
Java 校招面試大全
面試準備
HBase
HBase 基礎結構

1. HMaster
- HMaster 是 HBase 主/從叢集架構的的中央節點;
- HMaster 將 Region 分配給 RegionServer,協調 RegionServer 的負載並維護叢集狀態;
- 維護表和 Region 的元資料,不參與資料的輸入/輸出過程
2. RegionServer
- 維護 HMaster 分配的 Region,並且處理對應 Region 的 I/O 請求
- 負責切分正在執行過程中變的過大的 Region
3. Zookeeper
- Zookeeper 是叢集的協調器
- HMaster 在啟動的時候把系統表載入在 Zookeeper 上
- 維護 RegionServer 的狀態,提供 HBase RegionServer 的狀態資訊
HBase 寫流程

- Client 先訪問 Zookeeper,獲取表相關的資訊,並得到對應的 RegionServer 地址,根據要插入的 Rowkey 獲取指定的 RegionServer 的資訊(如果為批量提交,會把 Rowkey 根據 HRegionLocation 進行分組);
- Client 對 RegionServer 發起寫請求(RegionServer 會進入檢查狀態,比如當前的 Region 是否處於只讀狀態,MemoStore 的大小是否超過了 BlockingMemoStoreSize 等等),RegionServer 接受資料寫入記憶體(會依次寫入 MemoStore 和 HLog);
- 當 MemStore 大小達到一定的值後,flush 到 StoreFile 並存儲到 HDFS 中。如果 StoreFile 達到一定的閾值,會觸發 Split 機制,將 Region 一分為二,然後 HMaster 給兩個 Region 分配相應的 RegionServer 進行管理,從而分擔壓力。
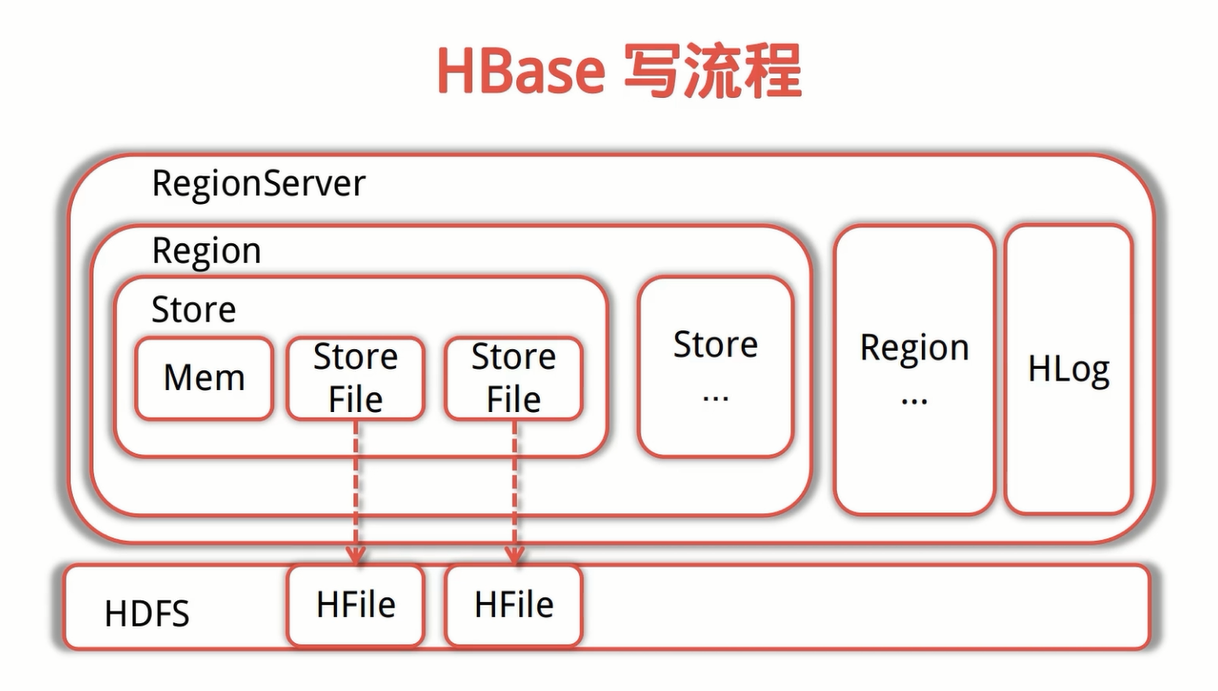
- RegionServer:RegionServer上有一個或者多個Region。我們讀寫的資料就儲存在Region上。如果你的HBase是基於HDFS的,那麼Region所有資料存取操作都是呼叫了HDFS的客戶端介面來實現的。
- Region:表的一部分資料。HBase是一個會自動分片的資料庫。一個Region就相當於關係型資料庫中分割槽表的一個分割槽,或者MongoDB的一個分片。每一個Region都有起始rowkey和結束rowkey,代表了它所儲存的row範圍。
- HDFS:Hadoop的一部分。HBase並不直接跟伺服器的硬碟互動,而是跟HDFS互動,所以HDFS是真正承載資料的載體。
- HLog:每一個 RegionServer都會有一個HLog示例,並且將操作寫在裡面。 HLog是WAL(Write-Ahead Log,預寫日誌)的一個實現例項。WAL是一個保險機制,資料在寫到Memstore之前,先被寫到WAL了。這樣當故障恢復的時候可以從WAL中恢復資料。
HBase 讀流程
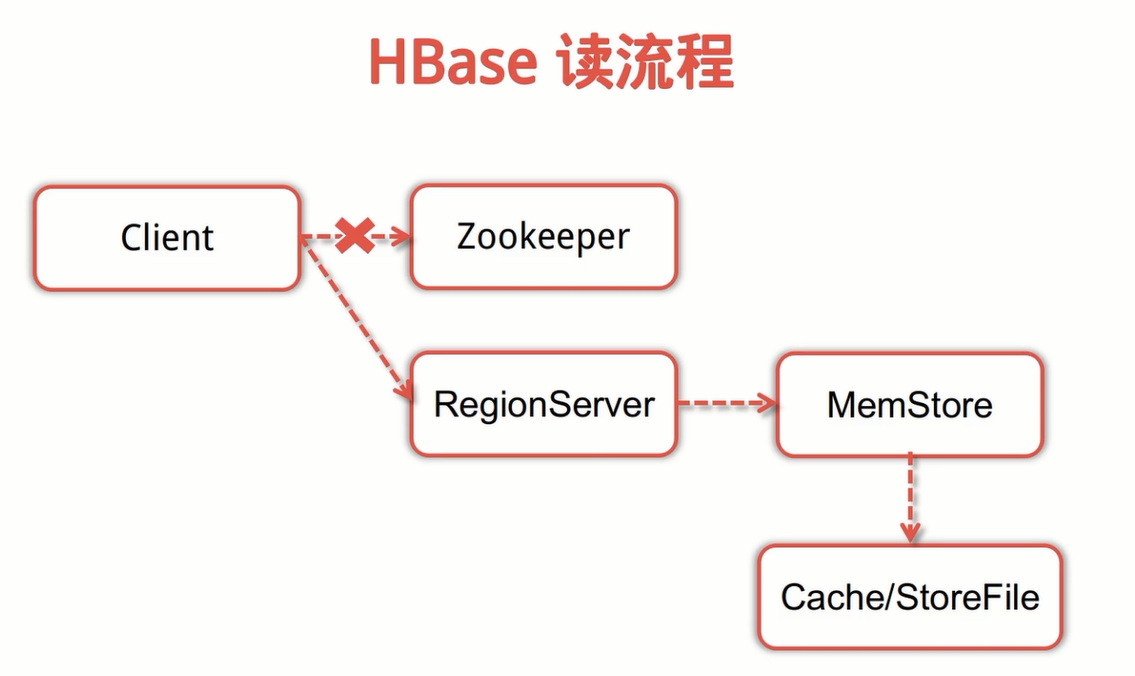
- Client 先訪問 Zookeeper,得到對應的 RegionServer 地址;
- Client 對 RegionServer 發起讀請求;
- 當 RegionServer 收到 Client 的讀請求的時候,先掃描自己的 Memstore,再掃描 BlockCache(加速讀內容緩衝區),如果還沒有找到相應的資料,則從 StoreFile 中讀取資料,然後將資料返回給 Client。
為什麼 Client 只需要訪問 Zookeeper?
HMaster 啟動的時候會把 Meta 的資訊表記錄在 Zookeeper 中。這個元資料資訊表儲存了 HBase 中所有的表,以及 Region 的詳細資訊。如 Region 開始和結束的 Key,所在的 RegionServer 的地址。HBASE 的 Meta 表相當於一個目錄。通過訪問 Meta 表可以快速的定位到資料的實際位置,所以讀寫操作只需要與 Zookeeper 和對應的 RegionServer 進行互動,而 HMaster 只需要負責維護 table 和 Region 的元資料資訊,協調各個 RegionServer,也因此減少了 HMaster 的負載。
參考資料
面向物件設計原則
S.O.L.I.D
| 簡寫 | 全拼 | 中文翻譯 |
|---|---|---|
| SRP | The Single Responsibility Principle | 單一責任原則 |
| OCP | The Open Closed Principle | 開放封閉原則 |
| LSP | The Liskov Substitution Principle | 里氏替換原則 |
| ISP | The Interface Segregation Principle | 介面分離原則 |
| DIP | The Dependency Inversion Principle | 依賴倒置原則 |
1. 單一責任原則
修改一個類的原因應該只有一個。
換句話說就是讓一個類只負責一件事,當這個類需要做過多事情的時候,就需要分解這個類。
如果一個類承擔的職責過多,就等於把這些職責耦合在了一起,一個職責的變化可能會削弱這個類完成其它職責的能力。
2. 開放封閉原則
類應該對擴充套件開放,對修改關閉。
擴充套件就是新增新功能的意思,因此該原則要求在新增新功能時不需要修改程式碼。
符合開閉原則最典型的設計模式是裝飾者模式,它可以動態地將責任附加到物件上,而不用去修改類的程式碼。
3. 里氏替換原則
子類物件必須能夠替換掉所有父類物件。
繼承是一種 IS-A 關係,子類需要能夠當成父類來使用,並且需要比父類更特殊。
如果不滿足這個原則,那麼各個子類的行為上就會有很大差異,增加繼承體系的複雜度。
4. 介面分離原則
不應該強迫客戶依賴於它們不用的方法。
因此使用多個專門的介面比使用單一的總介面要好。
5. 依賴倒置原則
高層模組不應該依賴於低層模組,二者都應該依賴於抽象;
抽象不應該依賴於細節,細節應該依賴於抽象。
高層模組包含一個應用程式中重要的策略選擇和業務模組,如果高層模組依賴於低層模組,那麼低層模組的改動就會直接影響到高層模組,從而迫使高層模組也需要改動。
依賴於抽象意味著:
- 任何變數都不應該持有一個指向具體類的指標或者引用;
- 任何類都不應該從具體類派生;
- 任何方法都不應該覆寫它的任何基類中的已經實現的方法。
Spring MVC 請求流程
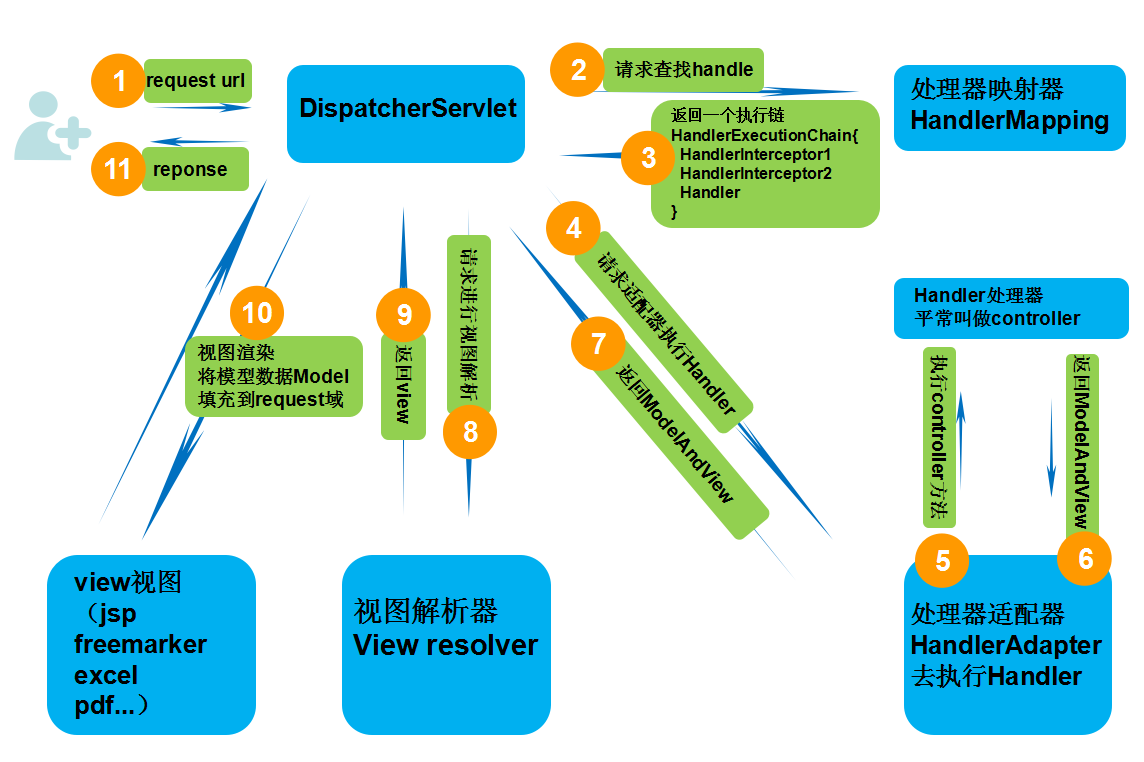
- 發起請求到前端控制器 (DispatcherServlet);
- 前端控制器請求 HandlerMapping 查詢 Handler (可以根據 xml 配置、註解進行查詢);
- 處理器對映器 HandlerMapping 向前端控制器返回 Handler,HandlerMapping 會把請求對映為 HandlerExecutionChain 物件(包含一個 Handler 處理器(頁面控制器)物件,多個 HandlerInterceptor 攔截器物件),通過這種策略模式,很容易新增新的對映策略;
- 前端控制器呼叫處理器介面卡去執行 Handler;
- 處理器介面卡 HandlerAdapter 將會根據適配的結果去執行 Handler;
- Handler 執行完成給介面卡返回 ModelAndView;
- 處理器介面卡向前端控制器返回 ModelAndView (ModelAndView 是 Spring MVC 框架的一個底層物件,包括 Model 和 view);
- 前端控制器請求檢視解析器去進行檢視解析 (根據邏輯檢視名解析成真正的檢視 (jsp)),通過這種策略很容易更換其他檢視技術,只需要更改檢視解析器即可;
- 檢視解析器向前端控制器返回 View;
- 前端控制器進行檢視渲染 (檢視渲染將模型資料 (在 ModelAndView 物件中) 填充到 request 域);
- 前端控制器向用戶響應結果。
參考資料
Spring IOC
IOC 是 Inversion of Control 的縮寫,多數書籍翻譯成“控制反轉”。
IOC 理論提出的觀點大體是這樣的:藉助於“第三方”實現具有依賴關係的物件之間的解耦。
軟體系統在沒有引入 IOC 容器之前,如圖 1 所示,物件 A 依賴於物件 B,那麼物件 A 在初始化或者執行到某一點的時候,自己必須主動去建立物件 B 或者使用已經建立的物件 B。無論是建立還是使用物件 B,控制權都在自己手上。

軟體系統在引入 IOC 容器之後,這種情形就完全改變了,如圖所示,由於 IOC 容器的加入,物件 A 與物件 B 之間失去了直接聯絡,所以,當物件 A 執行到需要物件 B 的時候,IOC 容器會主動建立一個物件 B 注入到物件 A 需要的地方。

通過前後的對比,我們不難看出來:物件 A 獲得依賴物件 B 的過程,由主動行為變為了被動行為,控制權顛倒過來了,這就是“控制反轉”這個名稱的由來。
DI 依賴注入
2004 年,Martin Fowler 探討了同一個問題,既然 IOC 是控制反轉,那麼到底是“哪些方面的控制被反轉了呢?”,經過詳細地分析和論證後,他得出了答案:“獲得依賴物件的過程被反轉了”。控制被反轉之後,獲得依賴物件的過程由自身管理變為了由 IOC 容器主動注入。於是,他給“控制反轉”取了一個更合適的名字叫做“依賴注入(Dependency Injection)”。他的這個答案,實際上給出了實現 IOC 的方法:注入。所謂依賴注入,就是由 IOC 容器在執行期間,動態地將某種依賴關係注入到物件之中。
IOC 和 DI 的區別
理解以上概念需要搞清以下問題:
- 參與者都有誰?
一般有三個參與者。 1)是某個物件;2)是 IOC/DI 的容器;3)某個物件的外部資源。
其中 1)某個物件指的是任意的,普通的 Java 物件;2)IOC/DI 容器指的是指用於實現 IOC/DI 功能的框架程式;3)物件的完畢資源指的是物件所需要的,但是需要從外部獲取的統稱為資源;比如一個物件的屬性為另外一個物件,或者是物件需要的是一個檔案資源等等。 - 依賴: 誰依賴於誰?為什麼需要依賴?
物件依賴於 IOC/DI 的容器。 因為物件需要 IOC 來提供物件所需要的外部資源。 - 注入:誰注入誰?到底注入什麼?
IOC/DI 容器注入某個物件。 注入某個物件所需要的外部資源。 - 控制反轉:誰控制誰?控制了什麼?為什麼叫反轉(有反轉就應該有正轉)?
是 IOC 容器控制物件,主要是控制了物件例項的建立。
反轉是針對正向而言,正向是針對常規下的應用程式而言的。正規應用程式下,如果要在 A 裡面使用 C,則會直接建立 C 的物件。,也就是說,是在 A 類中主動去獲取所需要的外部資源 C,這種情況被稱為正向的。
那麼什麼是反向呢?就是 A 類不再主動去獲取 C,而是被動等待,等待 IoC/DI 的容器獲取一個 C 的例項,然後反向的注入到 A 類中。 - 依賴注入和控制反轉是同一概念麼?
依賴注入和控制反轉是對同一件事情的不同描述,從某個方面講,就是它們描述的角度不同。
依賴注入是從應用程式的角度在描述,可以把依賴注入描述完整點:應用程式依賴容器建立並注入它所需要的外部資源;
而控制反轉是從容器的角度在描述。描述完整點:容器控制應用程式,由容器反向的嚮應用程式注入應用程式所需要的外部資源。
Spring AOP
AOP(Aspect Orient Programming),我們一般稱為面向方面(切面)程式設計,作為面向物件的一種補充。它利用一種稱為“橫切”的技術,剖解開封裝的物件內部,並將那些影響了多個類的公共行為封裝到一個可重用模組,並將其名為“Aspect”,即方面。
所謂“方面”,簡單地說,就是將那些與業務無關,卻為業務模組所共同呼叫的邏輯或責任封裝起來,便於減少系統的重複程式碼,降低模組間的耦合度,並有利於未來的可操作性和可維護性。
AOP 常見的使用場景
- Authentication 許可權
- Caching 快取
- Context passing 內容傳遞
- Error handling 錯誤處理
- Lazy loading 懶載入
- Debugging 除錯
- logging, tracing, profiling and monitoring 記錄跟蹤 優化 校準
- Performance optimization 效能優化
- Persistence 持久化
- Resource pooling 資源池
- Synchronization 同步
- Transactions 事務
實現原理
Spring AOP 使用的動態代理,所謂的動態代理就是說 AOP 框架不會去修改位元組碼,而是在記憶體中臨時為方法生成一個 AOP 物件,這個 AOP 物件包含了目標物件的全部方法,並且在特定的切點做了增強處理,並回調原物件的方法。
Spring AOP 中的動態代理方法主要有兩種:
- JDK 動態代理:JDK 動態代理通過反射來接收被代理的類,並且要求被代理的類必須實現一個介面。JDK 動態代理的核心是 InvocationHandler 介面和 Proxy 類。
- CGLIB 動態代理:如果目標類沒有實現介面,那麼 Spring AOP 會選擇使用 CGLIB 來動態代理目標類。CGLIB(Code Generation Library),是一個程式碼生成的類庫,可以在執行時動態的生成某個類的子類,注意,CGLIB 是通過繼承的方式做的動態代理,因此如果某個類被標記為 final,那麼它是無法使用 CGLIB 做動態代理的。
JDK 與 Cglib 代理對比
- JDK 只能針對有介面的類的介面方法進行動態代理。
- Cglib 基於繼承實現代理,無法對 static 或者 final 類進行代理。
- Cglib 基於繼承實現代理,也無法對 private 或者 static 方法進行代理。
Spring AOP 對兩種方法的選擇
-
如果目標物件實現了介面,則預設採用 JDK 動態代理。
-
如果目標物件沒有實現介面,則預設採用 Cglib 進行動態代理。
-
如果目標物件實現了介面,則強制 Cglib 代理,則採用 Cglib 進行代理。
// 採用註解開啟強制代理 @EnableAspectJAutoProxy(proxyTragetClass = true)
參考資料
Spring Bean 的初始化流程
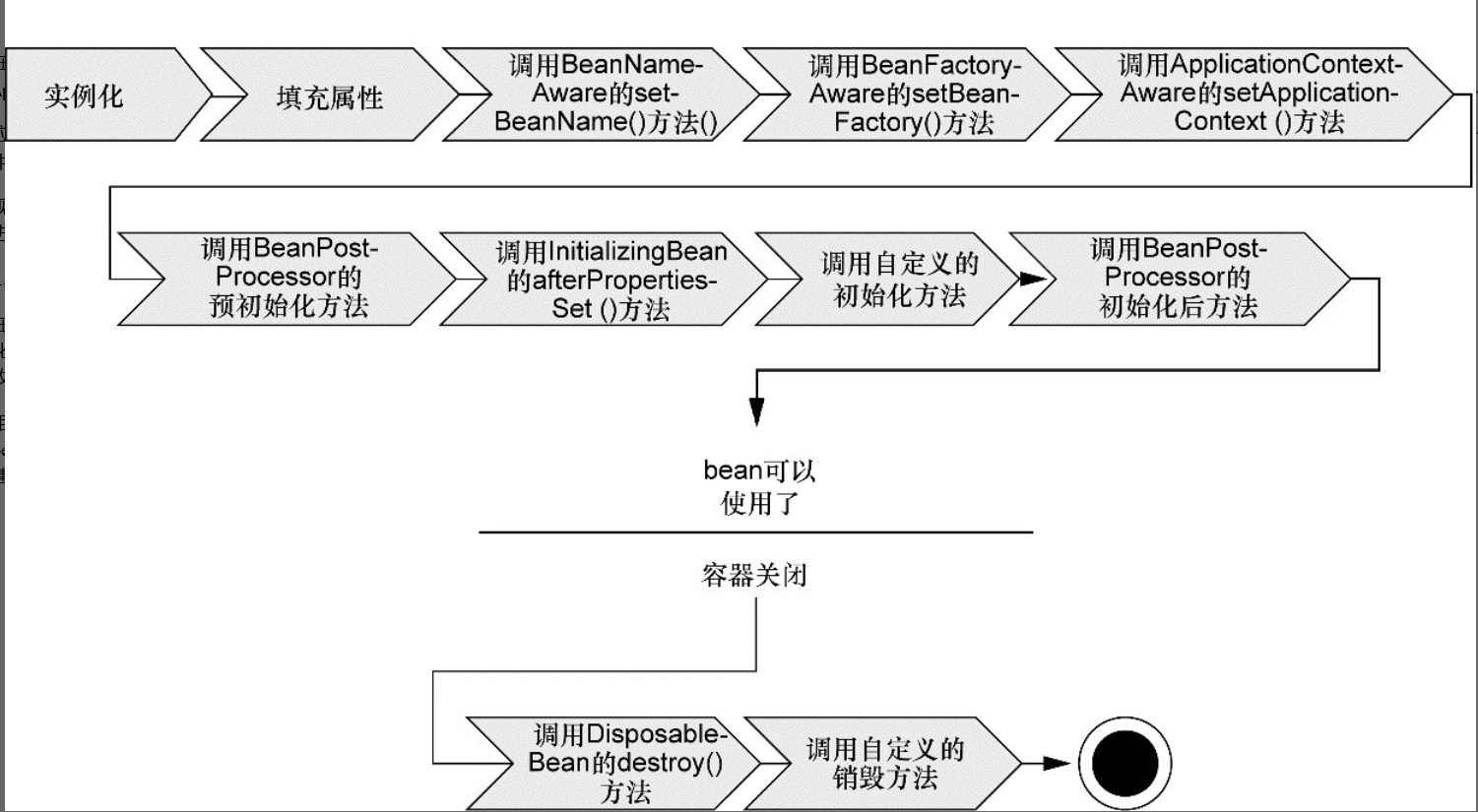
- Spring 對 bean 進行例項化;
- Spring 將值和 bean 的引用注入到 bean 對應的屬性中;
- 如果 bean 實現了 BeanNameAware 介面,Spring 將 bean 的 ID 傳遞給 setBeanName() 方法;
- 如果 bean 實現了 BeanFactoryAware 介面,Spring 將呼叫 setBeanFactory() 方法,將 BeanFactory 容器例項傳入;
- 如果 bean 實現了 ApplicationContextAware 介面,Spring 將呼叫 setApplicationContext() 方法,將 bean 所在的應用上下文的引用傳入進來;
- 如果 bean 實現了 BeanPostProcessor 介面,Spring 將呼叫它們的 postProcessBeforeInitialization() 方法;
- 如果 bean 實現了 InitializingBean 介面,Spring 將呼叫它們的 after-PropertiesSet() 方法。類似地,如果 bean 使用 init-method 聲明瞭初始化方法,該方法也會被呼叫;
- 如果 bean 實現了 BeanPostProcessor 介面,Spring 將呼叫它們的 post-ProcessAfterInitialization() 方法;
- 此時,bean 已經準備就緒,可以被應用程式使用了,它們將一直駐留在應用上下文中,直到該應用上下文被銷燬;
- 如果 bean 實現了 DisposableBean 介面,Spring 將呼叫它的 destroy() 介面方法。同樣,如果 bean 使用 destroy-method 聲明瞭銷燬方法,該方法也會被呼叫。
/**
* bean的生命週期:
* bean建立---初始化----銷燬的過程
* 容器管理bean的生命週期;
* 我們可以自定義初始化和銷燬方法;容器在bean進行到當前生命週期的時候來呼叫我們自定義的初始化和銷燬方法
*
* 構造(物件建立)
* 單例項:在容器啟動的時候建立物件
* 多例項:在每次獲取的時候建立物件
*
* BeanPostProcessor.postProcessBeforeInitialization
* 初始化:
* 物件建立完成,並賦值好,呼叫初始化方法。。。
* BeanPostProcessor.postProcessAfterInitialization
* 銷燬:
* 單例項:容器關閉的時候
* 多例項:容器不會管理這個bean;容器不會呼叫銷燬方法;
*
*
* 遍歷得到容器中所有的BeanPostProcessor;挨個執行beforeInitialization,
* 一但返回null,跳出for迴圈,不會執行後面的BeanPostProcessor.postProcessorsBeforeInitialization
*
* BeanPostProcessor原理
* populateBean(beanName, mbd, instanceWrapper);給bean進行屬性賦值
* initializeBean
* {
* applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
* invokeInitMethods(beanName, wrappedBean, mbd);執行自定義初始化
* applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
*}
*
*
*
* 1)、指定初始化和銷燬方法;
* 通過@Bean指定init-method和destroy-method;
* 2)、通過讓Bean實現InitializingBean(定義初始化邏輯),
* DisposableBean(定義銷燬邏輯);
* 3)、可以使用JSR250;
* @PostConstruct:在bean建立完成並且屬性賦值完成;來執行初始化方法
* @PreDestroy:在容器銷燬bean之前通知我們進行清理工作
* 4)、BeanPostProcessor【interface】:bean的後置處理器;
* 在bean初始化前後進行一些處理工作;
* postProcessBeforeInitialization:在初始化之前工作
* postProcessAfterInitialization:在初始化之後工作
*
* Spring底層對 BeanPostProcessor 的使用;
* bean賦值,注入其他元件,@Autowired,生命週期註解功能,@Async,xxx BeanPostProcessor;
*
* @author lfy
*
*/
Spring 元件註冊
Spring 元件註冊主要有以下三種方式:
- 包掃描 + 元件標註註解(@Controller/@Service/@Repository/@Component)
缺點: 只能對自定義的類進行註解標註,無法對三方類庫中的屬性進行元件註冊 - @Bean[主要用於三方類庫中的元件註冊 ]
- @Import[可以快速給容器中匯入一個元件,其 Bean 的 id 預設為元件的全類名]
Spring 自動裝配
@Autowired
- 預設優先按照型別去容器中找對應的元件:applicationContext.getBean(BookDao.class);找到就賦值
- 如果找到多個相同型別的元件,再將屬性的名稱作為元件的 id 去容器中查詢,如
applicationContext.getBean("bookDao") - @Qualifier(“bookDao”):使用@Qualifier 指定需要裝配的元件的 id,而不是使用屬性名
- 自動裝配預設一定要將屬性賦值好,沒有就會報錯;可以使用
@Autowired(required=false); - @Primary:讓 Spring 進行自動裝配的時候,預設使用首選的 bean;(也可以繼續使用@Qualifier 指定需要裝配的 bean 的名字)
BookService{
@Autowired
BookDao bookDao;
}
@Autowired 構造器,引數,方法,屬性;都是從容器中獲取引數元件的值。
- 構造器:如果元件只有一個有參構造方法,則該有參構造器的 @Autowired 可以省略,有參構造器引數的值自動從容器中獲取。
- 方法:如果只是 @Bean 註解 + 方法引數,引數的值也會自動從容器中獲取。預設不寫 @Autowired 效果是一樣的;都能自動裝配。
- 屬性:
@Resource [JSR250]
可以和@Autowired 一樣實現自動裝配功能;預設是按照元件名稱進行裝配的;
沒有支援@Primary 功能,沒有支援 @Autowired(reqiured=false)
@Inject [JSR300]
需要匯入 javax.inject 的依賴,和 @Autowired 的功能一樣。
<!-- https://mvnrepository.com/artifact/javax.inject/javax.inject -->
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
沒有支援 @Autowired(reqiured=false) 的功能;
自動注入流程
AutowiredAnnotationBeanPostProcessor:解析完成自動裝配功能;
容器元件注入
自定義元件想要使用Spring容器底層的一些元件(ApplicationContext,BeanFactory,xxx);
自定義元件實現xxxAware;在建立物件的時候,會呼叫介面規定的方法注入相關元件;均實現 `` 介面;
把Spring底層一些元件注入到自定義的Bean中;
xxAware 均有對應的 xxxProcessor 進行值的注入;
ApplicationContextAware==》ApplicationContextAwareProcessor;
Java 讀取一個檔案, 有哪些方法, 考慮效能, 用哪一個類
檔案讀寫主要有以下集中常用的方法:
- 位元組讀寫(InputStream/OutputStream)
- 字元讀取(FileReader/FileWriter)
- 行讀取(BufferedReader/BufferedWriter)
通過測試 ,可以發現,就寫資料而言,BufferedOutputStream耗時是最短的,而效能FileWriter最差;讀資料方面,BufferedInputStream效能最好,而FileReader效能最差勁。
Java OOM
為什麼為發生 OOM
原因一般出現為以下兩點:
- 分配的少了:比如虛擬機器本身可使用的記憶體(一般通過啟動時的 VM 引數指定)太少。
- 應用用的太多,並且用完沒釋放,浪費了。此時就會造成記憶體洩露或者記憶體溢位。
其對應的兩個術語為:
- 記憶體洩露:申請使用完的記憶體沒有釋放,導致虛擬機器不能再次使用該記憶體,此時這段記憶體就洩露了,因為申請者不用了,而又不能被虛擬機器分配給別人用。
- 記憶體溢位:申請的記憶體超出了 JVM 能提供的記憶體大小,此時稱之為溢位。
解決方法
- 修改記憶體引用,常用的有軟引用、強化引用、弱引用
- 在記憶體中載入圖片時直接在記憶體中作處理,如邊界壓縮
- 動態回收記憶體
- 自定義堆記憶體大小
參考資料
- https://blog.csdn.net/osle123/article/details/52756433
- Java 中常見 OOM 的場景及解決方法
- 什麼是 java OOM?如何分析及解決 oom 問題?
HashMap 是怎麼擴容的,為什麼是 2 的冪
HashMap 中,length 為 2 的冪次方,h &(length-1)等同於求模運算 h%length
HashMap 採用這種非常規設計,主要是為了在取模和擴容時做優化,同時為了減少衝突,HashMap 定位雜湊桶索引位置時,也加入了高位參與運算的過程。
操作流程圖

參考資料
Java 垃圾回收
垃圾收集主要是針對堆和方法區進行。
程式計數器、虛擬機器棧和本地方法棧這三個區域屬於執行緒私有的,只存在於執行緒的生命週期內,執行緒結束之後也會消失,因此不需要對這三個區域進行垃圾回收。
判斷一個物件是否可回收
1.可達性分析演算法
通過 GC Roots 作為起始點進行搜尋,能夠到達到的物件都是存活的,不可達的物件可被回收。
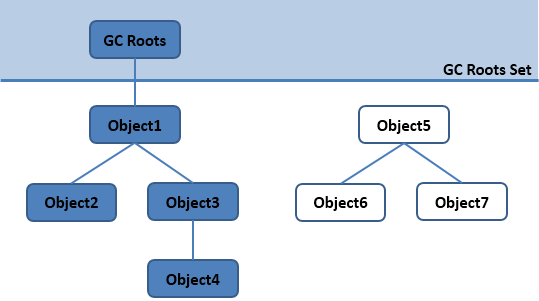
Java 虛擬機器使用該演算法來判斷物件是否可被回收,在 Java 中 GC Roots 一般包含以下內容:
- 虛擬機器棧中引用的物件
- 本地方法棧中引用的物件
- 方法區中類靜態屬性引用的物件
- 方法區中的常量引用的物件
2.方法區的回收
因為方法區主要存放永久代物件,而永久代物件的回收率比新生代低很多,因此在方法區上進行回收價效比不高。
主要是對常量池的回收和對類的解除安裝。
在大量使用反射、動態代理、CGLib 等 ByteCode 框架、動態生成 JSP 以及 OSGi 這類頻繁自定義 ClassLoader 的場景都需要虛擬機器具備類解除安裝功能,以保證不會出現記憶體溢位。
類的解除安裝條件很多,需要滿足以下三個條件,並且滿足了也不一定會被解除安裝:
- 該類所有的例項都已經被回收,也就是堆中不存在該類的任何例項。
- 載入該類的 ClassLoader 已經被回收。
- 該類對應的 Class 物件沒有在任何地方被引用,也就無法在任何地方通過反射訪問該類方法。
可以通過 -Xnoclassgc 引數來控制是否對類進行解除安裝。
Minor GC 和 Full GC
- Minor GC:發生在新生代上,因為新生代物件存活時間很短,因此 Minor GC 會頻繁執行,執行的速度一般也會比較快。
- Full GC:發生在老年代上,老年代物件其存活時間長,因此 Full GC 很少執行,執行速度會比 Minor GC 慢很多。
記憶體分配策略
1. 物件優先在 Eden 分配
大多數情況下,物件在新生代 Eden 區分配,當 Eden 區空間不夠時,發起 Minor GC。
2. 大物件直接進入老年代
大物件是指需要連續記憶體空間的物件,最典型的大物件是那種很長的字串以及陣列。
經常出現大物件會提前觸發垃圾收集以獲取足夠的連續空間分配給大物件。
-XX:PretenureSizeThreshold,大於此值的物件直接在老年代分配,避免在 Eden 區和 Survivor 區之間的大量記憶體複製。
3. 長期存活的物件進入老年代
為物件定義年齡計數器,物件在 Eden 出生並經過 Minor GC 依然存活,將移動到 Survivor 中,年齡就增加 1 歲,增加到一定年齡則移動到老年代中。
-XX:MaxTenuringThreshold 用來定義年齡的閾值。
4. 動態物件年齡判定
虛擬機器並不是永遠地要求物件的年齡必須達到 MaxTenuringThreshold 才能晉升老年代,如果在 Survivor 中相同年齡所有物件大小的總和大於 Survivor 空間的一半,則年齡大於或等於該年齡的物件可以直接進入老年代,無需等到 MaxTenuringThreshold 中要求的年齡。
5. 空間分配擔保
在發生 Minor GC 之前,虛擬機器先檢查老年代最大可用的連續空間是否大於新生代所有物件總空間,如果條件成立的話,那麼 Minor GC 可以確認是安全的。
如果不成立的話虛擬機器會檢視 HandlePromotionFailure 設定值是否允許擔保失敗,如果允許那麼就會繼續檢查老年代最大可用的連續空間是否大於歷次晉升到老年代物件的平均大小,如果大於,將嘗試著進行一次 Minor GC;如果小於,或者 HandlePromotionFailure 設定不允許冒險,那麼就要進行一次 Full GC。
Full GC 的觸發條件
對於 Minor GC,其觸發條件非常簡單,當 Eden 空間滿時,就將觸發一次 Minor GC。而 Full GC 則相對複雜,有以下條件:
1. 呼叫 System.gc()
只是建議虛擬機器執行 Full GC,但是虛擬機器不一定真正去執行。不建議使用這種方式,而是讓虛擬機器管理記憶體。
2. 老年代空間不足
老年代空間不足的常見場景為前文所講的大物件直接進入老年代、長期存活的物件進入老年代等。
為了避免以上原因引起的 Full GC,應當儘量不要建立過大的物件以及陣列。除此之外,可以通過 -Xmn 虛擬機器引數調大新生代的大小,讓物件儘量在新生代被回收掉,不進入老年代。還可以通過 -XX:MaxTenuringThreshold 調大物件進入老年代的年齡,讓物件在新生代多存活一段時間。
3. 空間分配擔保失敗
使用複製演算法的 Minor GC 需要老年代的記憶體空間作擔保,如果擔保失敗會執行一次 Full GC。具體內容請參考上面的第五小節。
4. JDK 1.7 及以前的永久代空間不足
在 JDK 1.7 及以前,HotSpot 虛擬機器中的方法區是用永久代實現的,永久代中存放的為一些 Class 的資訊、常量、靜態變數等資料。
當系統中要載入的類、反射的類和呼叫的方法較多時,永久代可能會被佔滿,在未配置為採用 CMS GC 的情況下也會執行 Full GC。如果經過 Full GC 仍然回收不了,那麼虛擬機器會丟擲 java.lang.OutOfMemoryError。
為避免以上原因引起的 Full GC,可採用的方法為增大永久代空間或轉為使用 CMS GC。
5. Concurrent Mode Failure
執行 CMS GC 的過程中同時有物件要放入老年代,而此時老年代空間不足(可能是 GC 過程中浮動垃圾過多導致暫時性的空間不足),便會報 Concurrent Mode Failure 錯誤,並觸發 Full GC。
垃圾回收演算法
CMS 收集器

CMS(Concurrent Mark Sweep),Mark Sweep 指的是標記 - 清除演算法。
分為以下四個流程:
- 初始標記:僅僅只是標記一下 GC Roots 能直接關聯到的物件,速度很快,需要停頓。
- 併發標記:進行 GC Roots Tracing 的過程,它在整個回收過程中耗時最長,不需要停頓。
- 重新標記:為了修正併發標記期間因使用者程式繼續運作而導致標記產生變動的那一部分物件的標記記錄,需要停頓。
- 併發清除:不需要停頓。
在整個過程中耗時最長的併發標記和併發清除過程中,收集器執行緒都可以與使用者執行緒一起工作,不需要進行停頓。
具有以下缺點:
- 吞吐量低:低停頓時間是以犧牲吞吐量為代價的,導致 CPU 利用率不夠高。
- 無法處理浮動垃圾,可能出現 Concurrent Mode Failure。浮動垃圾是指併發清除階段由於使用者執行緒繼續執行而產生的垃圾,這部分垃圾只能到下一次 GC 時才能進行回收。由於浮動垃圾的存在,因此需要預留出一部分記憶體,意味著 CMS 收集不能像其它收集器那樣等待老年代快滿的時候再回收。如果預留的記憶體不夠存放浮動垃圾,就會出現 Concurrent Mode Failure,這時虛擬機器將臨時啟用 Serial Old 來替代 CMS。
- 標記 - 清除演算法導致的空間碎片,往往出現老年代空間剩餘,但無法找到足夠大連續空間來分配當前物件,不得不提前觸發一次 Full GC。
7. G1 收集器
G1(Garbage-First),它是一款面向服務端應用的垃圾收集器,在多 CPU 和大記憶體的場景下有很好的效能。HotSpot 開發團隊賦予它的使命是未來可以替換掉 CMS 收集器。
堆被分為新生代和老年代,其它收集器進行收集的範圍都是整個新生代或者老年代,而 G1 可以直接對新生代和老年代一起回收。
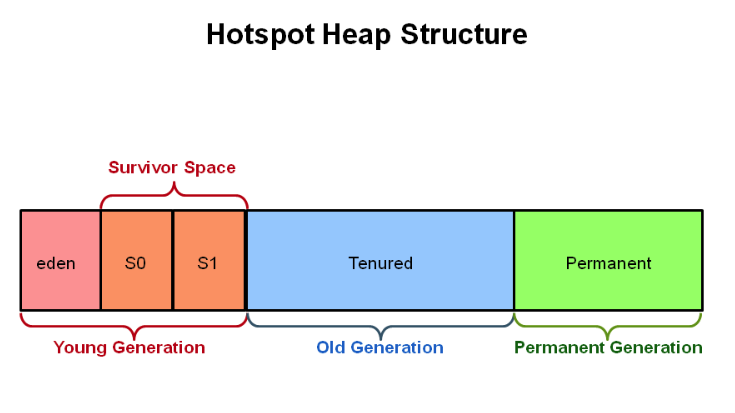
G1 把堆劃分成多個大小相等的獨立區域(Region),新生代和老年代不再物理隔離。

通過引入 Region 的概念,從而將原來的一整塊記憶體空間劃分成多個的小空間,使得每個小空間可以單獨進行垃圾回收。這種劃分方法帶來了很大的靈活性,使得可預測的停頓時間模型成為可能。通過記錄每個 Region 垃圾回收時間以及回收所獲得的空間(這兩個值是通過過去回收的經驗獲得),並維護一個優先列表,每次根據允許的收集時間,優先回收價值最大的 Region。
每個 Region 都有一個 Remembered Set,用來記錄該 Region 物件的引用物件所在的 Region。通過使用 Remembered Set,在做可達性分析的時候就可以避免全堆掃描。
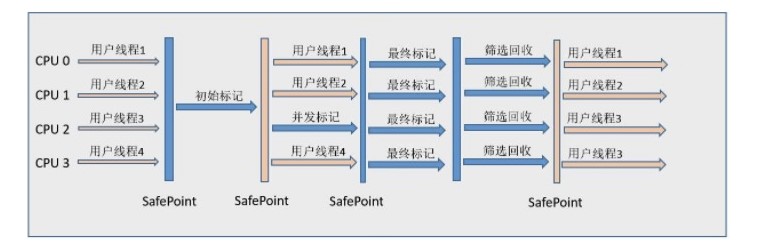
如果不計算維護 Remembered Set 的操作,G1 收集器的運作大致可劃分為以下幾個步驟:
- 初始標記
- 併發標記
- 最終標記:為了修正在併發標記期間因使用者程式繼續運作而導致標記產生變動的那一部分標記記錄,虛擬機器將這段時間物件變化記錄線上程的 Remembered Set Logs 裡面,最終標記階段需要把 Remembered Set Logs 的資料合併到 Remembered Set 中。這階段需要停頓執行緒,但是可並行執行。
- 篩選回收:首先對各個 Region 中的回收價值和成本進行排序,根據使用者所期望的 GC 停頓時間來制定回收計劃。此階段其實也可以做到與使用者程式一起併發執行,但是因為只回收一部分 Region,時間是使用者可控制的,而且停頓使用者執行緒將大幅度提高收集效率。
具備如下特點:
- 空間整合:整體來看是基於“標記 - 整理”演算法實現的收集器,從區域性(兩個 Region 之間)上來看是基於“複製”演算法實現的,這意味著執行期間不會產生記憶體空間碎片。
- 可預測的停頓:能讓使用者明確指定在一個長度為 M 毫秒的時間片段內,消耗在 GC 上的時間不得超過 N 毫秒。
Java 為什麼獲取不到函式引數名稱
在 Java 1.7 以前,編譯生成的位元組碼中並不會包含方法的引數資訊。因此無法獲取到方法的引數名稱資訊。
但是在 Java 1.8 以後,開始在 class 中儲存引數名,並且增加了對應的類Parameter。使用的示例程式碼如下:
public static List<String> getParameterNameJava8(Class clazz, String methodName){
List<String> paramterList = new ArrayList<>();
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {
if (methodName.equals(method.getName())) {
Parameter[] params = method.getParameters();
for(Parameter parameter : params){
paramterList.add(parameter.getName());
}
}
}
return paramterList;
}
如果編譯等級低於 1.8,則得到的引數名依舊為無效的引數名,例如 arg0、arg1……
同時,想要保留引數名也需要通過修改編譯選項 javac -parameters 進行開啟,預設是關閉的。
idea 設定保留引數名:
在 preferences-》Java Compiler-> 設定模組位元組碼版本 1.8,Javac Options 中的 Additional command line parameters: -parameters
參考資料
JVM 常用命令
- jinfo:可以輸出並修改執行時的 java 程序的 opts。
- jps:與 unix 上的 ps 類似,用來顯示本地的 java 程序,可以檢視本地執行著幾個 java 程式,並顯示他們的程序號。
- jstat:一個極強的監視 VM 記憶體工具。可以用來監視 VM 記憶體內的各種堆和非堆的大小及其記憶體使用量。
- jmap:打印出某個 java 程序(使用 pid)記憶體內的所有 ’ 物件 ’ 的情況(如:產生那些物件,及其數量)。
- jconsole:一個 java GUI 監視工具,可以以圖表化的形式顯示各種資料。並可通過遠端連線監視遠端的伺服器 VM。
詳細:在使用這些工具前,先用 JPS 命令獲取當前的每個 JVM 程序號,然後選擇要檢視的 JVM。
參考資料
類載入 - 雙親委派模型
Java 執行時,會根據類的完全限定名尋找並載入類,尋找的方式基本就是在系統類和指定的類路徑中尋找。
- 如果是 class 檔案的根目錄,則直接檢視是否有對應的子目錄及檔案;
- 如果是 jar 檔案,則首先在記憶體中解壓檔案,然後再檢視是否有對應的類。
負責載入類的類就是類載入器,它的輸入是完全限定的類名,輸出是 Class 物件。類載入器不是隻有一個,一般程式執行時,都會有三個(適用於 Java 9 之前)類載入器。
- 啟動類載入器(Bootstrap ClassLoader):這個載入器是 Java 虛擬機器實現的一部分,不是 Java 語言實現的,一般是 C++實現的,它負責載入 Java 的基礎類,主要是 <JAVA_HOME>/lib/rt.jar,我們日常用的 Java 類庫比如 String、ArrayList 等都位於該包內。
- 擴充套件類載入器(Extension ClassLoader):這個載入器的實現類是 sun.misc.Laun-cher$ExtClassLoader,它負責載入 Java 的一些擴充套件類,一般是 <JAVA_HOME>/lib/ext 目錄中的 jar 包。
- 應用程式類載入器(Application ClassLoader):這個載入器的實現類是 sun.misc.Launcher$AppClassLoader,它負責載入應用程式的類,包括自己寫的和引入的第三方類庫,即所有在類路徑中指定的類。
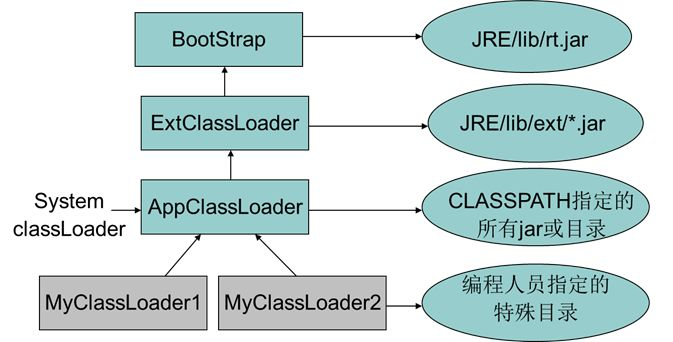
這三個類載入器有一定的關係,可以認為是父子關係,Application ClassLoader 的父親是 Extension ClassLoader,Extension 的父親是 Bootstrap ClassLoader。注意不是父子繼承關係,而是父子委派關係,即子 ClassLoader 有一個變數 parent 指向父 ClassLoader,在子 ClassLoader 載入類時,一般會首先通過父 ClassLoader 載入,具體來說,在載入一個類時,基本過程是:
- 判斷是否已經載入過了,載入過了,直接返回 Class 物件,一個類只會被一個 ClassLoader 載入一次。
- 如果沒有被載入,先讓父 ClassLoader 去載入(父類載入器為空後就使用啟動類載入器載入),如果載入成功,返回得到的 Class 物件。
- 在父 ClassLoader 沒有載入成功的前提下,自己嘗試載入類。
這個過程一般被稱為“雙親委派”模型,即優先讓父 ClassLoader 去載入。
- 這樣,每一個類都只會被載入一次,可以避免Java類庫被覆蓋的問題。比如,使用者程式也定義了一個類java.lang.String,通過雙親委派,java.lang.String只會被Bootstrap ClassLoader載入,避免自定義的String覆蓋Java類庫的定義。
- 每一個類都會被儘可能的載入(從引導類載入器往下,每個載入器都可能會根據優先次序嘗試載入它)
- 有效避免了某些惡意類的載入(比如自定義了java.lang.Object類,一般而言在雙親委派模型下會載入系統的Object類而不是自定義的Object類)
打破雙親委派
繼承 ClassLoader 重寫 loadClass 方法使得自己先載入之後嘗試父類進行資料的載入。
參考資料
執行緒池
執行緒池的建構函式如下:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory, RejectedExecutionHandler handler)
執行緒池引數
- corePoolSize:核心執行緒個數,可能處於等待狀態。
- maximumPoolSize:執行緒池允許的最大執行緒個數。
- keepAliveTime 和 unit :空閒執行緒存活時間。超出 corePoolSize 部分執行緒如果等待超過指定時間,將會被回收。如果 keepAliveTime 值為 0,則表示所有執行緒都不會超時終止。
其中對於核心執行緒數,還有以下幾點需要注意:
- 核心執行緒會一直存活,即使沒有任務需要執行
- 當執行緒數小於核心執行緒數時,即使有執行緒空閒,執行緒池也會優先建立新執行緒處理
- 設定allowCoreThreadTimeout=true(預設false)時,核心執行緒會超時關閉
任務進隊流程
- 如果當前執行緒個數小於 corePoolSize,則會建立一個新的執行緒來執行該任務。
- 如果當前執行緒個數不小於 corePoolSize,則嘗試加入阻塞佇列。
- 如果因為佇列滿了或者其他原因不能入隊,則檢查執行緒個數是否達到 maximumPoolSize,如果沒有則繼續建立執行緒直到 maximumPoolSize 個。
- 如果超過了 maximumPoolSize,則觸發拒絕策略。
step 1: <ExecutorService>
Future<?> submit(Runnable task);
step 2:<AbstractExecutorService>
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
step 3:<Executor>
void execute(Runnable command);
step 4:<ThreadPoolExecutor>
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { //提交我們的額任務到workQueue
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false)) //使用maximumPoolSize作為邊界
reject(command); //還不行?拒絕提交的任務
}
step 5:<ThreadPoolExecutor>
private boolean addWorker(Runnable firstTask, boolean core)
step 6:<ThreadPoolExecutor>
w = new Worker(firstTask); //包裝任務
final Thread t = w.thread; //獲取執行緒(包含任務)
workers.add(w); // 任務被放到works中
t.start(); //執行任務
執行緒池阻塞佇列
ThreadPoolExecutor 要求的佇列型別是阻塞佇列 BlockingQueue。
- LinkedBlockingQueue:基於連結串列的阻塞佇列,可以指定最大長度,但預設是無界的。
- ArrayBlockingQueue:基於陣列的有界阻塞佇列。
- PriorityBlockingQueue:基於堆的無界阻塞優先順序佇列。
- SynchronousQueue:沒有實際儲存空間的同步阻塞佇列。對於 SynchronousQueue,我們知道,它沒有實際儲存元素的空間,當嘗試排隊時,只有正好有空閒執行緒在等待接受任務時,才會入隊成功,否則,總是會建立新執行緒,直到達到 maximumPoolSize。
任務拒絕策略
如果佇列有界,且 maximumPoolSize 有限,則當佇列排滿,執行緒個數也達到了 maximumPoolSize。此時,新任務會觸發執行緒池的任務拒絕策略。
預設情況下,提交任務的方法(如 execute/submit/invokeAll 等)會丟擲異常,型別為 RejectedExecutionException。其中拒絕策略是可以自定義的,需要實現 RejectedExecutionHandler 介面。ThreadPoolExecutor 實現了四種方式。
- ThreadPoolExecutor.AbortPolicy:這就是預設的方式,丟擲異常。
- ThreadPoolExecutor.DiscardPolicy:靜默處理,忽略新任務,不丟擲異常,也不執行。
- ThreadPoolExecutor.DiscardOldestPolicy:將等待時間最長的任務扔掉(丟棄workQueue的頭部任務),然後自己排隊。
- ThreadPoolExecutor.CallerRunsPolicy:在任務提交者執行緒中執行任務,而不是交給執行緒池中的執行緒執行。
拒絕策略只有在佇列有界,且 maximumPoolSize 有限的情況下才會觸發。
- 如果佇列無界,服務不了的任務總是會排隊,但這不一定是期望的結果,因為請求處理佇列可能會消耗非常大的記憶體,甚至引發記憶體不夠的異常。
- 如果佇列有界但 maximumPoolSize 無限,可能會建立過多的執行緒,佔滿 CPU 和記憶體,使得任何任務都難以完成。
所以,在任務量非常大的場景中,讓拒絕策略有機會執行是保證系統穩定執行很重要的方面。
執行緒池大小設計
IO密集型
例如執行時間如果為 1s,等待時間為 5s,cpu 核數為 4,那麼應該設定的執行緒池大小為 24
關於公式的理解,因為就是一個將等待時間用來執行執行緒的思想,比如剛才那個例子:執行時間 1s,等待時間 5s,那麼等待的這段時間就可以多執行 5 / 1 個執行緒
CPU 密集型
參考資料
工廠類Executors
類 Executors 提供了一些靜態工廠方法,可以方便地建立一些預配置的執行緒池,主要方法有:
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newCachedThreadPool()
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
只使用一個執行緒,使用無界佇列 LinkedBlockingQueue,執行緒建立後不會超時終止,該執行緒順序執行所有任務。該執行緒池適用於需要確保所有任務被順序執行的場合。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
使用固定數目的 n 個執行緒,使用無界佇列 LinkedBlockingQueue,執行緒建立後不會超時終止。和 newSingleThreadExecutor 一樣,由於是無界佇列,如果排隊任務過多,可能會消耗過多的記憶體。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L,
TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
它的 corePoolSize 為 0,maximumPoolSize 為 Integer.MAX_VALUE,keepAliveTime 是 60 秒,佇列為 SynchronousQueue。它的含義是:當新任務到來時,如果正好有空閒執行緒在等待任務,則其中一個空閒執行緒接受該任務,否則就總是建立一個新執行緒,建立的匯流排程個數不受限制,對任一空閒執行緒,如果 60 秒內沒有新任務,就終止。
總結
實際中,應該使用 newFixedThreadPool 還是 newCachedThreadPool 呢?
在系統負載很高的情況下,newFixedThreadPool 可以通過佇列對新任務排隊,保證有足夠的資源處理實際的任務,而 newCachedThreadPool 會為每個任務建立一個執行緒,導致建立過多的執行緒競爭 CPU 和記憶體資源,使得任何實際任務都難以完成,這時,newFixedThreadPool 更為適用。
不過,如果系統負載不太高,單個任務的執行時間也比較短,newCachedThreadPool 的效率可能更高,因為任務可以不經排隊,直接交給某一個空閒執行緒。
在系統負載可能極高的情況下,兩者都不是好的選擇,newFixedThreadPool 的問題是佇列過長,而 newCachedThreadPool 的問題是執行緒過多,這時,應根據具體情況自定義 ThreadPoolExecutor,傳遞合適的引數。
執行緒死鎖
死鎖是指兩個或兩個以上的程序在執行過程中,由於競爭資源或者由於彼此通訊而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。此時稱系統處於死鎖狀態或系統產生了死鎖,這些永遠在互相等待的程序稱為死鎖程序。
死鎖防止
-
破除互斥等待條件 -> 一般無法破除
-
破除 hold and wait -> 一次性獲取所有資源
程式語言方面可能不支援,但是我們可以在嘗試獲取第一個鎖之後再去嘗試獲取第二