
CS231n-KNN實現(附坑)
從效果看來,KNN並不適合影象識別,它的識別更多基於背景,而不是圖片的語義主體。所以在實際應用中我們一般不適用KNN識別影象,但是在學習過程中,通過KNN演算法我們可以學習到影象識別的整個流程,還是有些許幫助的
- 影象識別流程
無論是哪種分類演算法,影象識別的流程主要為以下流程
輸入影象:一般來說,輸入的是影象的畫素值
訓練模型:通過輸入的影象來訓練模型
評價模型:用測試資料來測試模型的分類能力從而評估模型的泛化能力
在訓練模型階段,由於很多模型都會有或多或少的引數需要設定(這些引數我們稱為“超參”),所以我們需要增加一些步驟來確定這些引數,比如驗證集或者交叉驗證等方法,這些在接下來都會提到
- 視覺化Cifar10資料集
在下載完 cifar10資料集 後,我們首先需要讀取cifar10資料集中的資料,這個我就不多介紹了,網上應該也有很多,注意Python版本就可以了,這裡使用Python3.7。然後我們隨機抽取一部分影象進行視覺化
def VisualizeImage(X_train, y_train): """視覺化資料集 :param X_train: 訓練集 :param y_train: 訓練標籤 :return: """ plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray' classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] num_classes = len(classes) samples_per_class = 8 for y, cls in enumerate(classes): # 得到該標籤訓練樣本下標索引 idxs = np.flatnonzero(y_train == y) # 從某一分類的下標中隨機選擇8個影象(replace設為False確保不會選擇到同一個影象) idxs = np.random.choice(idxs, samples_per_class, replace=False) # 將每個分類的8個影象顯示出來 for i, idx in enumerate(idxs): plt_idx = i * num_classes + y + 1 # 建立子影象 plt.subplot(samples_per_class, num_classes, plt_idx) plt.imshow(X_train[idx].astype('uint8')) plt.axis('off') # 增加標題 if i == 0: plt.title(cls) plt.show()
視覺化的效果如下:

- 構建KNN模型
一般構造機器學習模型,我們需要定義訓練以及測試函式,而KNN模型是無需訓練的,所以我們主要步驟在於預測功能,它的思路很簡單:
如果一個樣本在特徵空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。
那麼什麼叫做最相鄰呢?即兩個畫素點越接近越相鄰,這裡我們用L2-正規化(歐氏距離)來比較畫素的接近程度,然後逐個畫素比較,最後將差異值全部加起來得到兩幅影象接近程度。
- 計算歐式距離
它的公式如下:
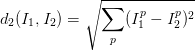
有很多方式可以實現這個公式,比如我們可以採取每一個測試集和每一個訓練集分別計算歐氏距離的方式(即巢狀for迴圈),也可以用向量化的方式實現(numpy科學計算庫,涉及到矩陣計算)。而事實上逐一計算方式所需的時間大概師向量化的實現的幾百倍,所以我們要儘量使用向量化實現。向量化實現的思路是:
因為一張圖片我們一般會將它reshape到一個一維向量,所以對於兩張圖片的距離就是計算兩個向量之間的歐氏距離。我們將歐氏距離公式展開,我們可以得到兩個向量之間的距離為x^2 - 2xy + y^2 (X, Y分別代表一個向量,也就是一張圖片), 這樣我們就可以用矩陣的方式求解了。
可檢視KNN中的距離矩陣vectorize的實現方法
def compute_distances(self, X_test):
"""計算測試集和每個訓練集的歐氏距離
向量化實現需轉化公式後實現(單個迴圈不需要)
:param X_test: 測試集 numpy.ndarray
:return: 測試集與訓練集的歐氏距離陣列 numpy.ndarray
"""
dists = np.zeros((X_test.shape[0], self.X_train.shape[0]))
value_2xy = np.multiply(X_test.dot(self.X_train.T), -2)
value_x2 = np.sum(np.square(X_test), axis=1, keepdims=True)
value_y2 = np.sum(np.square(self.X_train), axis=1)
dists = value_2xy + value_x2 + value_y2
return dists
這裡注意一下,因為python的廣播無法將(5000 x 500)的陣列和(500,)的向量相加,所以我們有兩種選擇,一種是將向量先轉成矩陣轉置後相加,最後再轉回陣列,另一種就是設定關鍵字引數keepdims=True,它可以保證python的廣播機制正確執行
- 預測分類
原理也很簡單:
根據上述計算的歐氏距離,對於每一個需要預測的樣本,我們取前K個最接近的訓練資料的分類,然後將這些分類中個數最多的分類作為預測結果.
python實現如下:
def predict_label(self, dists, k):
"""選擇前K個距離最近的標籤,從這些標籤中選擇個數最多的作為預測分類
:param dists: 歐氏距離
:param k: 前K個分類
:return: 預測分類(向量)
"""
y_pred = np.zeros(dists.shape[0])
for i in range(dists.shape[0]):
# 取前K個標籤
closest_y = self.y_train[np.argsort(dists[i, :])[:k]]
# 取K個標籤中個數最多的標籤
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_pred
- 交叉驗證
在我們訓練完整資料集之前,我們必須先確定超參的值,這裡我是用交叉驗證方法,該方法主要思路為將訓練集分為n份,然後每份分別作為測試集,剩下的作為訓練集來檢驗不同的超參的效果,它適用於資料集較少的情況,因為交叉驗證訓練次數比較多,所以n的值不宜取過大,我們一般取5-10就可以了;如果資料集夠大,我們可以使用驗證集的方式,即從訓練集取一小部分作為驗證集來檢驗不同超參的效果,這樣我們所需的訓練次數就會少很多了。程式碼如下
def Cross_validation(X_train, y_train):
"""交叉驗證,確定超參K,同時視覺化K值
:param X_train: 訓練集
:param y_train: 訓練標籤
"""
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
k_accuracy = {}
# 將資料集分為5份
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
# 計算每種K值
for k in k_choices:
k_accuracy[k] = []
# 每個K值分別計算每份資料集作為測試集時的正確率
for index in range(num_folds):
# 構建資料集
X_te = X_train_folds[index]
y_te = y_train_folds[index]
X_tr = np.reshape(X_train_folds[:index] + X_train_folds[index + 1:], (X_train.shape[0] * (num_folds - 1) / num_folds, -1))
y_tr = np.reshape(y_train_folds[:index] + y_train_folds[index + 1:], (X_train.shape[0] * (num_folds - 1) / num_folds))
# 預測結果
classify = KNearestNeighbor()
classify.train(X_tr, y_tr)
y_te_pred = classify.predict(X_te, k=k)
accuracy = np.sum(y_te_pred == y_te) / float(X_te.shape[0])
k_accuracy[k].append(accuracy)
for k, accuracylist in k_accuracy.items():
for accuracy in accuracylist:
print("k = %d, accuracy = %.3f" % (k, accuracy))
- 訓練評估完整資料模型
當我們確定了超參以後,我們就可以將完整的資料進行訓練了,由於KNN在資料集比較大的時候(圖片的資料維度很大)計算量特別大,所以我將5000個數據作為完整訓練集,500個數據作為測試集(50000個訓練集和10000個訓練集在我的電腦不能正常執行,記憶體崩潰)。在上述資料中我得到的結果是正確率為28.2%,雖然識別率比較低,但這應該是個比較正常的結果,我們在使用KNN識別圖片之前就應該明白它的識別率不會很高
- 附程式碼用到的numpy函式介紹
matplotlib.pyplot.subplot(XXX):
- 遇到的坑
首先是load資料集的時候 注意python3是沒有pickle模組的 要import _pickle
然後load後有人會報資料集位元組的問題,這個要加入
![]()
最坑的是轉換資料的時候一定要看好np的shape到底是多少
我今天down別人的程式碼 沒有將圖片壓成一維向量結果在knn程式碼中老是報index溢位的問題,一定要注意呀。
- 影象KNN分類核心筆記知乎
影象分類器