
編寫一個模組,含char_freq_table()函式。傳入檔名,統計檔案中的所有英文字元的出現次數,忽略大小寫的區別,並根據次數的高低列印字元以及頻率到螢幕
阿新 • • 發佈:2018-12-06
編寫一個模組,包含char_freq_table()函式。傳入一個檔名,統計檔案中的所有
英文字元的出現次數,忽略大小寫的區別,並根據次數的高低列印字元以及頻率到
螢幕
如果有更好的思路,歡迎交流
因為時間問題就直接寫在一個檔案裡了,主要實現了統計檔案中的所出現的各個字元以及他的次數,文字如下:
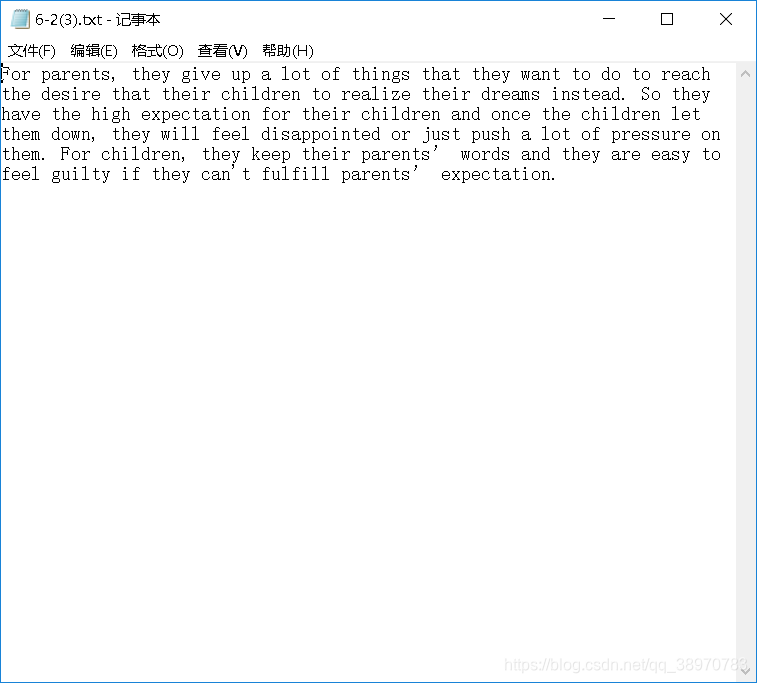
在這期間使用了多個列表,基本思路如下:
開啟檔案,然後對檔案進行遍歷,將檔案內容儲存到temp1中,
然後使用迴圈對齊進行遍歷,如果遇到的為大寫字母用ascII碼將其轉化為小寫存入temp2中,
之後將temp1中出現的字元依次存入a中,並在b中存入此字元在temp1和temp2中總共出現的次數即為大寫和小寫的次數
使用zip函式將a以及b兩個列表整合成一個帶鍵值以及權值的字典,之後依次輸出字典中的資料。
''' 測試版1:略有缺點,如果檔案中有空格以及其他字元也會輸出 ''' def char_freq_table(name): file=open(name,'r') temp1=list(file.read()) temp2=list() a=[] b=[] for i in temp1: if i in a: continue else: if 'A'<=i<='Z' : i=chr(ord(i)+32) temp2.append(i) a.append(i) b.append(temp1.count(i)+temp2.count(i)) c=dict(zip(a,b)) d=sorted(c.items(),key=lambda item:item[1],reverse=True) for j in d: print (j) x=input('請輸入檔名:') char_freq_table(x)
執行結果如下
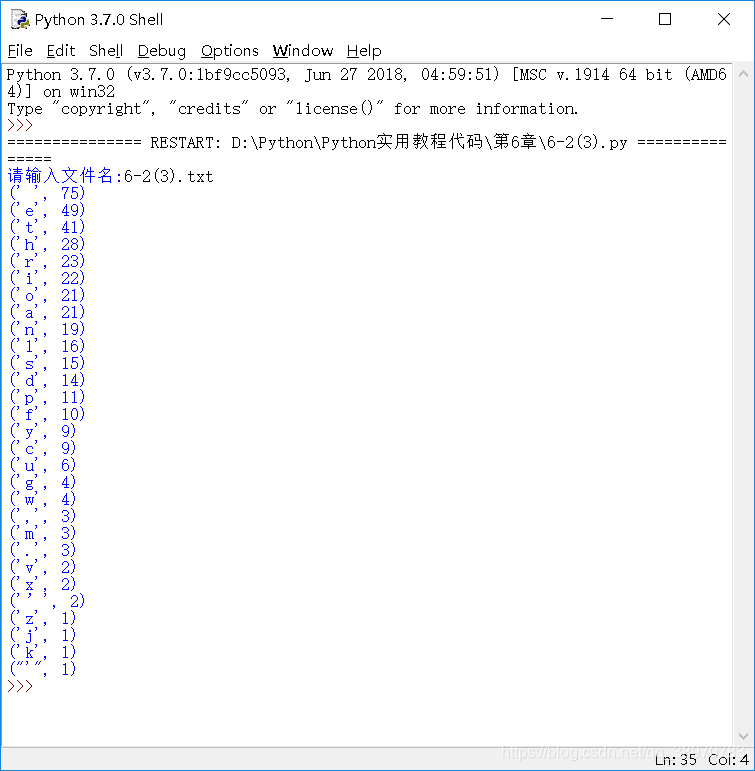
之後對此進行了改進,只輸出字元,其他東西不會輸出,在迴圈中,多加了個if判斷語句,程式碼如下:
def char_freq_table(name): file=open(name,'r') temp1=list(file.read()) temp2=list() a=[] b=[] c={} for i in temp1: if i in a: continue else: if ((i<'A'or i>'Z') and (i<'a' or i>'z')): continue else: if 'A'<=i<='Z' : i=chr(ord(i)+32) temp2.append(i) a.append(i) b.append(temp1.count(i)+temp2.count(i)) c=dict(zip(a,b)) d=sorted(c.items(),key=lambda item:item[1],reverse=True) for j in d: print (j) x=input('請輸入檔名:') char_freq_table(x)
