
學習ConcurrentLinkedDeque原始碼
可以看到ConcurrentLinkedDeque實現的介面有Serializable, Iterable<E>, Collection<E>, Deque<E>, Queue<E>,相應的就有各個介面實現的特性,這個類比較突出的特性可能是Concurrent這個詞啦。
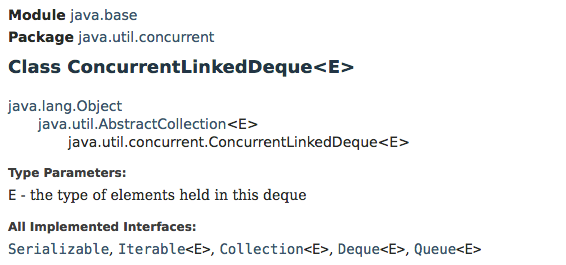
基於連結節點的無界ConcurrentLinkedDeque(併發雙端佇列)。併發插入,刪除和訪問操作可跨多個執行緒安全執行。當許多執行緒共享對公共集合的訪問權時,ConcurrentLinkedDeque是一個合適的選擇。與大多數其他併發集合實現一樣,此類不允許使用null元素。
其中Iterators 和 spliterators 是弱一致的。
主要有兩個屬性欄位,head表示佇列的隊首元素,tail表示隊尾。
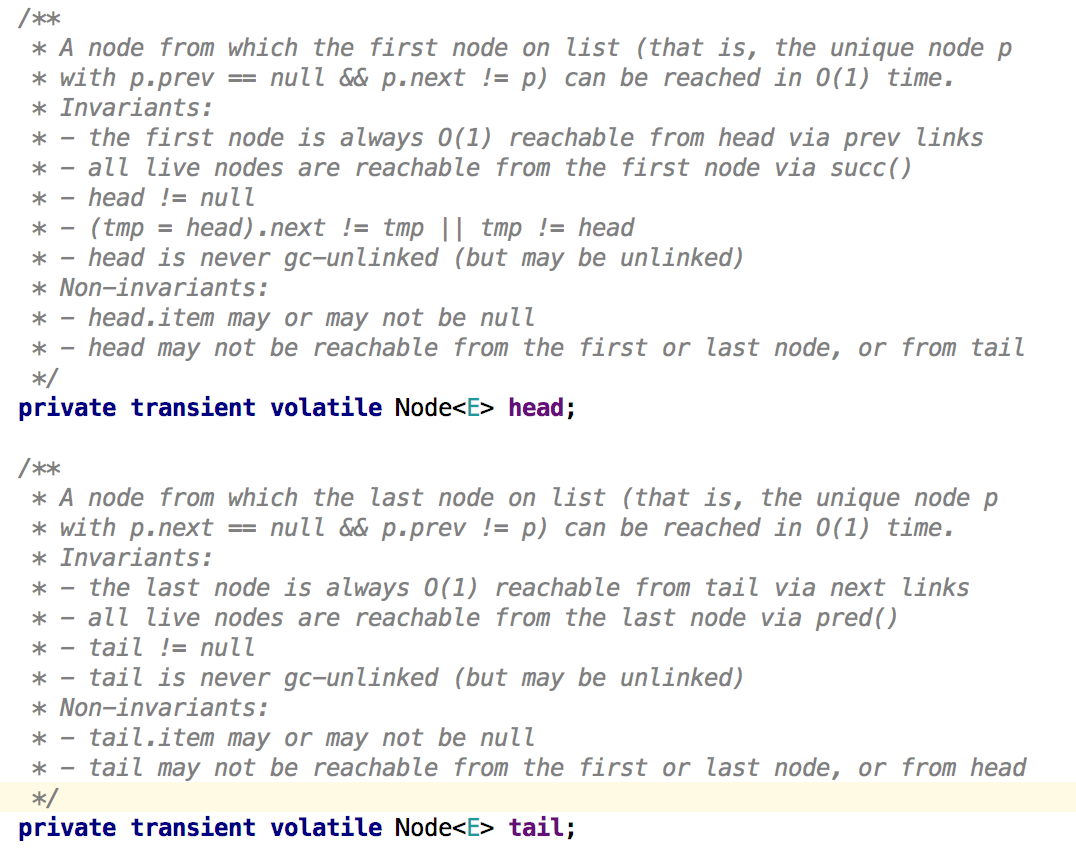
在網上copy一個圖:

ConcurrentLinkedDeque的建構函式只有兩個

ConcurrentLinkedDeque當然可以用來當queue和stack實現來用,但是我們主要來看看deque的介面實現,前後兩種方法實現的方式一樣的,但是返回值會有區分。
| 隊首入隊 | addFirst(e) | offerFirst(e) |
| 隊首出隊 | removeFirst() | pollFirst() |
| 隊首讀取 | getFirst() | peekFirst() |
| 隊尾入隊 | addLast(e) | offerLast(e) |
| 隊尾出隊 | removeLast() | pollLast() |
| 隊尾讀取 | getLast() | peekLast() |
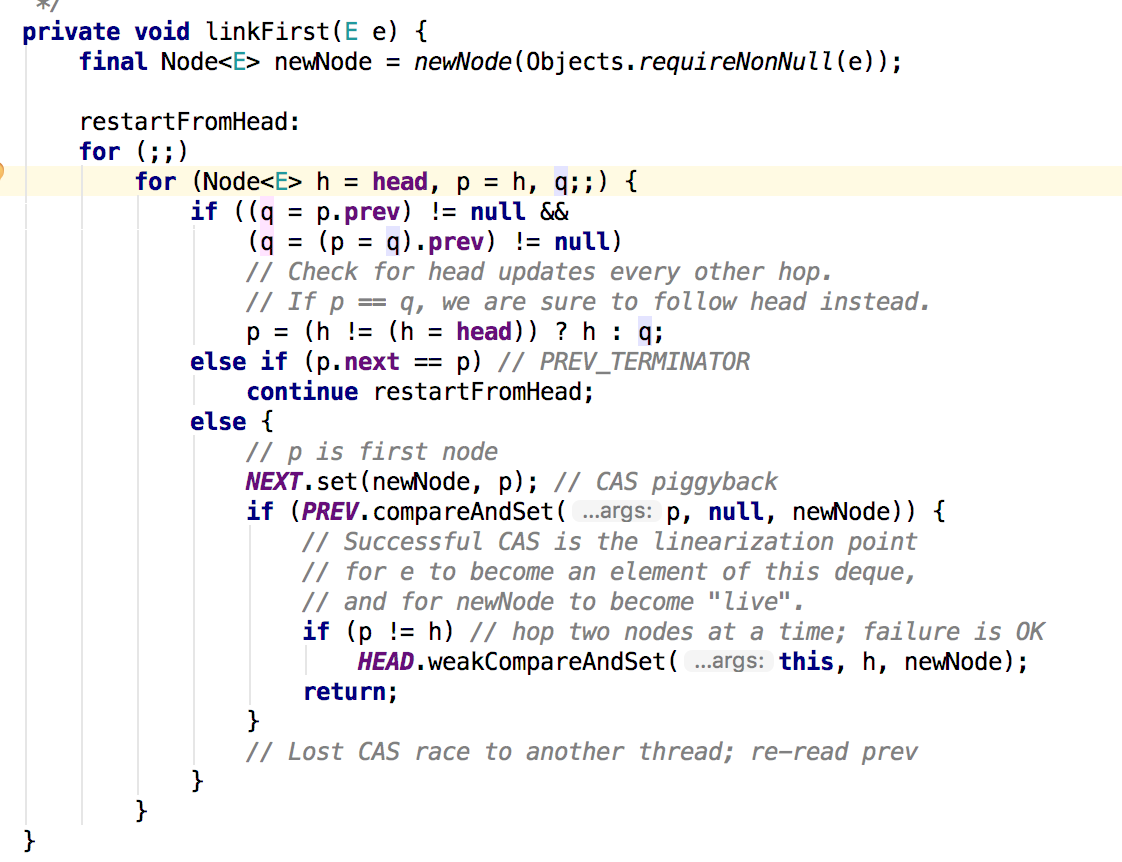
隊首入隊,用的都是private void linkFirst(E e) ,這裡會先建立一個newNode,然後使用CAS方式入隊,這裡感到奇怪的p = h,q這個寫法,那麼這是隻是定義一個名字,然後告訴他你是什麼型別?這好有迷惑性呀。隊尾入隊也是類似的,我想這個演算法極端情況的效率怎麼樣呢?
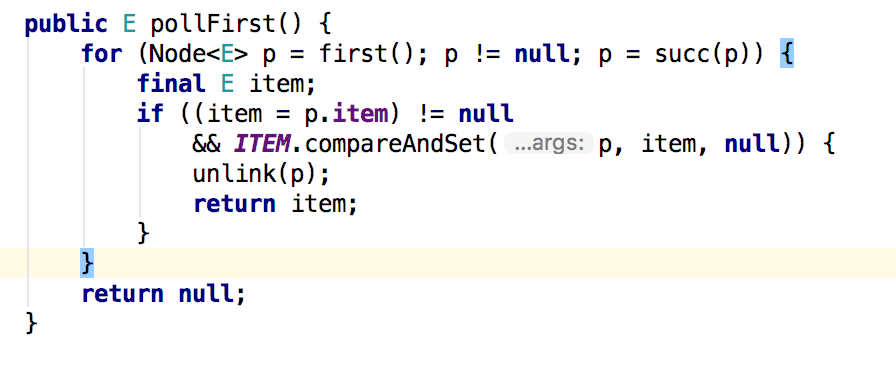
讓我們看看出隊的操作吧,然後執行unlink操作,刪除元素,裡面的操作還是有點複雜的。隊尾的操作也類似。
讀取操作比上面的操作應該簡單一些吧,其中有個succ操作來獲取隊首元素。

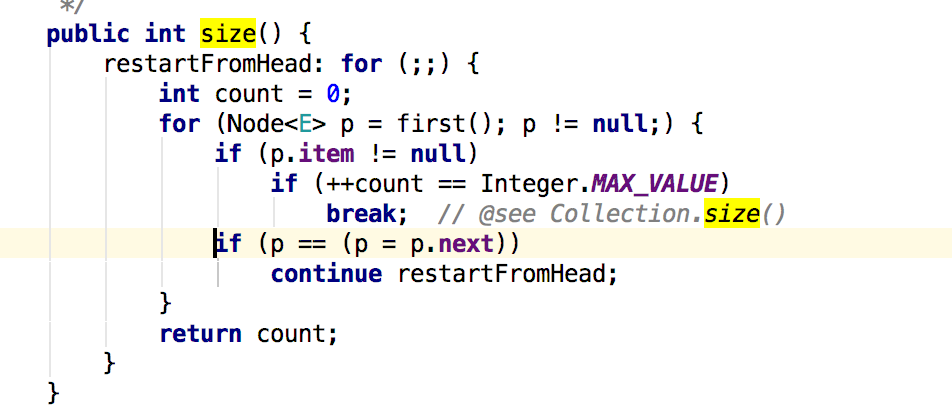
請注意,與大多數集合不同,size方法不是恆定時間操作。由於這些deques的非同步性質,確定元素的當前數量需要遍歷元素,因此如果在遍歷期間修改此集合,則可能報告不準確的結果。備註裡面還寫著在併發操作中,可能這個方法沒什麼用。不過這裡p ==(p=p.next)是什麼情況?
新增,刪除或檢查多個元素的批量操作,例如addAll(java.util.Collection <?extends E>),removeIf(java.util.function.Predicate <?super E>)或forEach(java.util。function.Consumer <?super E>),不保證以原子方式執行。例如,與addAll操作併發的forEach遍歷可能只會觀察到一些新增的元素。
參考:
https://www.jianshu.com/p/602b3240afaf
https://blog.csdn.net/chenleixing/article/details/44143641
https://docs.oracle.com/javase/9/docs/api/java/util/concurrent/ConcurrentLinkedDeque.html
https://segmentfault.com/a/1190000016284649