
java正則表示式分組( )分組
以下內容均為個人理解,方便後續複習用部落格整理起來,如果有誤,還望指正。。。。(以下均為java在eclipse中的正則表示式)
( )分組
在java正則表示式中,( )是分組的意思,依舊是所謂的捕獲組。每一個( )代表著一個group,該組是通過從左至右計算其括號來編號。
一個經典的例子:
在表示式((A)(B(C))),有四個這樣的組:
- ((A)(B(C)))
- (A) 可以看出,這個分組就是按照括號從左至右計算得來的
- (B(C))
- (C)
可以通過呼叫 matcher 物件的 groupCount 方法來查看錶達式有多少個分組。groupCount 方法返回一個 int 值,表示matcher物件當前有多個捕獲組。
還有一個特殊的組(group(0)),它總是代表整個表示式。該組不包括在 groupCount 的返回值中。
到此,我對()分組的探究並沒有停止,在看了不少部落格之後,我發現分組還能夠通過引用來簡化表示式,而引用的方式是(\1或者$1)。
總結下來分組 的作用(借鑑別人的部落格):
1.將某些規律看成是一組,然後進行組級別的重複,可以得到意想不到的效果。
2.分組之後,可以通過後向引用簡化表示式(\1 或者$1)。
分組舉列
先來看第一個作用,對於IP地址的匹配,簡單的可以寫為如下形式(eclipse中java正則):
String pattern = "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})";從這個 我們可以看出,這裡有五個group,group(0)、group(1)、group(2)、group(3)、group(4),並且這幾個分組的正則表示式都是一樣的。我們可以對上述正則表示式進行簡化。結果如下:
String pattern = "(\\d{1,3})(\\.(\\d{1,3})){3}";
這個表示式的意思就是把IP地址xx.xx.xx.xx後面的帶顏色的.xx重複三次。
再來看第二個作用,就拿匹配<title>hello</title>標籤來說,簡單的正則可以這樣寫:
<title>.*</title>
可以看出,上邊表示式中有兩個title,完全一樣,其實可以通過分組簡寫。表示式如下:
<(title)>.*</\1> eclipse中是<(title)>.*</\\1>
對於分組而言,整個表示式永遠算作第0組,在本例中,第0組是<(title)>.*</\\1>,然後從左到右,依次為分組編號,因此,(title)是第1組。看下面的程式碼
public class Title {
public static void main(String[] args) {
String title="<title>hello</title>";
String pattern = "<(title)>.*</\\1>";
Pattern p=Pattern.compile(pattern);
//Pattern p=Pattern.compile(pattern1);
Matcher m=p.matcher(title);
if(m.find()==true) {
boolean b=m.matches();
System.out.println(b);
System.out.println(m.group(0));
System.out.println(m.group(1));
System.out.println(m.group(2));
}
}
}會在控制檯列印如下:

錯誤提示是沒有組2,因為在這個程式碼中就只有(title)這一個組。
注意:
用\1這種語法,可以引用某組的文字內容,但不能引用正則表示式。
例如剛剛的IP地址正則表示式為(\\d{1,3})(\\.(\\d{1,3})){3},裡邊的\\.(\\d{1,3})重複了三次,如果利用後向引用簡化,表示式如下:
String pattern2 = "(\\d{1,3})(\\.\\1){3}";經過實際測試,會發現這樣寫是錯誤的,為什麼呢?
後向引用,引用的僅僅是文字內容,而不是正則表示式!
也就是說,組中的內容一旦匹配成功,後向引用,引用的就是匹配成功後的內容,引用的是結果,而不是表示式。
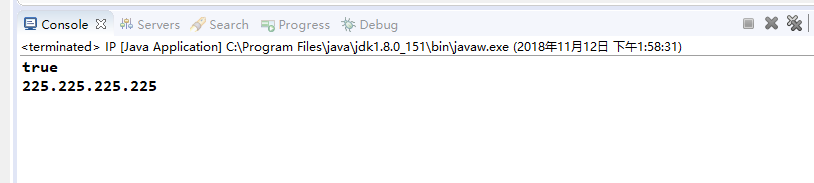
因此,(\\d{1,3})(\\.\\1){3}這個表示式實際上匹配的是四個數都相同的IP地址,比如:225.225.225.225。程式碼:
public class IP {
public static void main(String[] args) {
String ip="225.225.225.225";
// String pattern = "(\\d{1,3})(\\.(\\d{1,3})){3}";
// String pattern1 = "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})";
String pattern2 = "(\\d{1,3})(\\.\\1){3}";
Pattern p=Pattern.compile(pattern2);
Matcher m=p.matcher(ip);
if(m.find()==true) {
boolean b=m.matches();
System.out.println(b);
System.out.println(m.group(0));
}
}
}控制檯列印結果:
正則真的玄妙,一個小小的()分組都夠研究半天了,估計是我太菜了。。。。。
注:在進一步學習後,遇到這個問題:
在使用?<=和?=時,例如:(?<=(href=\")).*(?=(\">))。
按照之前的分析,此時的group(1)是(?<=(href=\")),group(2)應該是(href=\"),其實並不是這樣的,在正則表示式中(?<=pattern)是一個字元。正確的group(1)是(href=\")。
貼一個例子:
public class UseGhd {
public static void main(String[] args) {
//(?<=(href=")).{1,200}(?=(">))
String s="<br/>您好,非常好,很開心認識你\r\n" +
"<br/><a target=_blank href=\"www.baidu.com\">百度一下</a>百度才知道\r\n" +
"<br/><a target=_blank href=\"/view/fafa.htm\">發發</ a>最佳帥哥\r\n" +
"<br/><a target=_blank href=\"/view/lili.htm\">麗麗</ a>最佳美女\r\n" +
"<br/>";
String pattern="(?<=(href=\")).*(?=(\">))";
Pattern p=Pattern.compile(pattern);
//Pattern p=Pattern.compile(pattern1);
Matcher m=p.matcher(s);
while(m.find()) {
//System.out.println(m);
System.out.println(m.group(0));
System.out.println(m.group(1));
System.out.println(m.group(2));
}
String s1="dog";
String pattern1="((.)(.(.)))";
Pattern p1=Pattern.compile(pattern1);
Matcher m1=p1.matcher(s1);
while(m1.find()) {
//System.out.println(m);
System.out.println(m1.group(0));
System.out.println(m1.group(1));
System.out.println(m1.group(2));
System.out.println(m1.group(3));
System.out.println(m1.group(4));
}
}
}結果:

其中道理 慢慢捋一捋就能知道。。。。