
Elasticsearch2.3.4使用手冊
一、工具安裝
- 訪問官網https://www.elastic.co/downloads/elasticsearch和http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc下載版本匹配的es和es-jdbc。如果資料庫使用的非MySQL,還需要將相應版本的資料庫驅動拷貝到elasticsearch-jdbc的lib下;
- 訪問https://github.com/mobz/elasticsearch-head下載es-head外掛,即es的控制檯。解壓後放在elasticsearch\plugins\下新建的head資料夾中,啟動es後訪問http://localhost:9200/_plugin/head/即可檢視控制檯介面,在控制檯可以檢視叢集、節點,建立、檢視索引,進行資料查詢等等;
- 訪問https://github.com/medcl/elasticsearch-analysis-ik下載ik分詞外掛(1.9.4的ik和2.3.4的es匹配,其他版本可參考https://blog.csdn.net/songjinbin/article/details/50781522檢視),安裝方式同上,新建ik資料夾即可。
二.使用步驟
A. 編寫指令碼,同步資料並建立索引
- Windows下進入elasticsearch-jdbc/bin新建.bat檔案(Linux下為.sh檔案),命名無要求。配置elasticsearch.cluster-叢集名、host-ip地址、port-埠號;
- 配置statefile-指令碼輸出檔案,schedule-定時重新整理時間;
- 配置資料庫連線屬性、sql語句。sql必須為動態,根據metrics.lastexecutionstart-指令碼執行時間和updatetime-資料庫時間欄位來定時刷入新增和修改的資料(增量同步):
"statement" : "select * from table where updatetime > ?",^
"parameter" : ["$metrics.lastexecutionstart"]^
*這是增量同步的一種方式,當需要同步的資料較多需要寫多條sql時,建議使用儲存過程做增量同步,可參考A-7的同步指令碼和儲存過程示例;
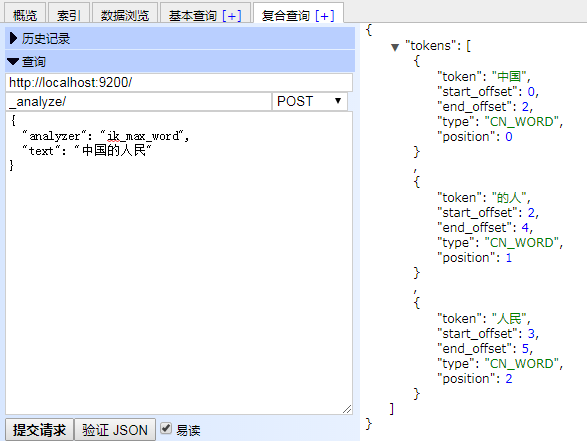
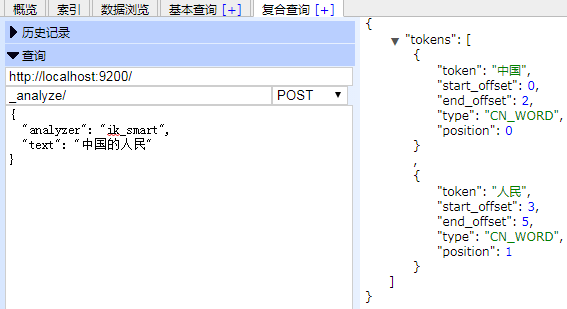
4. ik分詞器的使用。ik分詞器分為兩種分詞方法,一種是最大切分,一種是全切分,對應的名字為ik_smart,ik_max_word,分詞效果可參考圖1圖2;
圖一:
圖二:
5. 其它一些配置。
"term_vector":可獲取document中的某個field內的各個term的統計資訊,從而對詞條進行過濾篩選;
"copy_to":可以自由把一個索引下的一個或以上的欄位值複製到另外的一個欄位中,在需要查詢多個欄位時設定一個欄位即可;
6. 生成和配置索引、對映、欄位可參考如下的生成索引示例。索引相關配置可參考http://www.cnblogs.com/chenmc/p/9516100.html,需要注意的是sql語句中欄位名和索引下欄位名的一致性;
{ "settings": { "index": { "analysis": { "analyzer": { "ik": { "tokenizer": "ik" } } } } }, "mappings": { "userInfo": { "properties": { "userName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "teamName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "updateTime": { "type": "string", "index": "not_analyzed", "include_in_all": false } }, "_mixField": { "type": "string", "analyzer": "ik_smart", "term_vector": "with_positions_offsets" } }, "menu": { "properties": { "menuName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "updateTime": { "type": "string", "index": "not_analyzed", "include_in_all": false }, "_mixField": { "type": "string", "analyzer": "ik_smart", "term_vector": "with_positions_offsets" } } } } }
7. 同步指令碼及其使用的oracle儲存過程示例。在實際的應用中,在指令碼中通過寫多條sql同步多表資料時很難做到增量同步,一般使用如下方法。
@echo off title oracle_to_es set DIR=%~dp0 set LIB=%DIR%..\..\lib\* set BIN=%DIR%..\..\bin echo {^ "type" : "jdbc",^ "jdbc" : {^ "statefile" : "ar01.json",^ "schedule" : "0 0-59 0-23 ? * *",^ "url" : "jdbc:oracle:thin:@192.168.1.117:1521/orcl",^ "user" : "projectmanage",^ "password" : "123456",^ "sql" : [{^ "callable" : true,^ "statement" : "{call es_syncinfo(?,?)}",^ "parameter" : ["001"],^ "register" : {"myOracleProcedureResult" : {"pos" : 2, "type" :"cursor" }}^ }],^ "elasticsearch.cluster":"elasticsearch",^ "elasticsearch" : {^ "host" : "localhost",^ "port" : 9300^ },^ "index" : "myindex",^ "type" : "userInfo"^ }^ }^ | "%JAVA_HOME%\bin\java" -cp "%LIB%" -Dlog4j.configurationFile="%BIN%\log4j2.xml" "org.xbib.tools.Runner" "org.xbib.tools.JDBCImporter"
-- Create table create table T_RT_SYNCINFO ( syncid VARCHAR2(10) not null, indexname VARCHAR2(256), typename VARCHAR2(256), syncsql VARCHAR2(4000), syncsql2 VARCHAR2(4000), lasttimesql VARCHAR2(4000), synctime DATE not null, syncdesc VARCHAR2(1024), isvalid NUMBER(1) ) -- Add comments to the columns comment on column T_RT_SYNCINFO.syncid is '同步id'; comment on column T_RT_SYNCINFO.indexname is '索引名'; comment on column T_RT_SYNCINFO.typename is '型別名'; comment on column T_RT_SYNCINFO.syncsql is '同步sql'; comment on column T_RT_SYNCINFO.syncsql2 is '同步sql2'; comment on column T_RT_SYNCINFO.lasttimesql is '最後一條更新時間sql'; comment on column T_RT_SYNCINFO.synctime is '同步時間'; comment on column T_RT_SYNCINFO.syncdesc is '描述'; comment on column T_RT_SYNCINFO.isvalid is '是否有效(0:有效;1:無效)'; CREATE OR REPLACE PROCEDURE es_syncinfo ( i_syncid in varchar2, --同步id o_result out sys_refcursor --返回碼(0成功, 1失敗) ) IS v_syncsql VARCHAR2(8000); v_synctime T_RT_SYNCINFO.synctime%type; v_lasttimesql T_RT_SYNCINFO.lasttimesql%type; v_lasttime date; v_ErrCode VARCHAR2(100); v_ErrMsg VARCHAR2(200); BEGIN BEGIN --查詢同步時間和同步sql SELECT t.SYNCTIME, t.SYNCSQL||t.SYNCSQL2, t.LASTTIMESQL into v_synctime, v_syncsql, v_lasttimesql FROM T_RT_SYNCINFO t WHERE t.SYNCID = i_syncid AND t.isvalid = 0; EXCEPTION WHEN NO_DATA_FOUND THEN OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; return; END; IF v_syncsql IS NOT NULL AND v_lasttimesql IS NOT NULL THEN BEGIN v_lasttimesql := REPLACE(v_lasttimesql, '?' , 'to_date(''' || to_char(v_synctime, 'yyyy/mm/dd hh24:mi:ss') || ''', ''yyyy/mm/dd hh24:mi:ss'')'); EXECUTE IMMEDIATE v_lasttimesql INTO v_lasttime; EXCEPTION WHEN NO_DATA_FOUND THEN OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; return; END; IF v_lasttimesql IS NOT NULL THEN --增量查詢所有待同步資料 v_syncsql := REPLACE(v_syncsql, '?' , 'to_date(''' || to_char(v_synctime, 'yyyy/mm/dd hh24:mi:ss') || ''', ''yyyy/mm/dd hh24:mi:ss'')'); OPEN o_result FOR v_syncsql; --更新同步時間 UPDATE T_RT_SYNCINFO t SET t.SYNCTIME = v_lasttime WHERE t.SYNCID = i_syncid; COMMIT; END IF; END IF; EXCEPTION WHEN OTHERS THEN ROLLBACK; OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; v_ErrCode := SQLCODE; v_ErrMsg := SUBSTRB(SQLERRM, 1, 200); DBMS_OUTPUT.PUT_LINE(v_ErrCode||':'||v_ErrMsg); RAISE; END es_syncinfo;
B. 執行搜尋引擎
- 進入elasticsearch/bin下,執行cmd,輸入elasticsearch啟動es,如果配置了head外掛和ik,都會隨之啟動,可以在啟動資訊中檢視;
- 在es啟動成功後(資料庫服務也要保持開啟狀態),進入elasticsearch-jdbc/bin下,執行上一步中配置好的.bat指令碼;
- 如果安裝了head外掛,等指令碼執行完畢後,可以在控制檯頁面看到生成的索引、索引型別以及同步的資料。
C. Java操作es-api查詢
1. 新增對應版本的es依賴或者jar包,如果版本不一致,會導致無法連線到es;
2. 連線es的java程式碼如下所示,需要注意的是在es2.X之後的版本,在連線上有很大的區別,在此不再敘述。在下面的程式碼中把CLUSTER_NAME,IP,PORT換成自己的即可;
Settings settings = Settings.settingsBuilder() .put("cluster.name", CLUSTER_NAME) .build(); Client client = new TransportClient.Builder().settings(settings).build() .addTransportAddress(new InetSocketTransportAddress (new InetSocketAddress(IP, PORT)));
3. 在執行查詢時,主要是使用QueryBuilders核心查詢物件,通過該物件可以設定使用es的多種查詢方式,詳情可參https://blog.csdn.net/alan_liuyue/article/details/78354630;
4. 查詢後使用client.close();關閉連線資源;
5. 查詢示例。
package com.example.demo.controller; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.Client; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.InetSocketTransportAddress; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import java.net.InetSocketAddress; import java.util.Iterator; public class ElasticSearch { //連線使用的常量 public static final String CLUSTER_NAME = "elasticsearch"; private static final String IP = "localhost"; private static final int PORT = 9300; //執行查詢 public static void main(String[] args) throws Exception { //1.設定要連線的es叢集 //2.設定client.transport.sniff為true來使客戶端去嗅探整個叢集的狀態,把叢集中其它機器的ip地址自動加到客戶端中 //(上述設定需要開啟es的遠端訪問) //(當ES伺服器監聽(publish_address)使用內網伺服器IP,而訪問(bound_addresses)使用外網IP時,不要設定) Settings settings = Settings.settingsBuilder() .put("cluster.name", CLUSTER_NAME) .put("client.transport.sniff", true) .build(); //使用上述配置連線es端 Client client = new TransportClient.Builder().settings(settings).build() .addTransportAddress(new InetSocketTransportAddress (new InetSocketAddress(IP, PORT))); //執行查詢,其中QueryBuilders(QueryBuilder)是核心查詢物件,可設定查詢方式和內容 //matchQuery用於文字型別欄位的搜尋 //boolQuery用於基於條件的組合查詢 /* QueryBuilder queryBuilder01 = QueryBuilders.matchQuery("name", "小小"); QueryBuilder queryBuilder02 = QueryBuilders.matchQuery("name", "大"); QueryBuilder queryBuilder03 = QueryBuilders.boolQuery().must(queryBuilder01).mustNot(queryBuilder02);*/ QueryBuilder queryBuilder04 = QueryBuilders.multiMatchQuery("中華的人民", "name", "teamName", "menuName"); SearchResponse searchResponse = client.prepareSearch("myindex").setTypes("userInfo", "menu") .setQuery(queryBuilder04) .get(); //獲得查詢出的值 SearchHits hits = searchResponse.getHits(); if (hits.totalHits() > 0) { Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()) { SearchHit next = iterator.next(); System.out.println("查詢到:" + next.getSourceAsString() + ",該項匹配度為" + next.getScore()); } } else { System.out.println("沒有可匹配的結果。"); } //關閉連線 client.close(); } }
D. 注意事項
1) 預設情況下,elasticsearch只允許本機訪問(localhost),如果需要遠端訪問,可以到config/elasticsearch.yml檔案去掉network.host的註釋,將它的值改成0.0.0.0,然後重新啟動elasticsearch。設定固定ip訪問同理;
2) Elasticsearch本身不支援通過儲存過程進行資料同步,需要對其進行修改。使用儲存過程時,需要註冊返回物件來接受查詢的結果集,即指令碼中的"register" : {"myOracleProcedureResult" : {"pos" : 2, "type" :"cursor" }}^;
3) Elasticsearch無法同步被物理刪除的資料,建議在需要同步的資料表中加入刪除欄位,並在同步sql中加入判斷條件進行篩選以保證資料同步性;
4) *索引名稱必須小寫;
5) elasticsearch自帶_all欄位,它是所有欄位的拼接,如果全欄位查詢中完全不需要分詞,需要對它進行設定"index" : "not_analyzed",對每個欄位進行設定是無效的。同理,_all欄位預設使用es自帶分詞器,如需使用其他分詞器也要進行單獨配置;
6) 拼音分詞器:https://github.com/medcl/elasticsearch-analysis-pinyin可以對漢語拼音進行分詞,如有需要可以使用。
這次就到這裡了,接下來是Elasticsearch在伺服器上的部署介紹,敬請期待!