行,因此很多時候它的速度要比單一大表快很多。但如果結果集很大,對應用程式記憶體的消耗是一個問題
- 資料遷移,容量規劃,擴容等問題
- ID問題
- 一旦資料庫被切分到多個物理結點上,我們將不能再依賴資料庫自身的主鍵生成機制。一方面,某個分割槽資料庫自生成的ID無法保證在全域性上是唯一的;另一方面,應用程式在插入資料之前需要先獲得ID,以便進行SQL路由
- 一些常見的主鍵生成策略
- UUID:使用UUID作主鍵是最簡單的方案,但是缺點也是非常明顯的。由於UUID非常的長,除佔用大量儲存空間外,最主要的問題是在索引上,在建立索引和基於索引進行查詢時都存在效能問題
- Twitter的分散式自增ID演算法Snowflake:在分散式系統中,需要生成全域性UID的場合還是比較多的,twitter的snowflake解決了這種需求,實現也還是很簡單的,除去配置資訊,核心程式碼就是毫秒級時間41位 機器ID 10位 毫秒內序列12位
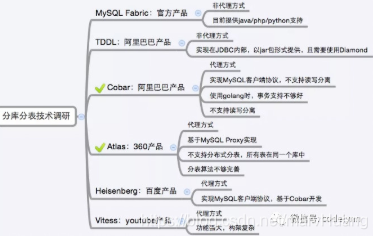
- 中介軟體推薦
mysql中in和exists 區別
- mysql中的in語句是把外表和內表作hash 連線,而exists語句是對外表作loop迴圈,每次loop迴圈再對內表進行查詢
- 關於exists和in語句的效率比較,是要看情況的:
1、如果查詢的兩個表大小相當,那麼用in和exists差別不大
2、如果兩個表中一個較小,一個是大表,則子查詢表大的用exists,子查詢表小的用in
3、not in 和not exists如果查詢語句使用了not in 那麼內外表都進行全表掃描,沒有用到索引;而not extsts的子查詢依然能用到表上的索引。所以無論那個表大,用not exists都比not in要快
文章參考:
https://www.cnblogs.com/fishlynn/p/9674793.html
https://blog.csdn.net/u012410733/article/details/66472157