
Auto-encoders、RBM和CNN的區別
Auto-encoders、RBM和CNN的區別
學DL的過程中,發現有DL也有自己的分支,一個RBM構成的DBN(深度信念網路),一個是用CNN(卷積神經網路),都瞭解一點,卻說不清它們之間的區別,所以整理了一下:
Autoencoder is a simple 3-layer neural network where output units are directly connected back to input units. E.g. in a network like this:
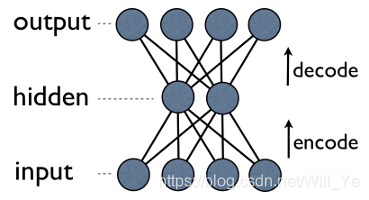
has edge back to
for every
. Typically, number of hidden units is much less then number of visible (input/output) ones. As a result, when you pass data through such a network, it first compresses (encodes) input vector to “fit” in a smaller representation, and then tries to reconstruct (decode) it back. The task of training is to minimize an error or reconstruction, i.e. find the most efficient compact representation (encoding) for input data.
RBM shares similar idea, but uses stochastic approach. Instead of deterministic (e.g. logistic or ReLU) it uses stochastic units with particular (usually binary of Gaussian) distribution. Learning procedure consists of several steps of Gibbs sampling (propagate: sample hiddens given visibles; reconstruct: sample visibles given hiddens; repeat) and adjusting the weights to minimize reconstruction error.
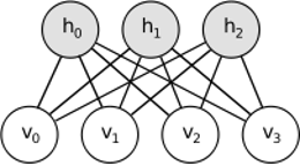
Intuition behind RBMs is that there are some visible random variables (e.g. film reviews from different users) and some hidden variables (like film genres or other internal features), and the task of training is to find out how these two sets of variables are actually connected to each other.
具體的RBM介紹可以看看原文,請點
Convolutional Neural Networks are somewhat similar to these two, but instead of learning single global weight matrix between two layers, they aim to find a set of locally connected neurons. CNNs are mostly used in image recognition. Their name comes from “convolution” operator or simply “filter”. In short, filters are an easy way to perform complex operation by means of simple change of a convolution kernel. Apply Gaussian blur kernel and you’ll get it smoothed. Apply Canny kernel and you’ll see all edges. Apply Gabor kernel to get gradient features.
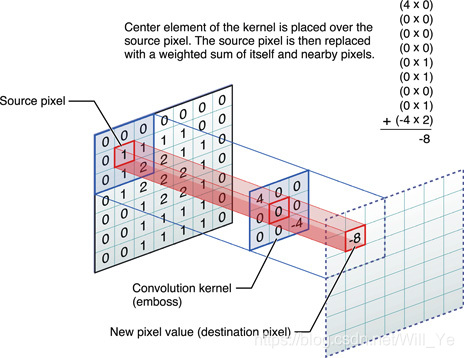
The goal of convolutional neural networks is not to use one of predefined kernels, but instead to learn data-specific kernels. The idea is the same as with autoencoders or RBMs - translate many low-level features (e.g. user reviews or image pixels) to the compressed high-level representation (e.g. film genres or edges) - but now weights are learned only from neurons that are spatially close to each other.

更詳細的資料可以 點這裡
這三種模型都有它們的應用場景,各有優缺點,歸納了一下它們的主要特點:
-
Auto-encoders 是最簡單的一個模型.,比較容易直觀的理解和應用,也體現了它的可解釋性,相比起RBM,它更容易找到比較好的引數parameters.
-
RBM 是可生成的,也就是說,不像autoencoders那樣只區分某些data的向量,RBMs還可以通過給定的聯合分佈生成新的資料。它的功能更豐富、更靈活。由RBM構成的DBN深度信念網路與CNN也一樣,之間有交叉,也有不同,DBN是一種無監督的機器學習模型,而CNN則是有監督的機器學習模型。
-
CNNs 是應用在具體任務的模型. 目前影象識別中的大多數頂層演算法都是基於cnn的, 但在這個領域之外,它幾乎不適用(比如,用卷積分析電影的原因是什麼?)
都是一些暫時的理解,以後有新的認識再更新。