
2018-2019-1 20189215 《Linux核心原理與分析》第九周作業
程序的切換和系統
《庖丁解牛》第八章書本知識總結
- 程序排程的時機都與中斷相關,中斷是程式執行過程中的強制性轉移,轉移到作業系統核心相應的處理程式。
- 軟中斷也叫異常,分為故障、退出和陷阱(自陷)。
程序排程時機
程序排程時機就是核心呼叫schedule函式的時機。在核心即將返回使用者空間時,核心會檢查
need_resched標記是否設定,如果設定,則呼叫schedule函式,此時是從中斷處理程式返回使用者空間的時間點作為一個固定的排程時機點。
1、中斷處理過程(包括時鐘中斷、I/O中斷、系統呼叫和異常)中,直接呼叫schedule,或者返回使用者態時根據need_resched標記呼叫schedule,總的來說是中斷處理程式主動呼叫schedule函式讓出CPU。
2、核心執行緒主動呼叫schedule函式讓出CPU,進行程序切換,也可以在中斷處理過程中進行排程,也就是說核心執行緒作為一類的特殊的程序可以主動排程,也可以被動排程。
3、使用者態程序只能被動排程,無法實現主動排程,僅能通過陷入核心態後的某個時機點進行排程,即在中斷處理過程中進行排程。已經包含在1中。排程策略與演算法
Linux系統的程序是根據優先順序來排序的,而優先順序是動態變化的。核心中根據程序的優先順序來區分普通程序與實時程序,Linux核心程序優先順序為0~139,數值越高,優先順序越低,0為最高優先順序。
實時程序的優先順序取值為0~99。
普通程序只有nice值,nice值對映到優先順序為100~139。
子程序會繼承父程序的優先順序。
實時程序的優先順序是靜態設定的,而且始終大於普通程序的優先順序,因此只有當就緒佇列中沒有實時程序的情況下,普通程序才能夠獲得排程。
同一個程序在本身優先順序不變的情況下分到的CPU時間佔比會根據系統負載變化而發生變化,即與時間片沒有一個固定的對應關係。實時程序的優先順序基本的排程策略如下:
#define SCHED_NORMAL 0 //普通程序 #define SCHED_FIFO 1 //實時程序的先進先出 #define SCHED_RR 2 //實時程序的時間片輪轉 #define SCHED_BATCH 3 //保留,未實現 #define SCHED_IDLE 5 //idle程序- 為了控制程序的執行,核心必須有能力掛起正在CPU上執行的程序,並恢復以前掛起的某個程序的執行。這種行為被稱為程序切換、任務切換或上下文切換。
在實際程式碼中,每個程序切換基本由兩個步驟組成:切換頁全域性目錄(CR3)以安裝一個新的地址空間,切換核心態對戰和硬體上下文。 程序上下文包含了程序執行需要的所有資訊,包括:
- 使用者地址空間:包括程式程式碼、資料、使用者堆疊等。
- 控制資訊:程序描述符,核心堆疊等。
- 硬體上下文,相關暫存器的值。
- 掛起正在CPU上執行的程序,與中斷時儲存現場是不同的,中斷前後是在同一個程序上下文中,只是使用者態和核心態的相互轉換,而切換程序需要在不同的程序之間切換。
Linux系統的一般執行過程(正在執行的使用者態程序X切換到執行使用者態程序Y的過程)
- 正在執行的使用者態程序X
- 發生中斷(包括異常、系統呼叫等),硬體完成:①save cs:eip/ss:esp/eflag:當前CPU上下文壓入使用者態程序X的核心堆疊。②load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack):載入當前程序核心堆疊相關資訊,跳轉到中斷處理程式,即中斷執行路徑的起點。
- SAVE_ALL,儲存現場,此時完成了中斷上下文切換,即從程序X的使用者態到程序X的核心態。
- 中斷處理過程中或中斷返回前呼叫了schedule(),其中的switch_to做了關鍵的程序上下文切換
- 標號1之後開始執行使用者態程序Y(這裡Y曾經通過以上步驟被切換出去過,因此可以從標號1繼續執行)
- restore_all ,恢復現場
- iret - pop cs:eip/ss:esp/eflags,從Y程序的核心堆疊中彈出第2步中硬體完成的壓棧內容,此時完成了中斷上下文的切換,即從程序Y的核心態返回到程序Y的使用者態。
- 繼續執行使用者態程序Y
幾種特殊情況
- 通過中斷處理過程中的排程時機,核心執行緒之間互相切換,與最一般的情況非常類似,只是核心執行緒在執行過程中發生中斷,沒有程序使用者態和核心態的轉換。
- 使用者程序向核心執行緒的切換,省略了恢復現場和iret恢復CPU上下文。
- 核心執行緒主動呼叫schedule(),只有程序上下文的切換,沒有發生中斷上下文的切換,與最一般的情況略簡略。
- 建立子程序的系統呼叫在子程序中的執行起點及返回使用者態的過程,如fork。
- 載入一個新的可執行程式後返回到使用者態的情況,如execve。
Linux作業系統的整體構架示意圖

實驗:使用cgdb跟蹤分析程序排程相關原始碼
- 按照課本配置執行MenuOS系統,跟上次一樣修改Makefile以在自己機器上自動執行

- 設定斷點,其中
switch_to是巨集定義,無法新增
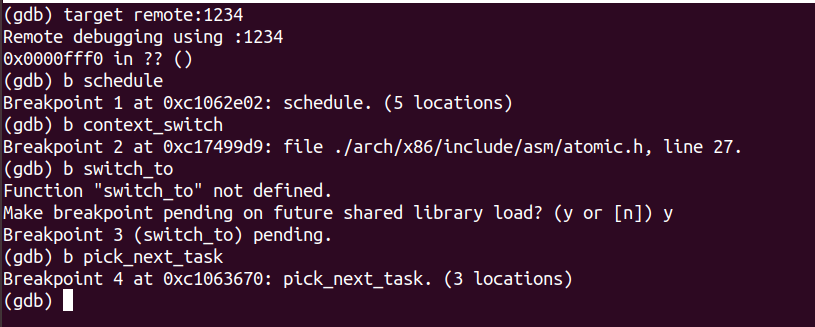
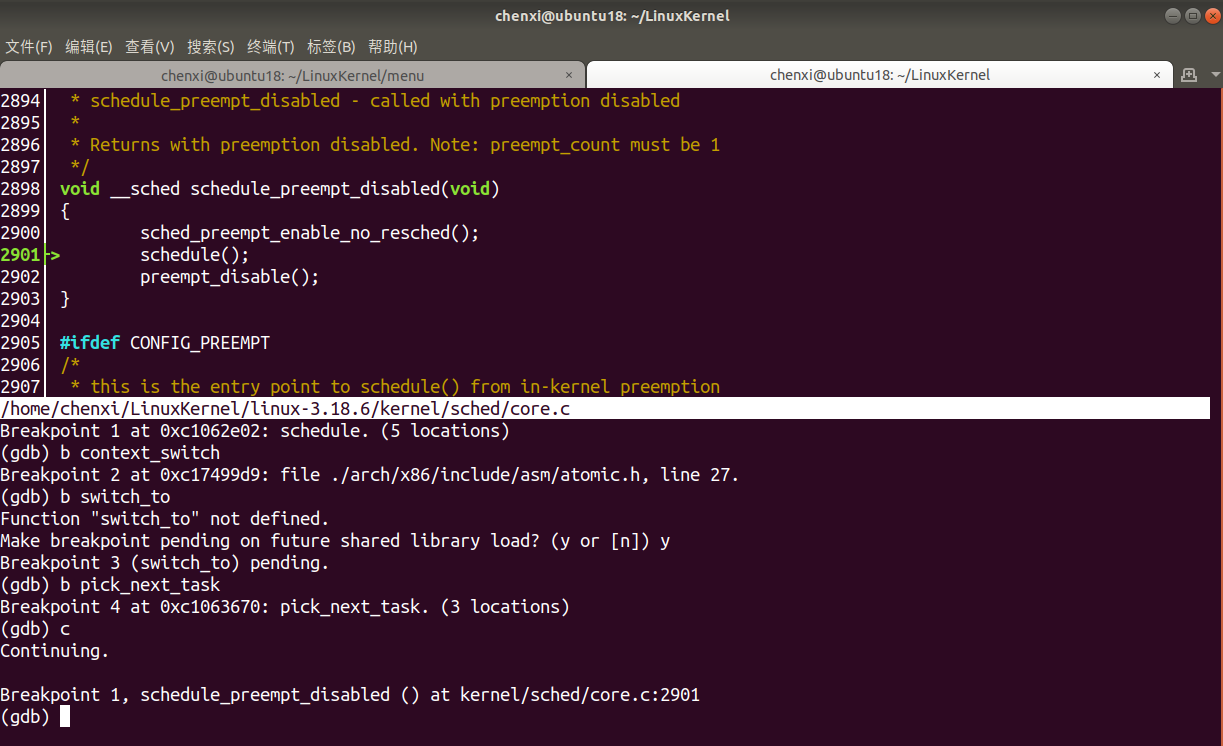
- 執行到
schedule函式斷點,呼叫了schedule,說明進行了程序排程
- 繼續執行到
pick_next_task
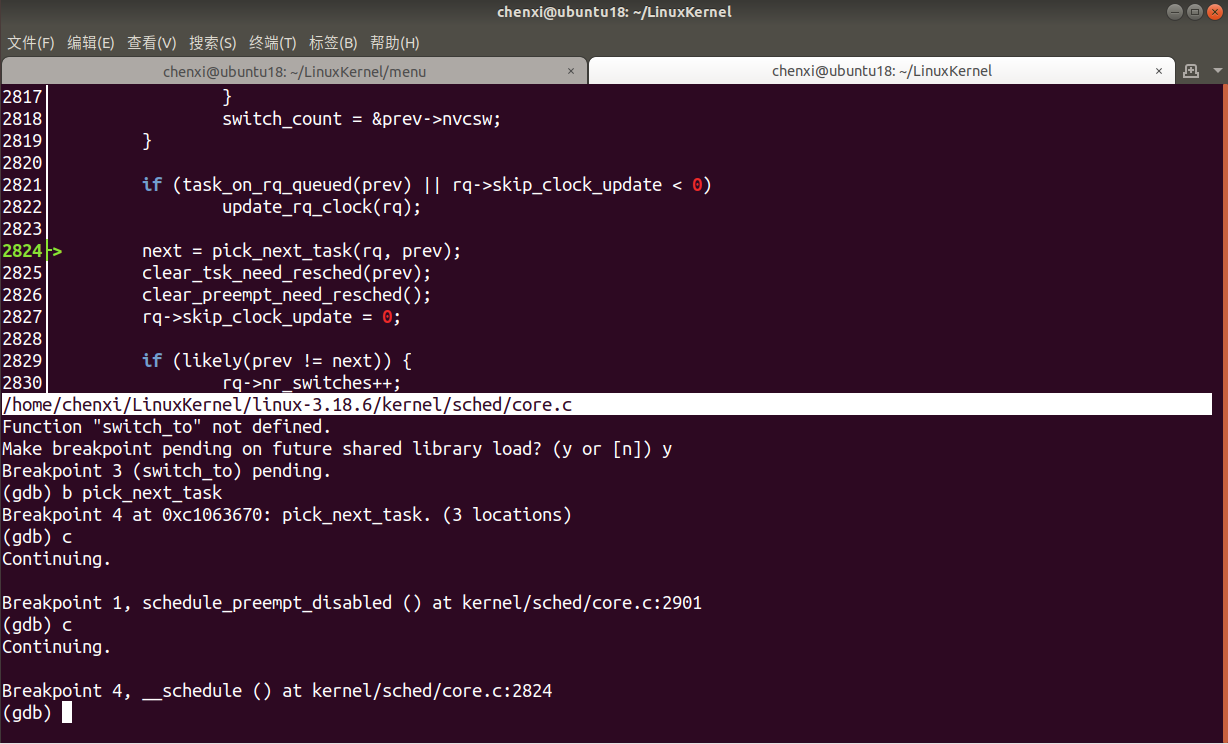
- 繼續執行到
context_switch

- 單步走並進入
context_switch函式,執行到task_switch函式中呼叫的prepare_task_switch函式
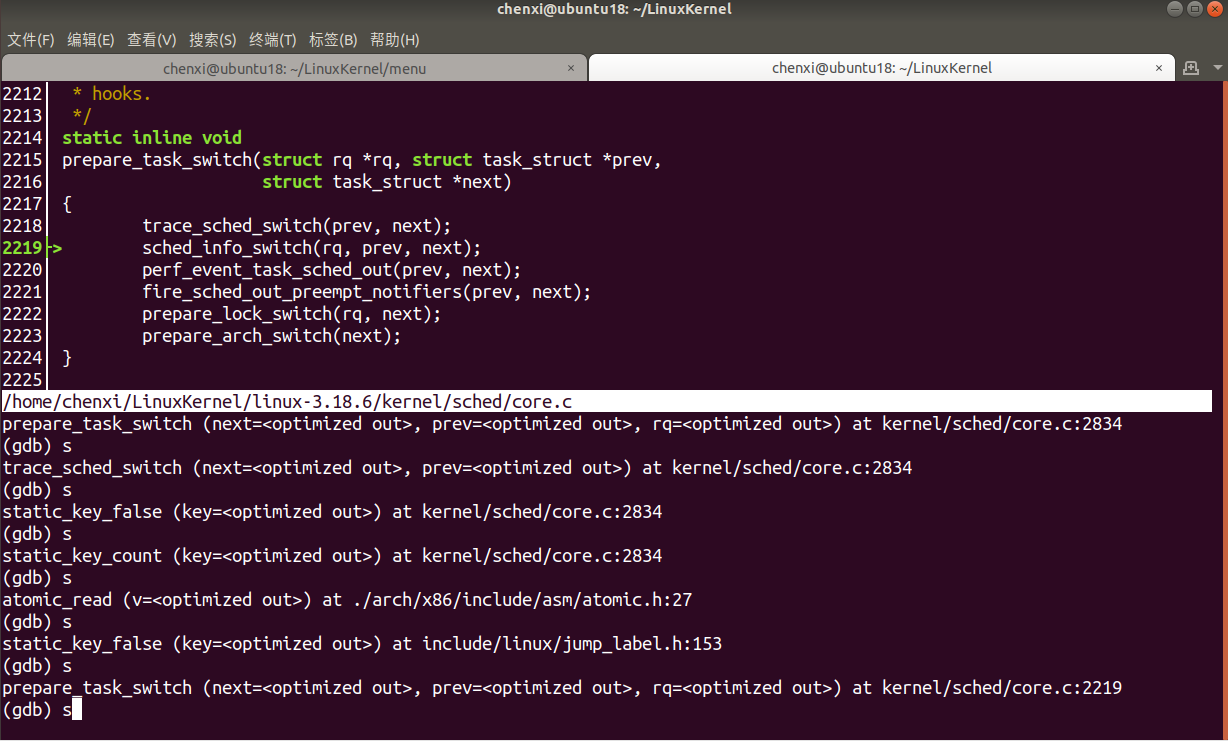
- 繼續單步,
switch_mm
- 繼續單步,開始呼叫
switch_to
- 進入
switch_to函式內部
- 結束切換

- 中斷結束,根據
need_resched判斷是否需要排程
程式碼分析
context_switch程式碼
schedule函式選擇一個新的程序來執行,並呼叫context_switch函式進行上下文的切換。
static inline void context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) { //如果被切換進來的程序的mm為空切換,核心執行緒mm為空
next->active_mm = oldmm; //將共享切換出去的程序的active_mm
atomic_inc(&oldmm->mm_count); //有一個程序共享,所有引用計數加一
enter_lazy_tlb(oldmm, next); //普通mm不為空,則呼叫switch_mm切換地址空間
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
context_tracking_task_switch(prev, next);
// Here we just switch the register state and the stack.切換暫存器狀態和棧
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
}switch_to程式碼
context_switch函式呼叫switch_to函式進行硬體上下文的切換,該函式為內聯彙編程式碼
#define switch_to(prev, next, last)
do {
/*
* Context-switching clobbers all registers, so we clobber
* them explicitly, via unused output variables.
* (EAX and EBP is not listed because EBP is saved/restored
* explicitly for wchan access and EAX is the return value of
* __switch_to())
*/
unsigned long ebx, ecx, edx, esi, edi;
asm volatile(
"pushfl\n\t" // 儲存當前程序flags
"pushl %%ebp\n\t" // 當前程序堆疊基址壓棧
"movl %%esp,%[prev_sp]\n\t" // 儲存ESP,將當前堆疊棧頂儲存起來
"movl %[next_sp],%%esp\n\t" // 更新ESP,將下一棧頂儲存到ESP中
// 完成核心堆疊的切換
"movl $1f,%[prev_ip]\n\t" // 儲存當前程序的EIP
"pushl %[next_ip]\n\t" // 將next程序起點壓入堆疊,即next程序的棧頂為起點,next_ip一般為$1f,對於新建立的子程序是ret_from_fork
__switch_canary
"jmp __switch_to\n" // prve程序中,設定next程序堆疊,jmp與call不同,是通過暫存器傳遞引數(call通過堆疊),所以ret時彈出的是之前壓入棧頂的next程序起點
// 完成EIP的切換
"1:\t" // next程序開始執行
"popl %%ebp\n\t" // restore EBP
"popfl\n" // restore flags
// 輸出量
: [prev_sp] "=m" (prev->thread.sp), // 儲存當前程序的esp
[prev_ip] "=m" (prev->thread.ip), // 儲存當前進倉的eip
"=a" (last),
// 要破壞的暫存器
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
// 輸入量
: [next_sp] "m" (next->thread.sp), // next程序的核心堆疊棧頂地址,即esp
[next_ip] "m" (next->thread.ip), // next程序的eip
// regparm parameters for __switch_to():
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: // 重新載入段暫存器
"memory");
} while (0)問題
- 書中所列
context_switch程式碼中,為if (unlikely(!mm)),但是網上的程式碼中並沒有unlikely。
likely和unlikely都是巨集定義:
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)
簡單從表面上看if(likely(value)) == if(value),if(unlikely(value)) == if(value)。 也就是likely和unlikely是一樣的,但是實際上執行是不同的,加likely的意思是value的值為真的可能性更大一些,那麼執行if的機會大,而unlikely表示value的值為假的可能性大一些,執行else機會大一些。 加上這種修飾,編譯成二進位制程式碼時likely使得if後面的執行語句緊跟著前面的程式,unlikely使得else後面的語句緊跟著前面的程式,這樣就會被cache預讀取,增加程式的執行速度。
而使用!!的原因是計算機中bool邏輯只有0和1,非0即是1,當likely(x)中引數不是邏輯值時,就可以使用!!符號轉化為邏輯值1或0 。比如:!!(3)=!(!(3))=!0=1,這樣就把引數3轉化為邏輯1了。 也不難理解為何要使用if (!mm),也是為了將判斷值轉換為邏輯0或1。 - 使用
jmp __switch_to\n的原因。
使用jmp是使用暫存器傳遞引數的,所以不會將下一條指令push到堆疊中,ret返回時會彈出之前壓入棧頂的next程序的起點,即nexp_ip。 如果用call,就會將下一條指令1: 壓棧,返回時會彈出標號1的位置。如果新的程序是剛建立的,則next_ip不是1:,而是ret_from_fork,就會出現問題。
總結
本章學習了Linux程序的切換和系統的一般執行過程,通過對程式碼過程的分析,理解了Linux系統中進行系統切換的步驟,區分了中斷和程序切換,也瞭解到了Linux所支援的排程策略,與之前學習的作業系統課程的程序排程相結合,加深了理解。也觀察了Linux系統的執行過程,明白了一般地執行過程和一些特殊情況,對前幾章的知識也有一定的鞏固深化作用。