
互動百科詞條快速抓取[適用於文字處理與挖掘]
阿新 • • 發佈:2018-12-07
- 1.前言
因近期小組的一個專案有文字挖掘的需求,需要用到Word2Vec的文字特徵抽取,為了進行技術預演需要我們提前對模型進行訓練。而只要涉及資料探勘相關的模型,資料集是不必可少的。中文文字挖掘領域,百科詞條涵蓋面廣,而且內容比較豐富,於是便選擇百科的詞條作為資料集 (http://baike.com)。
- 2.詞條抓取方案與程式碼實現
2.1 抓取方案
step1:
收集百科詞條種子(後臺的id列表)
step2:
獲取詳情頁並解析html中的詞條正文
step3:
資料儲存(以文字txt儲存或者存庫)
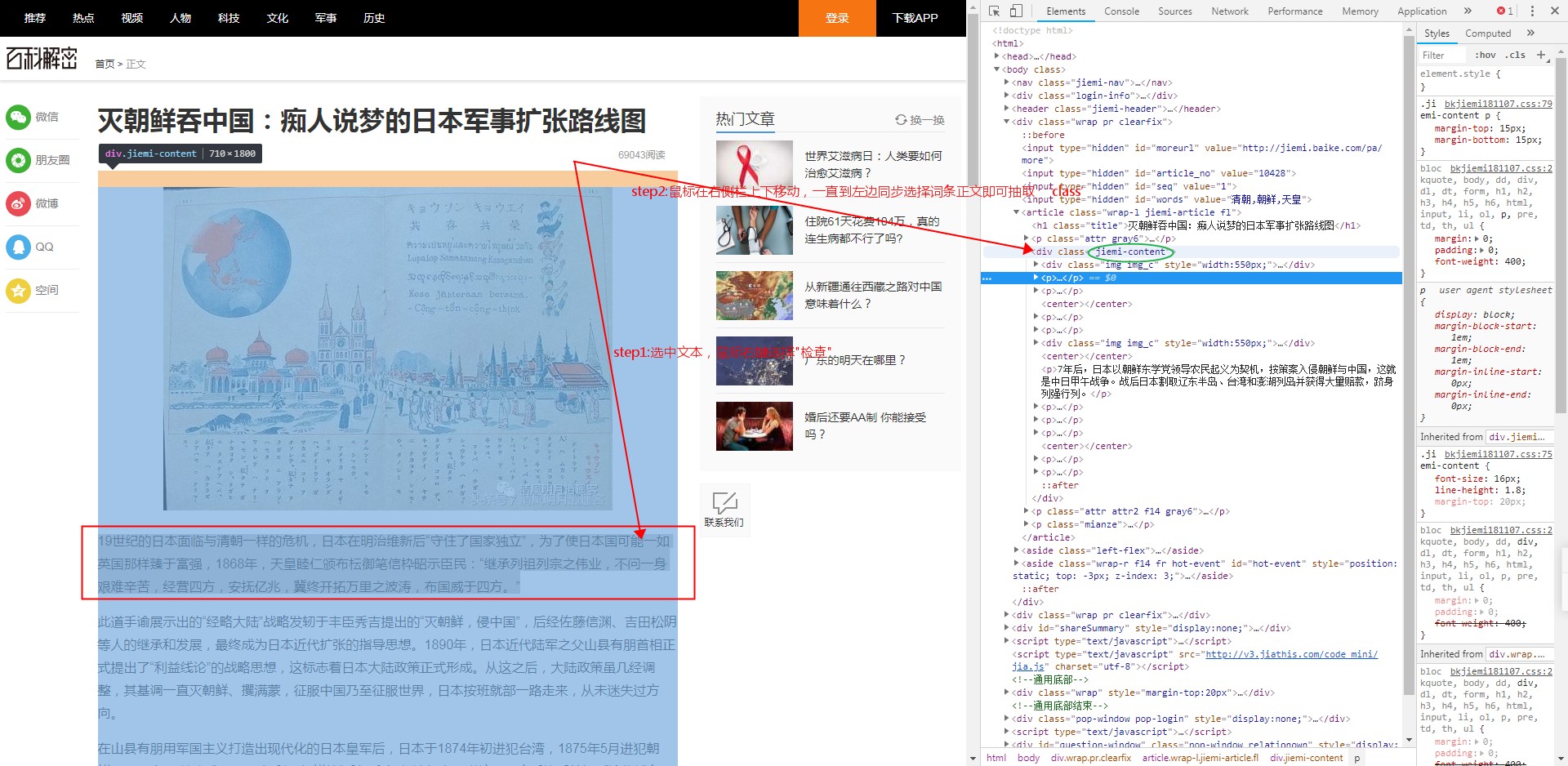
a)如何獲取載入列表的js請求地址和請求引數格式

b)如從詞條詳情頁獲取正文的css樣式 ?
2.2 程式碼實現
step1:收集詞條id列表並儲存到redis
1 def fetch_seeds(): 2 print "-- fetch seeds --" 3 cnt = 0 4 for def_index in range(4, 10): 5 ret = do_run(index=def_index)6 cnt += ret 7 print("cnt = %d" % cnt) 8 9 def do_run(index, page_num=100): 10 artical_list = [] 11 for pn in range(1, page_num + 1): 12 try: 13 url = 'http://api.hudong.com/flushjiemi.do?flag=2&topic=%d&page=%d&type=2' % (index, pn) 14 retText = fetch(url)15 print("ret = %s" % retText) 16 ret_json = json.loads(retText, encoding='utf-8') 17 result = ret_json["result"] 18 if len(result) > 0: 19 for ob in result: 20 # artical_list.append(ob["article_topic_name"]) 21 # artical_list.append("%s%s%s" % (ob["article_topic_name"], "-", ob["article_id"])) 22 artical_list.append(ob["article_id"]) 23 save2redis(index, artical_list) 24 # sleep 25 if pn % 5 == 0: 26 print 'pn=%d, sleeping...' % pn 27 time.sleep(1) 28 except: 29 print "http get or parse error!" 30 31 return 1 32 33 def save2redis(index, article_list): 34 r = redis.Redis(host=redis_db_host, port=redis_db_port, db=redis_db_index) 35 for article in article_list: 36 r.sadd("%s-%d" % ("news.set", index), article)
step2:抓取詞條詳情並儲存到redis
1 def fetch_detail(): 2 print "-- fetch detail --" 3 r = redis.Redis(host=redis_db_host, port=redis_db_port, db=redis_db_index) 4 cnt = 0 5 for news_index in range(4, 10): 6 seeds = r.smembers("%s-%s" % ("news.set", news_index)) 7 if len(seeds) > 0: 8 for seed in seeds: 9 try: 10 ret = crawl(seed) 11 cnt += 1 12 if cnt % 10 == 0: 13 time.sleep(2) 14 print 'cnt=%d, sleeping...' % cnt 15 # save to redis 16 save_detail(seed, result=ret) 17 # break # unit test 18 except: 19 print "fetch detail error!!!" 20 pass 21 22 def crawl(page_no): 23 url = 'http://jiemi.baike.com/pa/detail?id=%s&type=1' % page_no 24 print "url=", url 25 content = fetch(url) 26 soup = BeautifulSoup(content, "html.parser") 27 return fetch_with_class(soup, class_type="jiemi-content") 28 29 def save_detail(seed, result=""): 30 r = redis.Redis(host=redis_db_host, port=redis_db_port, db=redis_db_index_2) 31 r.set("id_%s" % seed, result) 32 return 1
- 附
1)環境說明 python2.7, redis4.x
2)github專案完整原始碼 https://github.com/SeaSky0606/baike-crawler
3)為維護網路和諧,詞條資料僅適用於研究與學習,請勿惡意抓取。