
從Watson看AI平臺的架構設計
摘要:本文分析IBM Watson在技術架構上所面臨的問題及解決辦法,總結了人工智慧平臺在走向產品化需要面對的諸多挑戰。最後提出了以雲端計算PaaS容器服務平臺為基礎,上層使用SaaS的服務架構來搭建企業級AI平臺,是技術上可行也是較經濟的一種解決方案。
前言
2016年被認為是人工智慧的元年,隨著AlphaGo戰勝韓國棋手李世石,人工智慧產業徹底站到了風口上。然而人工智慧研發團隊的核心技術人員通常都是掌握了某些核心演算法的科學家,他們對於平臺的架構設計,工程實施並不一定經驗豐富。 如何基於核心AI能力搭建出一套可持續運營又具有業務成長性的企業級AI平臺呢? 筆者以IBM的 Watson為案例,來分析架構設計上需要考慮的方方面面。
Watson解決那些問題?
IBM的Watson在2011年在美國危險邊緣(Jeopardy)真人秀中以77147分的成績戰勝兩位人類選手贏得100萬美金頭獎而一舉成名。在這個故事背後,IBM解決了那些人工智慧領域的問題呢?我們先來看看 Jeopardy這個節目的競賽規則。作為美式智力問答節目,Jeopardy的題目由若干詞條或短句組成,讓競賽者找出這些線索所描述的人或事物,答案需要以提問的形式提供給主持人。 例如題目問“在撲克牌遊戲中,五張同一花色順聯的牌” 。 選手的正確回答是“什麼叫同花順”?這就要求參賽選手要有知識的廣度和搶答的反應速度,並且還需要有腦筋急轉彎的聯想歸納能力。Watson能在不聯網的情況下,處在人類日常的環境當中,去理解、搶答、贏得比賽,主要在人工智慧3個領域取得突破:
- 理解自然語言的能力。雖然在比賽中Watson為了提高理解的精確度關閉了語音翻譯功能,使用文字作為輸入方式(遊戲規則允許選手閱讀顯示屏上的問題,所以並不算Watson違規),但它仍然需要準確的解讀人類措辭含糊的提問。
- 非結構化資料的處理和機器學習能力。接下來Watson要從百科全書般浩繁的文件中學習儲備知識。
- 快速運算。在比賽中從知識庫中找到備選項, 通過複雜的判斷邏輯從備選項中選擇正確度最高的答案。要達到超過人腦的推理運算速度,快速準確的用人類語音給出最終答案。
Watson是如何執行的?
從賽後Watson研發團隊DeepQA在人工智慧領域頂級刊物AI Magazine上的公佈論文《Building Watson: An Overview of the DeepQA Project》 (參考1)和維基百科(參考2 ) 上的內容, Watson問題分析的工作流程如圖1:
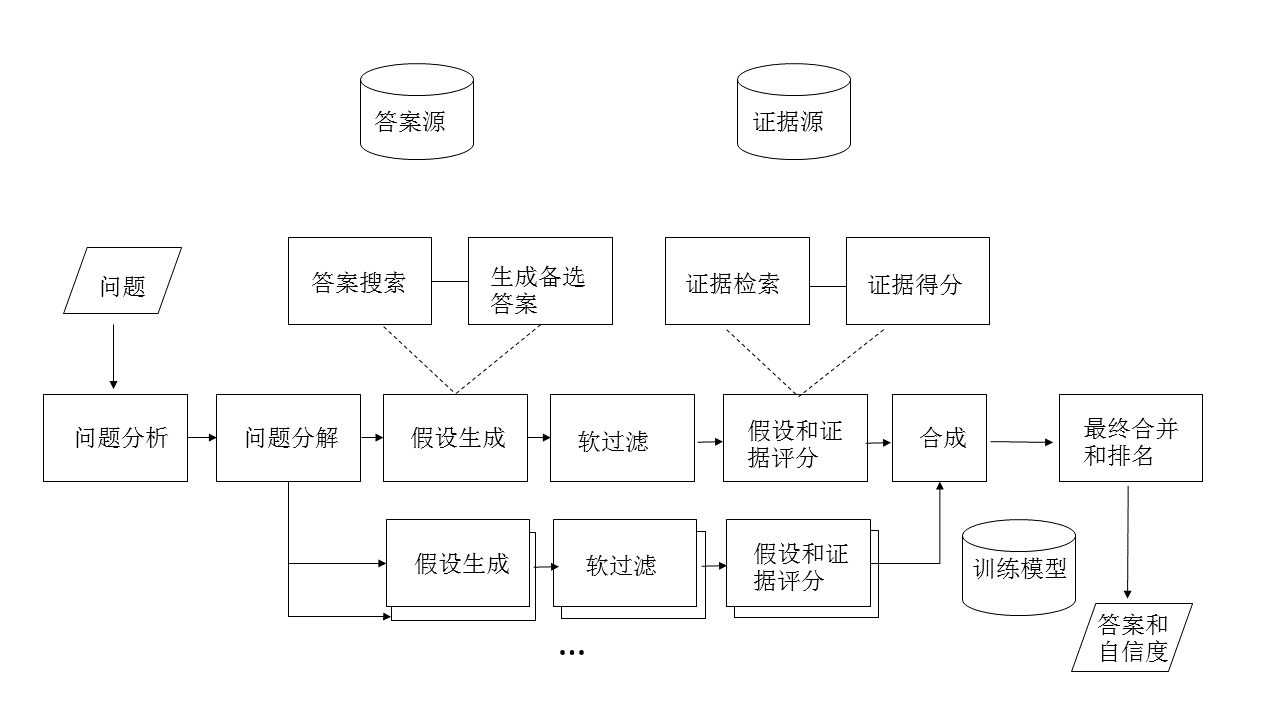
因為國內已有介紹DeepQA這篇論文的文章(參考3),筆者就不詳細展開。從上圖看Watson的技術架構可以歸納如下(圖2):
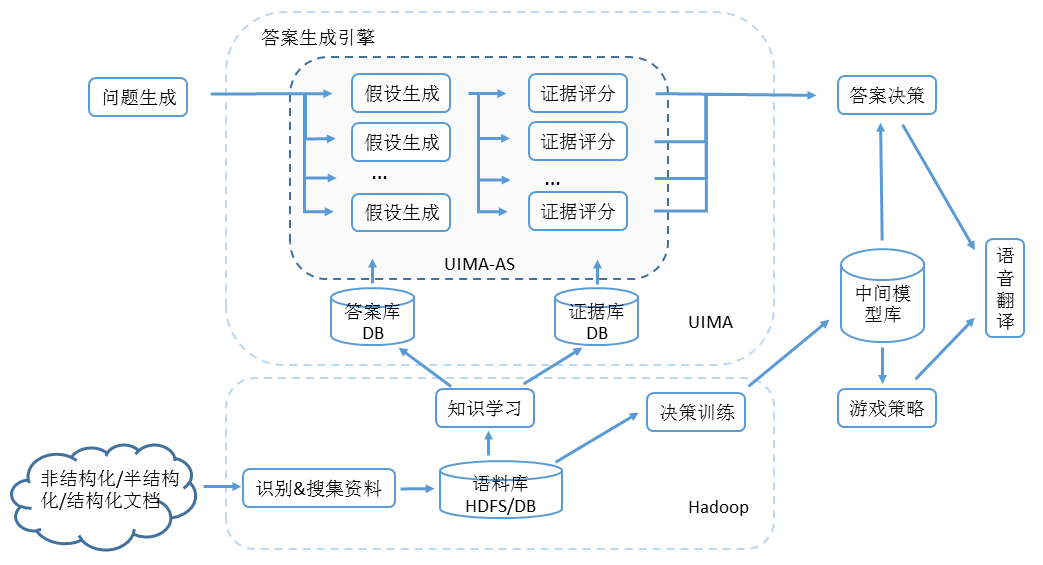
- 問題生成模組:系統嘗試瞭解問題是什麼,並執行初步分析,以確定問題將如何由系統的其餘部分處理。首先分析問題,對問題的型別,回答方式等進行分類,再把問題分解成一系列假設可能的子問題。
- 答案生成引擎: 對於輸入的假設,在答案源進行搜尋、過濾掉評分過低的備選答案、根據備選答案搜尋證據、最終把備選答案和證據合併彙總到統一的資料模型中。可以說這是Watson最具挑戰的部分,因為:
- 第一,答案的準確度必須很高,單一分析演算法很難達到要求。DeepQA團隊通過漫長的實驗和摸索最終選擇了上百種演算法從不同的維度分析備選答案,如型別、時間、空間、流行度、來源可靠度、語義相關度等。每種分析都產生一些特徵和評分,如何融合不同維度的分析結果並給出評分是一個巨大的挑戰。
- 第二,計算答案的時間很短。人類選手幾秒就能思考出答案並做出搶答動作。而Watson要執行多步計算:把問題分解成N個假設、每個假設又會去查詢N多可能的證據、對N*N的查詢結果進行合併、最後分析出答案。DeepQA團隊承認最初Watson單機計算一個回答需要2個小時。
為了應對挑戰,DeepQA團隊設計了非結構化資訊應用程式框架(Unstructured Information Management applications 縮寫 UIMA)。UIMA 對於非結構化文字分析定義了一套記錄分析結果的通用分析資料結構Common Analysis Structure(CAS),使不同的演算法可以共享對文字的分析結果。 另外,為了縮短Watson思考的時間,DeepQA團隊設計了UIMA的非同步擴充套件框架(UIMA-AS)用於將分析過程橫向擴充套件到多臺電腦非同步並行處理。UIMA-AS使用JMS(Java Messaging Services)和ActiveMQ處理非同步訊息傳遞,使答案生成引擎可以方便地部署到多臺伺服器上並行處理並彙總分析結果。Watson在參加比賽時,基於UIMA-AS把90臺IBMPower750伺服器連線在一起,把思考時間縮短到3-5秒。可以說Watson主要創新並不在於建立某種新的演算法,而是通過UIMA能夠同時快速執行數百種成熟的語言分析演算法,目前UIMA已經開源給Apache軟體基金會,併成為它的頂級專案。
- 答案決策模組。將對備選答案生成的成千上萬的成績儲存在CAS資料結構中,彙總得到最終成績和自信度。DeepQA團隊使用Jeopardy以往比賽的題庫和模擬題庫訓練出一系列的中間模型,統計出不同成績和自信度的答案在題庫中的正確率。 Watson使用中間模型統計出的正確率,篩選出最有可能的備選答案。
- 遊戲策略模組。依據Jeopardy遊戲的規則,結合場上各個選手的比分,問題的難易度來為Watson制定最優的搶答策略。DeepQA團隊通過歷史比賽和模擬比賽的資料,針對不同的問題和場景,訓練出一系列的中間模型,統計出在某種情況下采取何種策略最有利。
- 學習&訓練模組。DeepQA的工程師將近20T的各類文件,來源包括百科全書,詞典,敘詞表,新聞文章和文學作品等,儲存在Hadoop的HDFS中。利用Hadoop的MapReduce引擎並行分析這些非結構化、半結構化和結構化的文件,分析結果以UIMA的資料結構儲存在資料庫中作為答案庫和證據庫供Watson比賽時查詢和檢索。
Watson平臺化的技術挑戰在哪兒?
藉助Watson在智慧問答領域的成功,IBM努力把它作為一個人工智慧品牌推向商用。例如安裝在汽上,回答駕駛員有關維修的問題,以及如何提供路況資訊和發出安全警示。當汽車故障出現時,Watson可以告訴駕駛員什麼地方出了問題, 是否需要預約去4S點修理。
然而訓練Watson贏得比賽是一回事,選擇怎樣的技術架構把Watson打造成能支援同時服務數以萬計使用者的AI平臺,就是另一個問題。 以前述的汽車助手為例, 要構建一個企業級的AI互動問答平臺, 就不得不考慮如下實際問題:
- 多租戶帶來的資源隔離。 對於企業使用者而言,為了資料的安全性和平臺的穩定性均要求對其資料,資源進行隔離不和其它使用者混用。
- 企業的需求不一,並且使用的服務不同,如何滿足其定製化。
- 由於是新應用,企業客戶更希望AI平臺的計算能力能隨著業務量的增長動態提升,讓花的每一分錢都用到實處。
- 海量的資料儲存需求。 大量人機對話產生的語音資料, 需要有廉價安全的儲存方式來儲存。
什麼樣的技術架構能解決這些問題?
筆者認為用基於PaaS的容器服務(Container As a Service 縮寫 CaaS) + SaaS的架構能很好地解決上述問題。容器服務(CaaS)是一種基於容器的虛擬化形式,其中容器引擎,編排和底層計算資源作為雲服務提供給使用者。容器服務平臺技術近兩年已經發展得比較成熟,目前比較流行的實現方式是以Docker為容器化技術,Kubernetes為容器化的應用提供資源排程、部署執行、服務發現、擴容縮容等整一套功能。利用容器服務平臺封裝、隔離和部署靈活的特性,能很好的解決上述多租戶帶來的問題。結合雲端計算SaaS層的租戶管理, API管理,計費管理等應用層能力,能很好的解決企業二次開發定製化的需求。PaaS平臺對於DevOps的無縫支援以及基礎資源(雲端儲存、訊息佇列、RDS以及映象),也使問題3和4的解決變得非常容易。完整的企業級AI平臺技術架構如下(圖3):
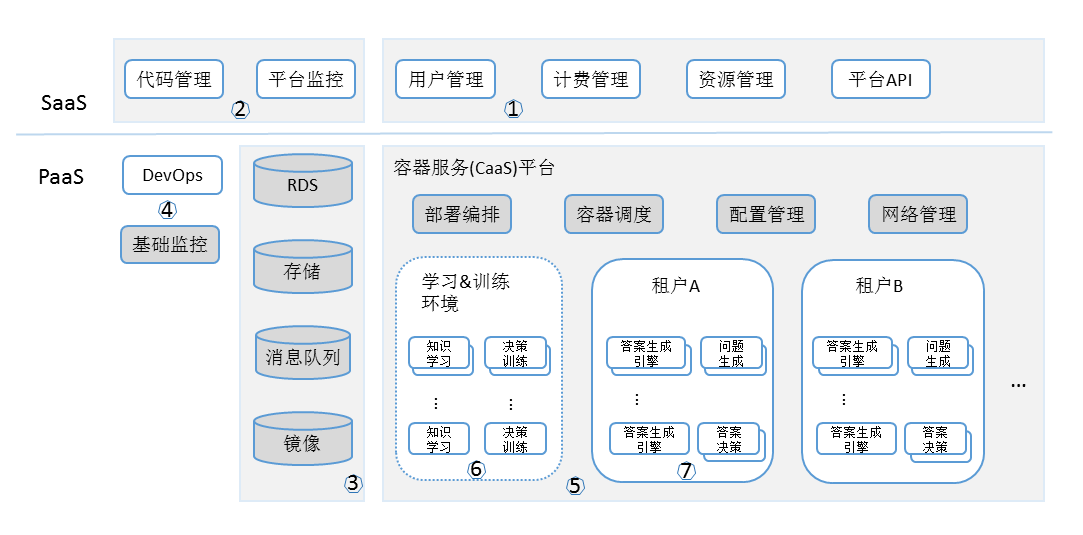
- SaaS應用平臺作為和使用者的互動介面,負責將AI平臺的能力和使用者對接。根據AI平臺的業務特點,自研發使用者管理,計費管理,以及對使用者資源的管理模組,研發基於OAUTH, RESTful的 OpenAPI平臺。
- SaaS平臺還要對AI平臺的研發和日常監控進行支撐。 搭建AI平臺的運營監控和程式碼管理系統。
- PaaS提供平臺基礎資源。提供RDS,既存放AI平臺共享的知識庫和訓練模型,也存放租戶自定義的資料內容;提供雲端儲存,放置各類結構化和非結構化的文件資源,人機對話產生的巨大儲存需求也有很好的解決方案;提供訊息佇列,用於支撐類似於UIMA-AS橫向擴容時平行計算的訊息傳遞;提供映象管理(包含虛機的基礎映象管理和容器服務的容器映象管理),用於儲存各AI子系統模組最新的Docker映象。
- PaaS自身支援DevOps。負責平臺的程式碼和軟體更新, 通過DevOps推送到PaaS平臺的映象倉庫中,交由容器服務平臺自動進行升級和回滾。
- 基於PaaS的容器服務平臺,在部署編排模組的管理下,從PaaS的映象中獲取相關容器映象,為每個租戶部署一套完整的AI生產環境。容器排程模組結合PaaS平臺的基礎監控,根據租戶的資源執行情況,對執行例項進行動態調整。配置管理模組統一管理各租戶內部子系統的配置。網路管理用於協調租戶內部和外部雲平臺之間的網路路由和流量分配。
- 學習和訓練環境也部署在容器服務平臺。 因為AI的訓練和學習時間不固定,沒有必要佔用大量資源。在需要時申請,完成計算後釋放,能有效得節省計算資源的使用。
- 對於每個租戶,通過容器服務平臺建立完整的Watson系統。容器化的問題生成,答案生成引擎,和答案決策模組可在容器服務平臺裡動態伸縮,達到資源的合理利用。
總結
隨著以Docker和Kubernetes為代表的容器服務技術日益走向成熟,企業利用PaaS容器化平臺+SaaS的架構搭建自己的業務平臺已經進入了實踐階段, 國內已經湧現出了一些用私有云的容器服務平臺搭建自身業務平臺的成功案例(參考4)。目前公有云服務商Azure、AWS、Google和阿里雲等都紛紛基於自己的PaaS平臺推出了類似CaaS的產品。 這種架構設計利用雲平臺動態伸縮的優勢降低AI平臺的初始資源投入,同時保證平臺後續沒有資源方面的瓶頸,是一種可行的AI平臺架構設計解決方案。另一方面,我們也應看到該方案的侷限性,對於需要實時使用大量硬體資源(如GPU)的AI應用場景,容器服務化並不能解決全部問題。
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/
