1.MySQL-體系結構
一.MySQL體系架構
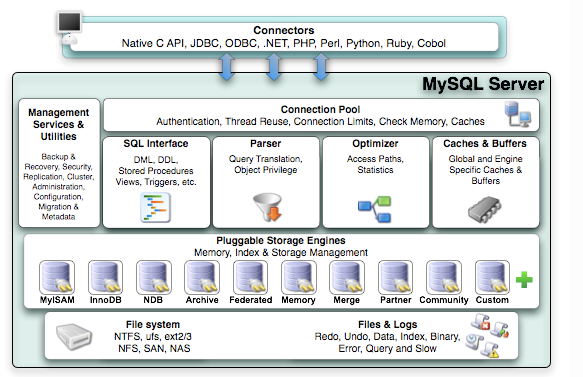
1、Mysql是由SQL介面,解析器,優化器,快取,儲存引擎組成的(SQL Interface、Parser、Optimizer、Caches&Buffers、Pluggable Storage Engines)
第一層:客戶端
並不是MySQL獨有的技術,它們都是服務於C/S程式或者是這些程式所需要的 :連線處理,身份驗證,安全性等等
(1) Connectors指的是不同語言中與SQL的互動 (並不是MySQL獨有的技術,它們都是服務於C/S程式或者是這些程式所需要的 :連線處理,身份驗證,安全性等等)
第二層:SQL Layer。MySQL的核心部分
這是MySQL的核心部分。通常叫做 SQL Layer。在 MySQL據庫系統處理底層資料之前的所有工作都是在這一層完成的,包括許可權判斷, sql解析,行計劃優化, query cache 的處理以及所有內建的函式(如日期,時間,數學運算,加密)等等。各個儲存引擎提供的功能都集中在這一層,如儲存過程,觸發器,視 圖等。
(2)Management Serveices & Utilities: 系統管理和控制工具,例如備份恢復、Mysql複製、叢集等
(3)Connection Pool: 連線池:管理緩衝使用者連線、使用者名稱、密碼、許可權校驗、執行緒處理等需要快取的需求
(4)SQL Interface: SQL介面:接受使用者的SQL命令,並且返回使用者需要查詢的結果。比如select from就是呼叫SQL Interface
(5)Parser: 解析器,SQL命令傳遞到解析器的時候會被解析器驗證和解析。解析器是由Lex和YACC實現的,是一個很長的指令碼, 主要功能:
a . 將SQL語句分解成資料結構,並將這個結構傳遞到後續步驟,以後SQL語句的傳遞和處理就是基於這個結構的
b. 如果在分解構成中遇到錯誤,那麼就說明這個sql語句是不合理的
(6)Optimizer: 查詢優化器,SQL語句在查詢之前會使用查詢優化器對查詢進行優化。他使用的是“選取-投影-聯接”策略進行查詢。
用一個例子就可以理解: select uid,name from user where gender = 1;
這個select 查詢先根據where 語句進行選取,而不是先將表全部查詢出來以後再進行gender過濾
這個select查詢先根據uid和name進行屬性投影,而不是將屬性全部取出以後再進行過濾
將這兩個查詢條件聯接起來生成最終查詢結果
(7) Cache和Buffer(快取記憶體區): 查詢快取,如果查詢快取有命中的查詢結果,查詢語句就可以直接去查詢快取中取資料。
通過LRU演算法將資料的冷端溢位,未來得及時重新整理到磁碟的資料頁,叫髒頁。
這個快取機制是由一系列小快取組成的。比如表快取,記錄快取,key快取,許可權快取等
第三層:儲存引擎層
通常叫做StorEngine Layer ,也就是底層資料存取操作實現部分,由多種儲存引擎共同組成。它們負責儲存和獲取所有儲存在MySQL中的資料。就像Linux眾多的檔案系統 一樣。每個儲存引擎都有自己的優點和缺陷。伺服器是通過儲存引擎API來與它們互動的。這個介面隱藏 了各個儲存引擎不同的地方。對於查詢層儘可能的透明。這個API包含了很多底層的操作。如開始一個事 物,或者取出有特定主鍵的行。儲存引擎不能解析SQL,互相之間也不能通訊。僅僅是簡單的響應伺服器 的請求
(8)Engine :儲存引擎。儲存引擎是MySql中具體的與檔案打交道的子系統。也是Mysql最具有特色的一個地方。
Mysql的儲存引擎是外掛式的。它根據MySql AB公司提供的檔案訪問層的一個抽象介面來定製一種檔案訪問機制(這種訪問機制就叫儲存引擎)
現在有很多種儲存引擎,各個儲存引擎的優勢各不一樣,最常用的MyISAM,InnoDB,BDB
預設下MySql是使用MyISAM引擎,它查詢速度快,有較好的索引優化和資料壓縮技術。但是它不支援事務。
InnoDB支援事務,並且提供行級的鎖定,應用也相當廣泛。
Mysql也支援自己定製儲存引擎,甚至一個庫中不同的表使用不同的儲存引擎,這些都是允許的
一條SQL的執行過程
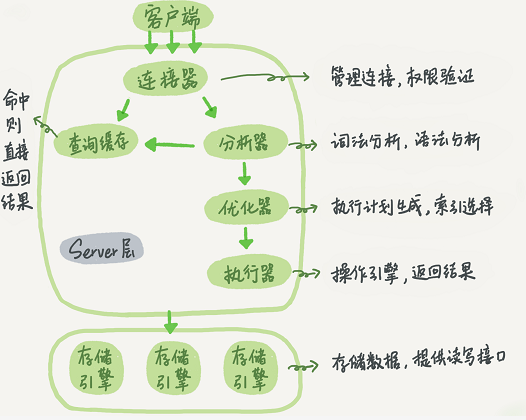
MySQL是單程序,多執行緒
連線管理和安全
在伺服器內部,每個client連線都有自己的執行緒。這個連線的查詢都在一個單獨的執行緒中執行。這些執行緒輪流執行在某一個CPU核心(多核CPU)或者CPU中。伺服器快取了執行緒,因此不需要為每個client連線單獨建立和銷燬執行緒 。
當clients(也就是應用程式)連線到了MySQL伺服器。伺服器需要對它進行認證(Authenticate)。認證是基於使用者名稱,主機,以及密碼。對於使用了SSL(安全套接字層)的連線,還使用了X.509證書。clients一連線上,伺服器就驗證它的許可權 (如是否允許客戶端可以查詢world資料庫下的Country表的資料)。
優化和執行
MySQL會解析查詢,並建立了一個內部資料結構(解析樹)。然後對其進行各種優化。這些優化包括了,查詢語句的重寫,讀表的順序,索引的選擇等等。使用者可以通過查詢語句的關鍵詞傳遞給優化器以便提示使用哪種優化方式,這樣即影響了優化器的優化方式。另外,使用者也可以請求伺服器給出優化過程的各種說明,以獲知伺服器的優化策略,為使用者提供了引數基準,以便使用者可以重寫查詢,架構和修改相關伺服器配置,便於mysql更高效的執行。
優化器並是不關心表使用了哪種儲存引擎,但是儲存引擎對伺服器優化查詢的方式是有影響的。優化器需要知道儲存引擎的一些特性:具體操作的效能和開銷方面的資訊,以及表內資料的統計資訊。例如,儲存引擎支援哪些索引型別,這對於查詢是非常有用的。
在解析查詢之前,要查詢快取,這個快取只能儲存查詢資訊以及結果資料。如果請求一個查詢在快取 中存在,就不需要解析,優化和執行查詢了。直接返回快取中所存放的這個查詢的結果。
二.MySQL記憶體結構
Mysql 記憶體分配規則是:用多少給多少,最高到配置的值,不是立即分配。
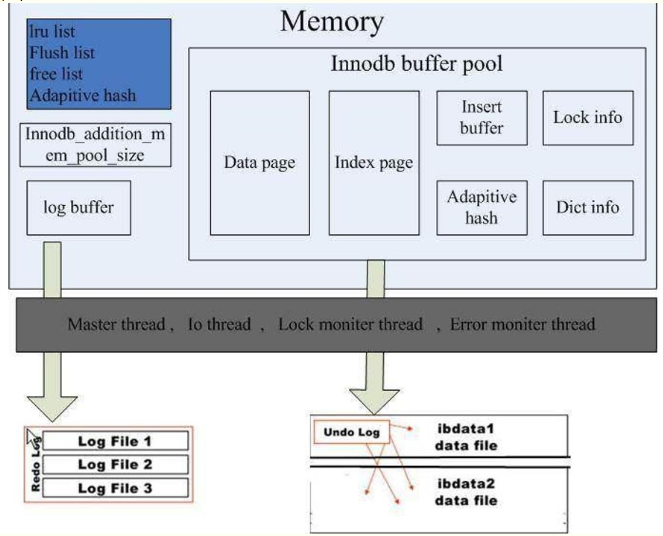
實際上MySQL記憶體的組成和Oracle類似,也可以分為SGA(系統全域性區)和PGA(程式快取區)。
mysql>show variables like "%buffer%";
一、SGA
1.innodb_buffer_pool
用來快取Innodb表的資料、索引、插入緩衝、自適應雜湊索引,鎖資訊,資料字典等資訊。
2.innodb_log_buffer
事務在記憶體中的緩衝,即red log buffer的大小
3.query cache
高速查詢快取,在生產環境中建議關閉。
4.key_buffer_size
用於MyISAM儲存引擎,快取MyISAM儲存。
引擎表的索引檔案(區別於innodb_buffer_poll資料和索引快取)
5.innodb_additional_mem_pool_size
用來快取資料字典資訊和其它內部資料結構的記憶體池的大小。MySQL5.7.4中該引數取消。
二、PGA
1.sort_buffer_size(排序緩衝大小,提高排序效率)
主要用於SQL語句在記憶體中的臨時排序
2.join_buffer_size
表連線使用,用於BKA,MySQL5.6之後開始支援。
3.read_buffer_size(順序讀緩衝大小,提高順序都效率)
表順序掃描的快取,只能應用於MyISAM表儲存引擎。
4.read_rnd_buffer_size(隨機緩衝大小,提高隨機都效率)
MySQL隨機讀緩衝區大小,用於做mrr,mrr是MySQL5.6之後才有的特性。
5.tmp_table_size
SQL語句在排序或分組時沒有用到索引,就會使用臨時表空間。
6.max_heap_table_size
管理heap,memory儲存引擎表。
(1)innodb_buffer_pool_size:
(1.1) innodb高速緩衝data和索引,簡稱IBP,這個是Innodb引擎中影響效能最大的引數。建議將IBP設定的大一些,單例項下,建議設定為可用RAM的50%~80%。
(1.2)innodb不依賴OS,而是自己快取了所有資料,包括索引資料、行資料等等,這個和myisam有差別。
(1.3)IBP有一塊buffer用於插入緩衝,在插入時,先寫入記憶體之後再合併後順序寫入磁碟;在合併到磁碟的時候會引發較大的IO操作,對實際操作造成影響。(看上去的表現是抖動,TPS變低)
(1.4)show global status like ‘innodb_buffer_pool_%’ 檢視IBP狀態,單位是page(16kb),其中,Innodb_buffer_pool_wait_free 如果較大,需要加大IBP設定
(1.5)InnoDB會定時(約每10秒)將髒頁重新整理到磁碟,預設每次重新整理10頁;要是髒頁超過了指定數量(innodb_max_dirty_pages_pct),InnoDB則會每秒刷100頁髒頁
(1.6)innodb_buffer_pool_instances可以設定pool的數量
(1.7)show engine innodb status\G 可以檢視innodb引擎狀態
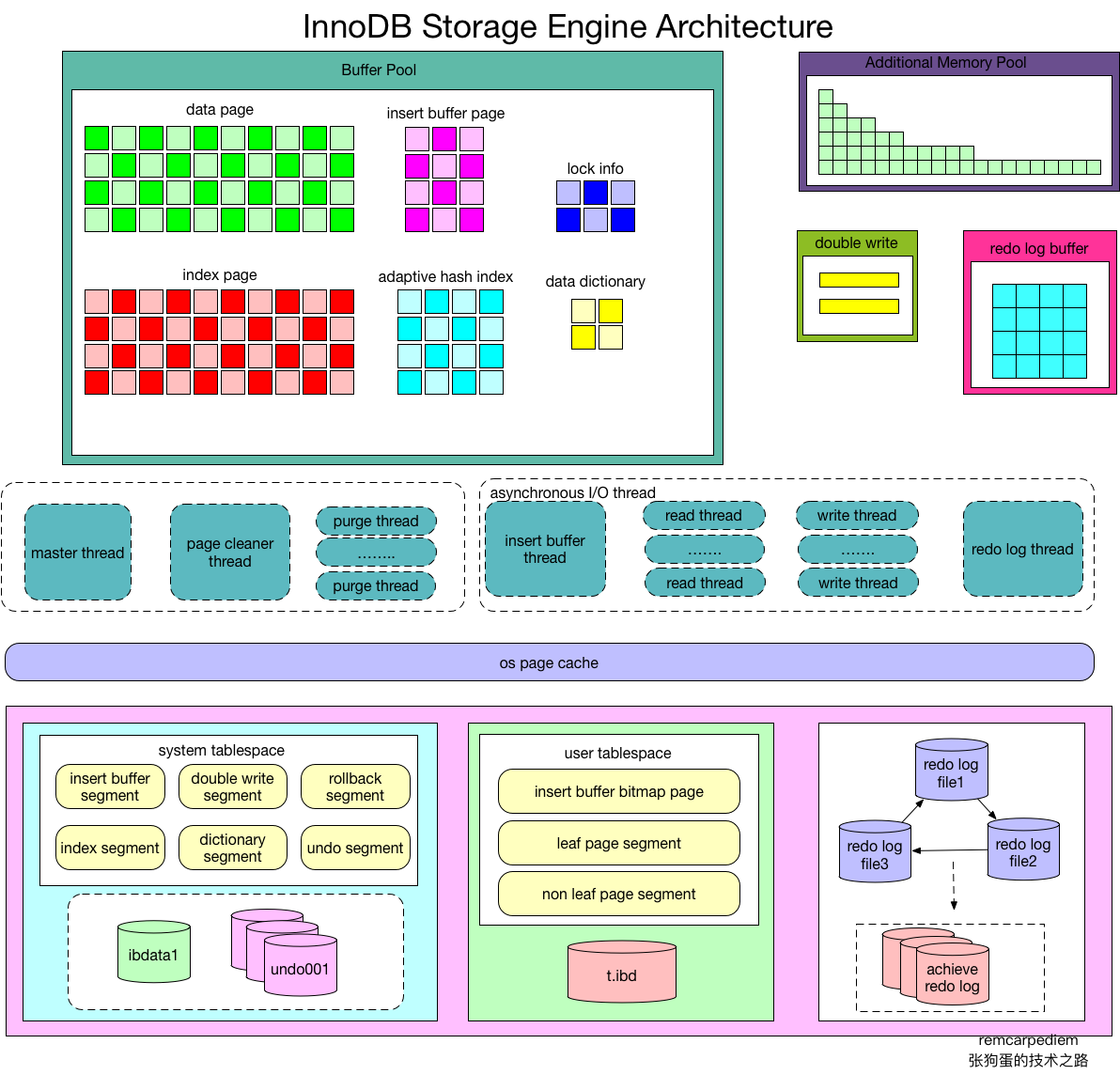
四.Innodb體系結構