異常值判斷處理
1、簡單統計量分析
2、3σ準則
data <- rnorm(20) plot(data,type = "l",lwd=1.5,ylim = c(-4,4),xlim = c(0,23), xlab=NA,ylab=NA,main = "質量控制圖") lines(rep(mean(data),20),lwd=1.8) text(21,mean(data),"均值線") lines(rep(mean(data)-3*sd(data),20),lty=2,col="red",lwd=1.8) text(21,mean(data)-3*sd(data),labels = "控制下限",col = "red") lines(rep(mean(data)+3*sd(data),20),lty=2,col="blue",lwd=1.8) text(21,mean(data)+3*sd(data),labels = "控制上限",col = "blue")

data1 <- read.csv("每日付費及留存資料.csv",header = TRUE)
library(qcc)
attach(data1)
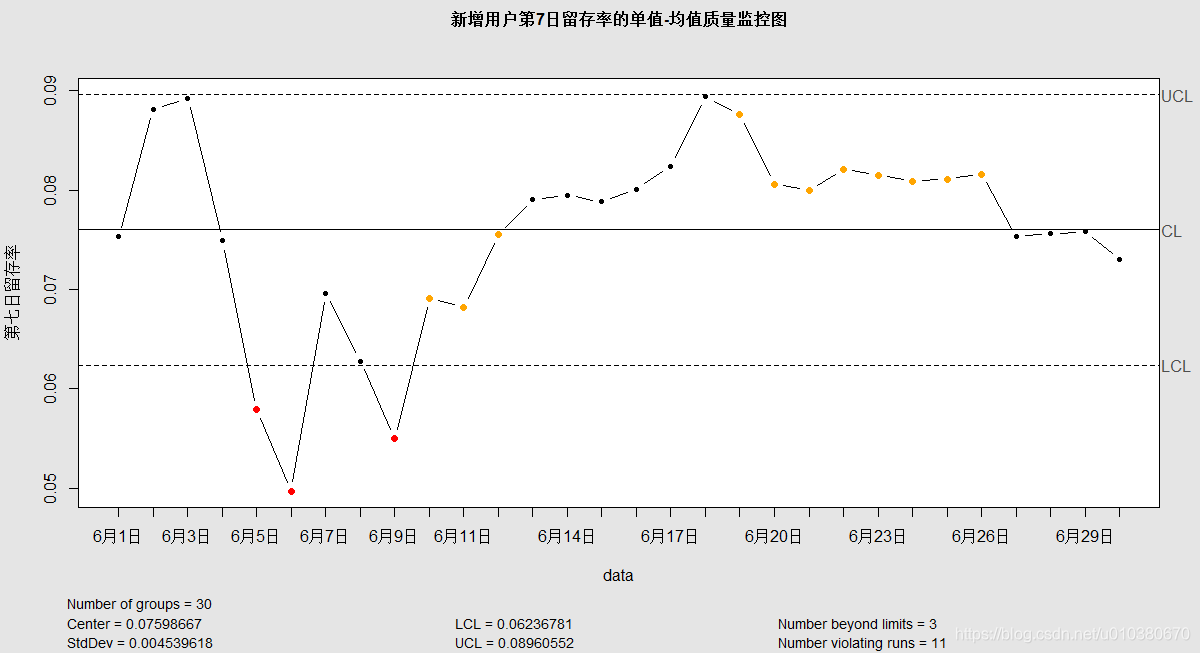
qcc(七日留存率,type="xbar.one",labels=日期,title="新增使用者第7日留存率的單值-均值質量監控圖",
xlab="data",ylab="第七日留存率")
qcc(data, type, sizes, center, std.dev, limits,
data.name, labels, newdata, newsizes, newdata.name,
newlabels, nsigmas = 3, confidence.level,
rules = shewhart.rules, plot = TRUE, …)
type:
Statistic charted Chart description
“xbar” mean means of a continuous process variable 均值控制圖
“R” range ranges of a continuous process variable 均值-極差控制圖
“S” standard deviation standard deviations of a continuous variable 均值-標準差控制圖
“xbar.one” mean one-at-time data of a continuous process variable 單值-均值控制圖
“p” proportion proportion of nonconforming units 可變樣本量的轉化率
“np” count number of nonconforming units 固定樣本量的轉化率
“c” count nonconformities per unit 固定樣本量的不合格數
“u” count average nonconformities per unit 可變樣本量的不合格數
“g” count number of non-events between events 事件間的非事件數
nsigmas = 3 指定用於計算控制限制的σ的數量
3、箱線圖分析
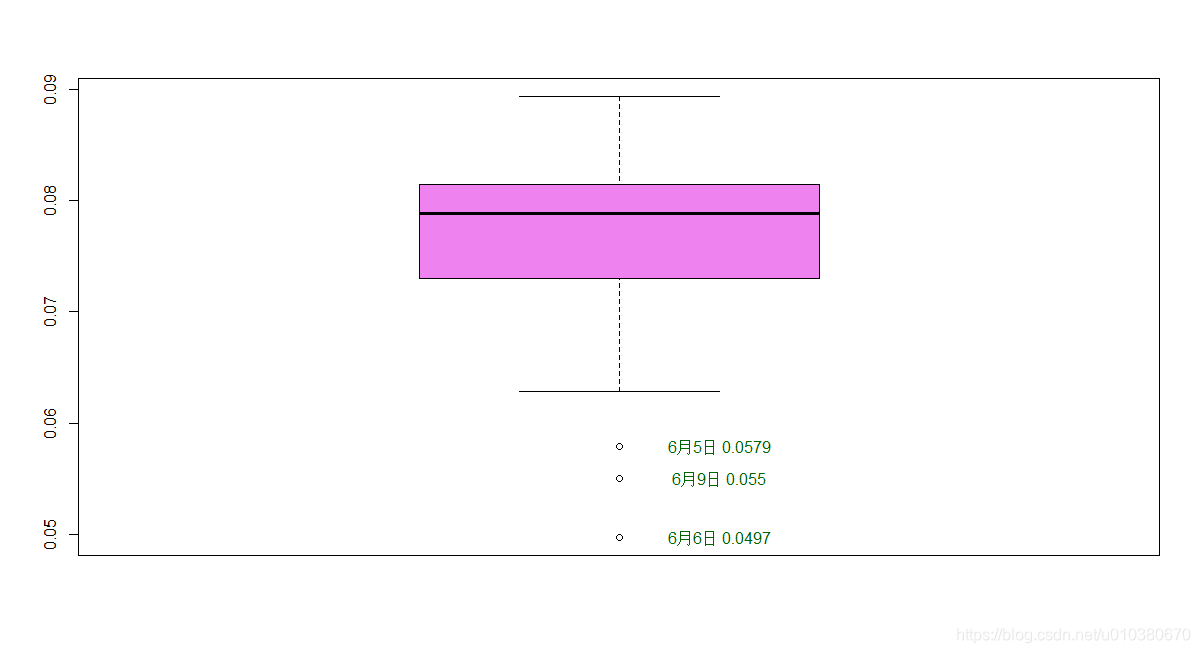
boxplot.stats(七日留存率)
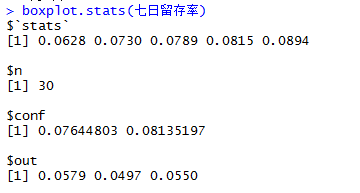
idx <- which(七日留存率 %in% boxplot.stats(七日留存率)$out) boxplot(七日留存率,col="violet") text(1.1,boxplot.stats(七日留存率)$out,labels=paste(data1[idx,"日期"], data1[idx,"七日留存率"]), col="darkgreen")
4、聚類分析
利用多個數值變數
data2<-read.csv("玩家玩牌資料樣本.csv")
#歸一化處理
data3 <- round(apply(data2[,-1], 2,function(x) (x-min(x))/(max(x)-min(x))),4)
data3 <- data.frame(data3)
row.names(data3) <- data2$使用者id
分群
result <- kmeans(data3,3)
centers <- result$centers[result$cluster,]
distances <- sqrt(rowSums((data3-centers)^2))
找出距離最大的
outliers <- order(distances,decreasing = TRUE)[1:5]
print(outliers)
rownames(data3[outliers,])
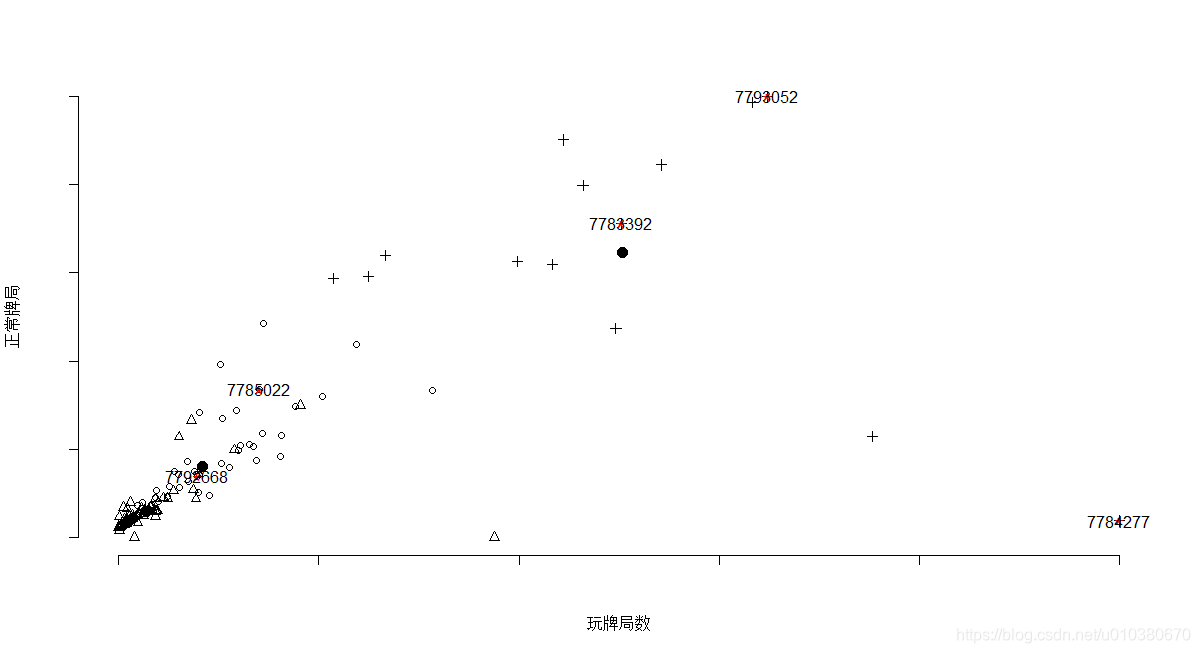
plot(data3$玩牌局數,data3$正常牌局,pch=result$cluster,axes=FALSE,
xlab="玩牌局數",ylab="正常牌局")
axis(1,labels = F)
axis(2,labels = F)
points(result$centers[,c("玩牌局數","正常牌局")],pch=16,cex=1.5)
points(data3[outliers,c("玩牌局數","正常牌局")],pch="*",col="red",cex=1.5)
text(data3[outliers,c("玩牌局數","正常牌局")],labels=rownames(data3[outliers,]))