
遠場語音技術簡介-001
-
什麼是遠場語音?
遠場語音是一種人與機器間的互動方式,相對與近場語音來說,區別是它的作用距離通常會在1米到10米之間,主要的技術難點在於對於多徑反射、混響效應及背景噪音干擾的處理。它的前端通常使用麥克風陣列對語音做拾取,市面上常用的配置一般有雙麥、四麥、六麥,麥的放置方式通常需要考慮應用環境和產品的結構等多重因素,最終選用方式通常是通過模擬和實測試錯進行定型,各家都有自己的經驗資料,一般不對外公佈。遠場語音最早落地的應用是智慧音箱,國內以阿里、百度等為代表推出了大眾化產品,國外以亞馬遜和谷歌為代表先於國內推出產品,值得一提的是亞馬遜目前在智慧音箱這塊的生態做的最為完善,同時新一代的智慧音箱整合有智慧家居的控制HUB功能,大大拓寬了音箱的應用場景,阿里和百度目前藉助國內的壟斷地位也開始在智慧家居領域開始佈局,宣稱在智慧音箱中嵌入藍芽MESH技術,前期通過補貼方式進行市場開拓和圈地。其他應用領域目前都在早期嘗試階段,比如教育機器人、汽車語音助手、白色智慧家電、智慧廚電等。 -
遠場語音系統架構
遠場語音系統由前端語音處理模組和後端語音識別模組組成,

目前商用的語音識別系統都是基於統計原理設計,如上面框圖所示,聲學模型用於表述聲學、麥克風、環境多樣性等可變因素,語言模型表述語言學角度定義的詞語組合方式及邏輯順序,與譯碼器的應用介面用於將識別結果更好的適配到系統其他模組。典型的統計語音識別可以用下面的公式表述:
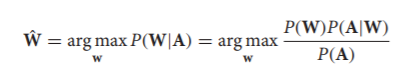
對於給定的語音特徵向量序列X=X1X2…Xn,語音識別的目標是找到對應的單詞序列W=w1w2…wm,同時保證後驗概率P(W|X)為最大。由於上面等式在X範圍內計算,上面等式可以改寫為:
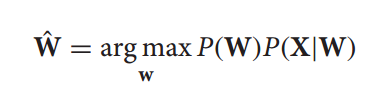
公式中的P(W)和P(X|W)通過語言模型和聲學模型分別計算得到。
實踐中最大的挑戰是如何建立精確的聲學模型P(X|W)和語言模型P(W)。對於大型詞彙語音識別系統,我們需要將裡面的單詞劃分成更小的音節序列(稱為發音建模),由於詞彙量很大,P(X|W)近似於音節模型。P(X|W)需要考慮喇叭差異、發音變化、環境
聲源定位技術在人工智慧領域應用廣泛,利用麥克風陣列來形成空間笛卡爾座標系,根據不同的線性陣列、平面陣列和空間陣列,來確定聲源在空間中的位置。智慧裝置首先可以對聲源的位置做進一步的語音增強,當智慧裝置獲取你的位置資訊可以結合其他的感測器進行進一步的智慧體驗,比如機器人會聽到你的呼喚走到你的身邊,視訊裝置會聚焦鎖定說話人等等。瞭解聲源定位技術之前,我們需要了解近場模型和遠場模型。
麥克風陣列聲場模型

聲源定位技術之TDOA
TDOA
TDOA是先後估計聲源到達不同麥克風的時延差,通過時延來計算距離差,再利用距離差和麥克風陣列的空間幾何位置來確定聲源的位置。分為TDOA估計和TDOA定位兩步:
(1)TDOA估計
常用的有廣義互相關GCC,Generalized Cross Correlation和LMS自適應濾波

廣義互相關
基於TDOA的聲源定位方法中,主要用GCC來進行延時估計。GCC計算方法簡單,延時小,跟蹤能力好,適用於實時的應用中,在中等嘈雜強度和低混響噪聲情況下效能較好,在嘈雜非穩態噪聲環境下定位精度會下降。

LMS自適應濾波
在收斂的狀態下給出TDOA的估值,不需要噪聲和訊號的先驗資訊,但是對混響較為敏感。該方法將兩個麥克風訊號作為目標訊號和輸入訊號,用輸入訊號去逼近目標訊號,通過調整濾波器係數得到TDOA。
(2)TDOA定位
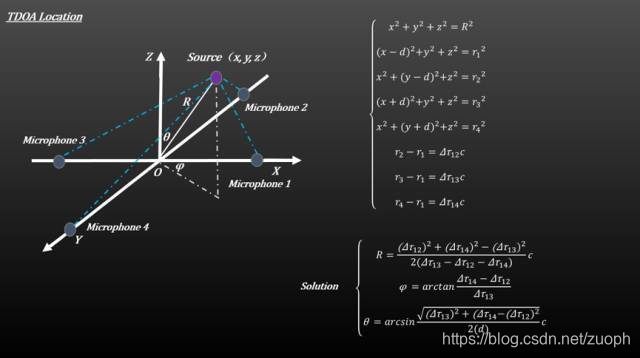
TDOA估值進行聲源定位,三顆麥克風陣列可以確定空間聲源位置,增加麥克風會增高資料精度。定位的方法有MLE最大似然估計、最小方差、球形差值和線性相交等。TDOA相對來講應用廣泛,定位精度高,且計算量最小,實時性好,可用於實時跟蹤,在目前大部分的智慧定位產品中均採用TDOA技術做為定位技術。
聲源定位技術之波束形成
波束形成可分為常規的波束形成CBF(Conventional Beam Forming)和自適應波束形成ABF(Adaptive Beam Forming)。CBF是最簡單的非自適應波束形成,對各個麥克風的輸出進行加權求和得到波束,在CBF中,各個通道的權值是固定的,作用是抑制陣列方向圖的旁瓣電平,以濾除旁瓣區域的干擾和噪聲。ABF在CBF的基礎之上,對干擾和噪聲進行空域自適應濾波。ABF中,採用不同的濾波器得到不同的演算法,即不同通道的幅度加權值是根據某種最優準則進行調整和優化。如LMS,LS,最大SNR,LCMV(線性約束最小方差,linearly constrained Minimum Variance)。採用LCMV準則得到的是MVDR波束形成器(最小方差無畸變響應,Minimum Variance Distortionless Response)。LCMV的準則是在保證方向圖主瓣增益保持不變的情況下,使陣列的輸出功率最小,表明陣列輸出的干擾加噪聲功率最小,也可以理解為是最大SINR準則,從而能最大可能的接收訊號和抑制噪聲和干擾。
CBF-傳統的波束形成

延時求和的波束形成方法用於語音增強,對麥克風的接收訊號進行延時,補償聲源到每個麥克風的時間差,使得各路輸出訊號在某一個方向同相,使得該方向的入射訊號得到最大的增益,使得主波束內有最大輸出功率的方向。形成了空域濾波,使得陣列具有方向選擇性。
CBF + Adaptive Filter 增強型波束形成

結合Weiner濾波來改善語音增強的效果,帶噪語音經過Weiner濾波得到基於LMS準則的純淨語音訊號。而濾波器係數可以不斷更新迭代,與傳統的CBF相比,可以更有效的去除非穩態噪聲。
ABF-自適應波束形成

GSLC是一種基於ANC主動噪聲對消的方法,帶噪訊號同時通過主通道和輔助通道,而輔助通道的阻塞矩陣將語音訊號濾除,得到僅包含多通道噪聲的參考訊號、各通道根據噪聲訊號得到一個最優訊號估計,得到純淨語音訊號估計。
未完待續…