
Python爬蟲1-獲取指定網頁原始碼
阿新 • • 發佈:2018-12-07
1、任務簡介
前段時間一直在學習Python基礎知識,故未更新部落格,近段時間學習了一些關於爬蟲的知識,我會分為多篇部落格對所學知識進行更新,今天分享的是獲取指定網頁原始碼的方法,只有將網頁原始碼抓取下來才能從中提取我們需要的資料。
2、任務程式碼
Python獲取指定網頁原始碼的方法較為簡單,我在Java中使用了38行程式碼才獲取了網頁原始碼(大概是學藝不精),而Python中只用了6行就達到了效果。
Python中獲取網頁原始碼最簡單的方法就是使用urllib包,具體程式碼如下:
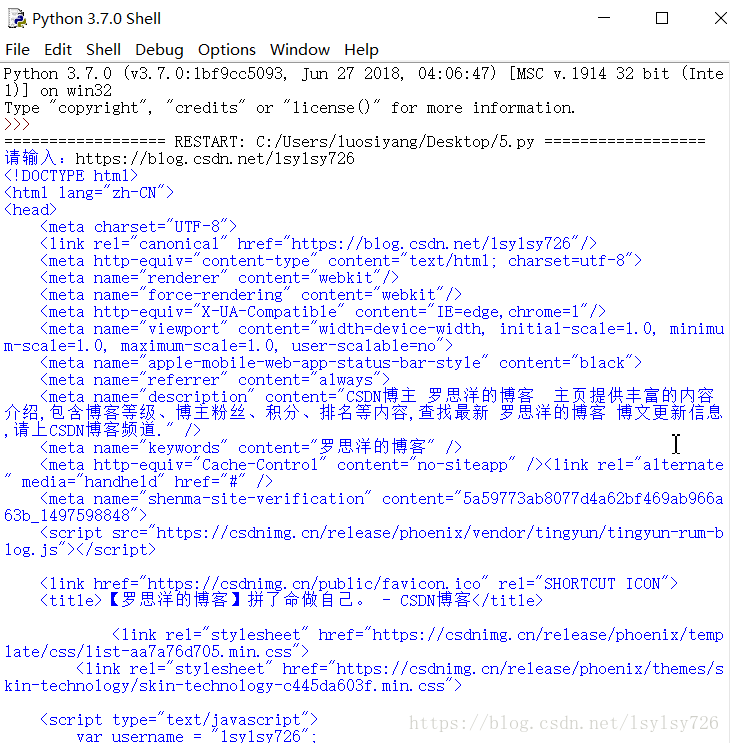
import urllib.request #匯入urllib.request庫 我輸入的網址是我部落格主頁的網址https://blog.csdn.net/lsylsy726
執行結果如下:
3、總結
這篇部落格介紹的方法較為簡單,其實有的網站會“反爬蟲”,這時就需要我們使用User-Agent或者代理,這些東西都會在後面的部落格中進行更新,我預計在後面部落格中更新“讀取CSDN部落格訪問量的小程式”和“有道翻譯小程式”及其他更難一些的知識,由於剛開始學習爬蟲,水平有限,請大家多多包涵。