
機器學習習題(18)
1、中文同義詞替換時,常用到Word2Vec,以下說法錯誤的是
A. Word2Vec基於概率統計
B. Word2Vec結果符合當前語料環境
C. Word2Vec得到的都是語義上的同義詞
D. Word2Vec受限於訓練語料的數量和質量
參考答案:C
解析:Word2Vec是常用的詞向量表示,它採用的是同等上下文環境下的詞語具有相同的詞向量,而並非相同的含義。例如,我使用和朋友聊天。我使用<微信>和朋友聊天。這兩句話只要上下文一樣,那麼QQ和微信的詞向量表示也相同。當然也有我愛<中國>和我愛<中華人民共和國>這兩個詞在語義上的表示是相同的。
2、假定你用一個線性SVM分類器求解二類分類問題,如下圖所示,這些用紅色圓圈起來的點表示支援向量
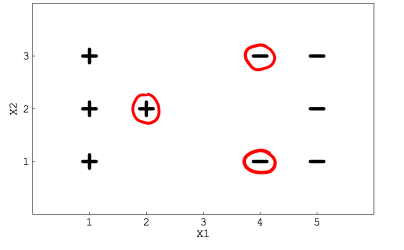
如果移除這些圈起來的資料,決策邊界(即分離超平面)是否會發生改變?
A. 會
B. 不會
參考答案:A
解析:SVM的決策邊界取決於支援向量,支援向量發生改變,其決策邊界也會發生改變。
3、如果將資料中除圈起來的三個點以外的其他資料全部移除,那麼決策邊界是否會改變?
A.會
B.不會
參考答案:B
解析:同上題。
4、關於SVM泛化誤差描述正確的是
A. 超平面與支援向量之間距離
B. SVM對未知資料的預測能力
C. SVM的誤差閾值
參考答案:B
解析:統計學中的泛化誤差是指對模型對未知資料的預測能力。
5、以下關於硬間隔hard margin描述正確的是
A. SVM允許分類存在微小誤差
B. SVM允許分類是有大量誤差
參考答案:A
解析:硬間隔的要求比較嚴格,只允許分類存在微小的誤差。
6、訓練SVM的最小時間複雜度為O(n2),那麼一下哪種資料集不適合用SVM?
A. 大資料集
B. 小資料集
C. 中等大小資料集
D. 和資料集大小無關
參考答案:A
解析:傳統機器學習方法對於大資料集都具有一定的侷限性,其根本原因在於多出來的資料並沒有對模型有太大的效能提升。例如在SVM中,只是支援點具有分類作用。
7、SVM的效率依賴於
A. 核函式的選擇
B. 核引數
C. 軟間隔引數
D. 以上所有
參考答案; D
解析:分別具有夠提高效率,降低誤差和防止過擬合。
8、支援向量是那些最接近決策平面的資料點
A. 對
B. 錯
參考答案:A
解析:支援向量就在間隔邊界上。
9、SVM在下列那種情況下表現糟糕
A. 線性可分資料
B. 清洗過的資料
C. 含噪聲資料與重疊資料點
參考答案:C
解析:當資料中含有噪聲資料與重疊的點時,要畫出乾淨利落且無誤分類的超平面很難。
10、假定你使用了一個很大γ值的RBF核,這意味著:
A. 模型將考慮使用遠離超平面的點建模
B. 模型僅使用接近超平面的點來建模
C. 模型不會被點到超平面的距離所影響
D. 以上都不正確
參考答案:B
解析:SVM調參中的γ衡量距離超平面遠近的點的影響。
對於較小的γ,模型受到嚴格約束,會考慮訓練集中的所有點。
對於較大的γ,模型僅使用接近超平面的點來建模。