
機器學習算法中的評價指標(準確率、召回率、F值、ROC、AUC等)
參考鏈接:https://www.cnblogs.com/Zhi-Z/p/8728168.html
具體更詳細的可以查閱周誌華的西瓜書第二章,寫的非常詳細~
一、機器學習性能評估指標

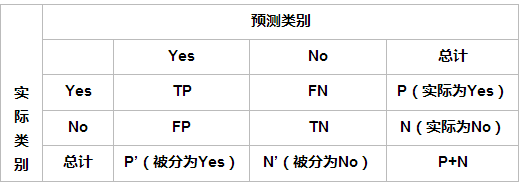
1.準確率(Accurary)

準確率是我們最常見的評價指標,而且很容易理解,就是被分對的樣本數除以所有的樣本數,通常來說,正確率越高,分類器越好。
準確率確實是一個很好很直觀的評價指標,但是有時候準確率高並不能代表一個算法就好。比如某個地區某天地震的預測,假設我們有一堆的特征作為地震分類的屬性,類別只有兩個:0:不發生地震、1:發生地震。一個不加思考的分類器,對每一個測試用例都將類別劃分為0,那那麽它就可能達到99%的準確率,但真的地震來臨時,這個分類器毫無察覺,這個分類帶來的損失是巨大的。為什麽99%的準確率的分類器卻不是我們想要的,因為這裏數據分布不均衡,類別1的數據太少,完全錯分類別1依然可以達到很高的準確率卻忽視了我們關註的東西。再舉個例子說明下。在正負樣本不平衡的情況下,準確率這個評價指標有很大的缺陷。比如在互聯網廣告裏面,點擊的數量是很少的,一般只有千分之幾,如果用acc,即使全部預測成負類(不點擊)acc也有 99% 以上,沒有意義。因此,單純靠準確率來評價一個算法模型是遠遠不夠科學全面的。
2、錯誤率(Error rate)

錯誤率則與準確率相反,描述被分類器錯分的比例,對某一個實例來說,分對與分錯是互斥事件,所以accuracy =1 - error rate。
3、查準率(Precision)
查準率(precision)定義為: 
表示被分為正例的示例中實際為正例的比例。
4、查全率(召回率)(recall)

召回率是覆蓋面的度量,度量有多個正例被分為正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率與靈敏度是一樣的。
5、綜合評價指標(F-Measure)
P和R指標有時候會出現的矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F-Measure(又稱為F-Score)。 F-Measure是Precision和Recall加權調和平均:

當參數α=1時,就是最常見的F1,也即 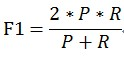
可知F1綜合了P和R的結果,當F1較高時則能說明試驗方法比較有效。
6、靈敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分對的比例,衡量了分類器對正例的識別能力。
7、特效度(sensitive)
specificity = TN/N,表示的是所有負例中被分對的比例,衡量了分類器對負例的識別能力。
8、其他評價指標
8.1 ROC曲線
ROC(Receiver Operating Characteristic)曲線是以假正率(FP_rate)和真正率(TP_rate)為軸的曲線,ROC曲線下面的面積我們叫做AUC,如下圖所示

 ,
,
(1)曲線與FP_rate軸圍成的面積(記作AUC)越大,說明性能越好,即圖上L2曲線對應的性能優於曲線L1對應的性能。即:曲線越靠近A點(左上方)性能越好,曲線越靠近B點(右下方)曲線性能越差。
(2)A點是最完美的performance點,B處是性能最差點。
(3)位於C-D線上的點說明算法性能和random猜測是一樣的,如C、D、E點;位於C-D之上(曲線位於白色的三角形內)說明算法性能優於隨機猜測,如G點;位於C-D之下(曲線位於灰色的三角形內)說明算法性能差於隨機猜測,如F點。
(4)雖然ROC曲線相比較於Precision和Recall等衡量指標更加合理,但是其在高不平衡數據條件下的的表現仍然不能夠很好的展示實際情況。
8.2、PR曲線:
即,PR(Precision-Recall),以查全率為橫坐標,以查準率為縱坐標的曲線。
舉個例子(例子來自Paper:Learning from eImbalanced Data):

假設N>>P(即Negative的數量遠遠大於Positive的數量),就算有較多N的sample被預測為P,即FP較大為9,但是由於N很大,FP_rate的值仍然可以很小0.9%,TP_rate=90%(如果利用ROC曲線則會判斷其性能很好,但是實際上其性能並不好),但是如果利用PR,P=50%,R=90%,因此在極度不平衡的數據下(Positive的樣本較少),PR曲線可能比ROC曲線更實用。
機器學習算法中的評價指標(準確率、召回率、F值、ROC、AUC等)