Ubuntu下搭建spark2.4環境(單機版)
說明:單機版的Spark的機器上只需要安裝JDK即可,其他諸如Hadoop、Zookeeper(甚至是scala)之類的東西可以一概不安裝。
叢集版搭建:Spark2.2叢集部署和配置
一、安裝JDK1.8
1、下載JDK1.8,地址
2、將下載的檔案儲存在 /home/qq/java下,進行解壓,解壓後文件夾為 jdk1.8.0_171:
tar -zxvf jdk-8u171-linux-i586.tar.gz
3、配置JDK環境,輸入命令:
sudo vim ~/.bashrc
在檔案末尾加入:
export JAVA_HOME=/home/qq/java/jdk1.8.0_171 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
使用命令:wq儲存退出,執行命令生效:
source ~/.bashrc
4、測試JDK
輸入命令:
java -version
輸出:
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) Client VM (build 25.171-b11, mixed mode)
JDK安裝成功。
二、安裝spark2.2.0
1、使用命令
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
下載檔案,並將其放在 /home/qq/spark 資料夾下。
或者先下載再傳入ubuntu
2、解壓,改名(之前名字太長,改成spark-2.2.0)
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0
3、配置環境,開啟檔案sudo vi /etc/profile,在末尾加入:
export SPARK_HOME=/home/qq/spark/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin
輸入:
source /etc/profile
使環境變數生效。
4、配置spark環境
開啟資料夾spark-2.4.0,首先我們把快取的檔案spark-env.sh.template改為spark識別的檔案spark-env.sh:
cp conf/spark-env.sh.template conf /spark-env.sh
開啟修改spark-env.sh檔案,
vi conf/spark-env.sh
在末尾加入:
export JAVA_HOME=/home/qq/java/jdk1.8.0_171
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
變數說明
JAVA_HOME:Java安裝目錄
SPARK_MASTER_IP:spark叢集的Master節點的ip地址
SPARK_WORKER_MEMORY:每個worker節點能夠最大分配給exectors的記憶體大小
SPARK_WORKER_CORES:每個worker節點所佔有的CPU核數目
SPARK_WORKER_INSTANCES:每臺機器上開啟的worker節點的數目
其次,修改slaves檔案,
cp slaves.template slaves
vi conf/slaves
加入:
localhost
5、執行spark
spark-shell
如圖:
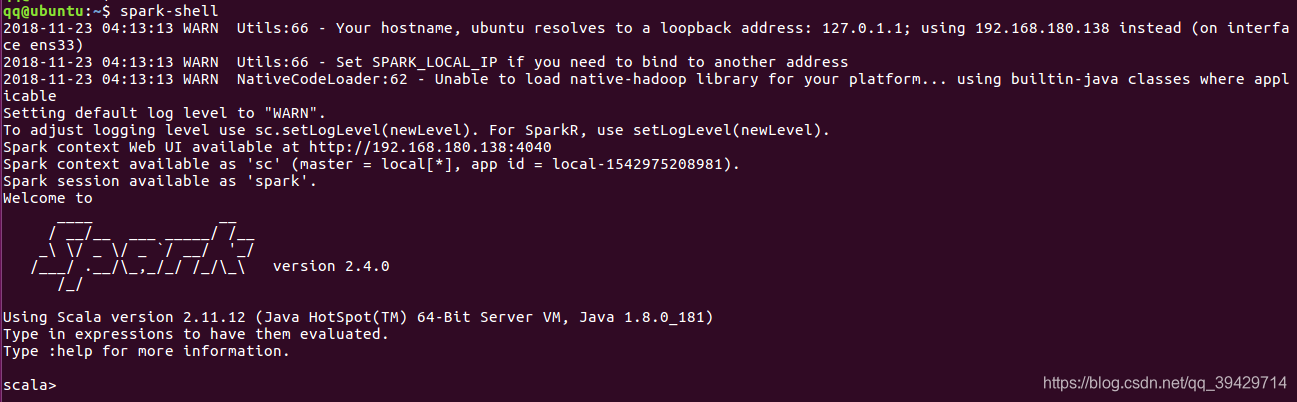
至此,安裝全部完成。
測試
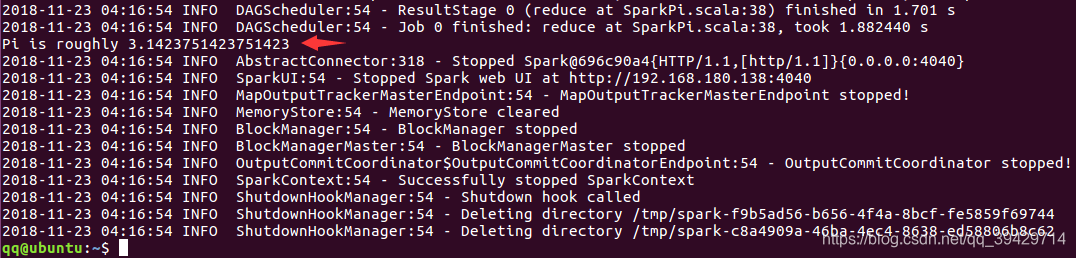
跑PI
$ run-example SparkPi 10
結果如圖: