
mybatis查詢快取之一級快取
什麼是查詢快取?
快取是介於應用程式和物理資料來源之間
mybatis提供查詢快取,用於減輕資料壓力,提高資料庫效能。
mybaits提供一級快取,和二級快取。

一級快取是sqlSession級別的快取。在操作資料庫時需要構造sqlSession物件,在物件中有一個數據結構(HashMap),用於儲存快取資料。不同的sqlSession之間的快取 區域(HashMap)是互不影響的。
二級快取是mapper級別的快取,多個sqlSession去操作同一個Mapper的sql語句,多個SqlSession可以公用二級快取,二級快取是跨sqlSession的
為什麼要用快取?
如果快取中有資料就不用從資料庫中獲取,減少了和資料之間的互動次數,大大提高系統的效能
為什麼會兩種快取方式?
二級快取與一級快取區別,二級快取的範圍更大,多個sqlSession可以共享一個UserMapper的二級快取區域。
-
一級快取
-
一級快取工作原理
命中條件
快取存在一個hash表中,通過查詢SQL,查詢資料庫,客戶端協議等作為key.在判斷是否命中前,MySQL不會解析SQL,而是直接使用SQL去查詢快取,SQL任何字元上的不同,如空格,註釋,都會導致快取不命中.
如果查詢中有不確定資料,例如CURRENT_DATE()和NOW()函式,那麼查詢完畢後則不會被快取.所以,包含不確定資料的查詢是肯定不會找到可用快取的
-
1. 伺服器接收SQL,以SQL和一些其他條件為key查詢快取表(額外效能消耗)
2. 如果找到了快取,則直接返回快取(效能提升)
3. 如果沒有找到快取,則執行SQL查詢,包括原來的SQL解析,優化等.
4. 執行完SQL查詢結果以後,將SQL查詢結果存入快取表(額外效能消耗)
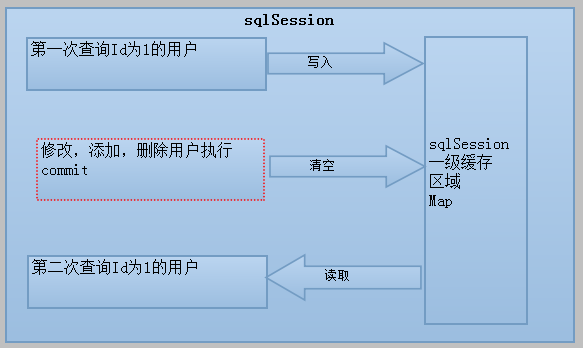
為什麼sqlSession去執行commit操作(執行插入、更新、刪除),清空SqlSession中的一級快取,目的為了讓快取中儲存的是最新的資訊,
避免髒讀。(所謂的髒資料)
-
-
一級快取測試
-
mybatis預設支援一級快取,不需要在配置檔案去配置。
測試程式碼
1 // 一級快取測試 2 @Test 3 public void testCache1() throws Exception { 4 SqlSession sqlSession = sqlSessionFactory.openSession();// 建立代理物件 5 UserMapper userMapper = sqlSession.getMapper(UserMapper.class); 6 7 // 下邊查詢使用一個SqlSession 8 // 第一次發起請求,查詢id為1的使用者 9 User user1 = userMapper.getUserById(1); 10 System.out.println(user1); 11 12 // 如果sqlSession去執行commit操作(執行插入、更新、刪除),清空SqlSession中的一級快取,這樣做的目的為了讓快取中儲存的是最新的資訊,避免髒讀。 13 14 // 更新user1的資訊 15 // user1.setUsername("我是測試使用者"); 16 // userMapper.updateUser(user1); 17 // //執行commit操作去清空快取 18 // sqlSession.commit(); 19 20 // 第二次發起請求,查詢id為1的使用者 21 User user2 = userMapper.getUserById(1); 22 System.out.println(user2); 23 24 sqlSession.close(); 25 26 }
假設我們不執行更新操作,輸出:
1 DEBUG [main] - Opening JDBC Connection 2 DEBUG [main] - Created connection 110771485. 3 DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] 4 DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id=? 5 DEBUG [main] - ==> Parameters: 1(Integer) 6 DEBUG [main] - <== Total: 1 7 User [id=1, username=張三, sex=男] 8 User [id=1, username=張三, sex=男] 9 DEBUG [main] - Resetting autocommit to true on JDBC Connection [[email protected]] 10 DEBUG [main] - Closing JDBC Connection [[email protected]] 11 DEBUG [main] - Returned connection 110771485 to pool.
使用上面更新的程式碼,輸出:
1 DEBUG [main] - Opening JDBC Connection 2 DEBUG [main] - Created connection 110771485. 3 DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] 4 DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id=? 5 DEBUG [main] - ==> Parameters: 1(Integer) 6 DEBUG [main] - <== Total: 1 7 User [id=1, username=張三, sex=男] 8 DEBUG [main] - ==> Preparing: update user set username=?,sex=? where id=? 9 DEBUG [main] - ==> Parameters: 我是測試使用者(String), null, 1(Integer) 10 DEBUG [main] - <== Updates: 1 11 DEBUG [main] - Committing JDBC Connection [[email protected]] 12 DEBUG [main] - ==> Preparing: SELECT * FROM user WHERE id=? 13 DEBUG [main] - ==> Parameters: 1(Integer) 14 DEBUG [main] - <== Total: 1 15 User [id=1, username= 我是測試使用者, sex=男] 16 DEBUG [main] - Resetting autocommit to true on JDBC Connection [[email protected]] 17 DEBUG [main] - Closing JDBC Connection [[email protected]d] 18 DEBUG [main] - Returned connection 110771485 to pool.
原來使用者名稱為張三則更新為我是測試使用者
-
-
一級快取應用
-
正式開發,假如專案是將mybatis和spring進行整合開發....,事務控制在service中。
一個service方法中包括 很多mapper方法呼叫。
1 service{ 2 3 //開始執行時,開啟事務,建立SqlSession物件 4 5 //第一次呼叫mapper的方法getUserById(1) 6 7 //第二次呼叫mapper的方法getUserById(1),從一級快取中取資料 8 9 //方法結束,sqlSession關閉 10 11 }
如果是執行兩次service呼叫查詢相同 的使用者資訊,不走一級快取,因為session方法結束,sqlSession就關閉,一級快取就清空。
-
-
快取資料失效時機
-
在表的結構或資料發生改變時,查詢快取中的資料不再有效。有這些INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、
DROP TABLE或DROP DATABASE會導致快取資料失效。所以查詢快取適合有大量相同查詢的應用,不適合有大量資料更新的應用。
-
- 可以使用下面三個SQL來清理查詢快取:
-
二級快取
- 二級快取的工作原理
第一步:首先開啟mybatis的二級快取。
第二步:sqlSession1去查詢使用者id為1的使用者資訊,查詢到使用者資訊會將查詢資料儲存到二級快取中。
第三步:如果SqlSession3去執行相同 mapper下sql,執行commit提交,清空該 mapper下的二級快取區域的資料。
第四步:sqlSession2去查詢使用者id為1的使用者資訊,去快取中找是否存在資料,如果存在直接從快取中取出資料。
UserMapper有一個二級快取區域(按namespace分) ,其它mapper也有自己的二級快取區域(按namespace分)。
每一個namespace的mapper都有一個二快取區域,兩個mapper的namespace如果相同,這兩個mapper執行sql查詢
到資料將存在相同的二級快取區域中。
- 開啟二級快取
mybaits的二級快取是mapper範圍級別,除了在SqlMapConfig.xml設定二級快取的總開關,還要在具體的mapper.xml中開啟二級快取。
第一步:在核心配置檔案mybatis-config.xml中加入以下程式碼
1 <!-- 全域性引數的配置 --> 2 <settings> 3 <!-- 開啟二級快取 --> 4 <setting name="cacheEnabled" value="true"/> 5 </settings>
cacheEnabled:對在此配置檔案下的所有cache 進行全域性性開/關設定。預設true
第二步:實體類User實現序列化介面
1 public class User implements Serializable{ 2 ...... 3 4 }
目的:為了將快取資料取出執行反序列化操作,因為二級快取資料儲存介質多種多樣,不一樣在記憶體。
第三步:使用Junit進行測試:
1 // 二級快取測試 2 @Test 3 public void testCache2() throws Exception { 4 SqlSession sqlSession1 = sqlSessionFactory.openSession(); 5 SqlSession sqlSession2 = sqlSessionFactory.openSession(); 6 SqlSession sqlSession3 = sqlSessionFactory.openSession(); 7 8 // 建立代理物件 9 UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class); 10 // 第一次發起請求,查詢id為1的使用者 11 User user1 = userMapper1.getUserById(1); 12 System.out.println(user1); 13 14 //這裡執行關閉操作,將sqlsession中的資料寫到二級快取區域 15 sqlSession1.close(); 16 17 18 //使用sqlSession3執行commit()操作 19 UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class); 20 User user = userMapper3.getUserById(1); 21 user.setUsername("張明明");
userMapper3.updateUser(user); 22 //執行提交,清空UserMapper下邊的二級快取 23 sqlSession3.commit(); 24 sqlSession3.close(); 25 26 UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); 27 // 第二次發起請求,查詢id為1的使用者 28 User user2 = userMapper2.getUserById(1); 29 System.out.println(user2); 30 31 sqlSession2.close(); 32 33 }
- 禁用二級快取
在statement中設定useCache=false可以禁用當前select語句的二級快取,即每次查詢都會發出sql去查詢,
預設情況是true,即該sql使用二級快取。
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
- 重新整理快取
在mapper的同一個namespace中,如果有其它insert、update、delete操作資料後需要重新整理快取,如果不執行重新整理快取會出現髒讀。
設定statement配置中的flushCache="true" 屬性,預設情況下為true即重新整理快取,如果改成false則不會重新整理。使用快取時如果手動
修改資料庫表中的查詢資料會出現髒讀。
如下:
<insert id="insertUser" parameterType="com.mybaits.entity.User" flushCache="true">
- 二級快取應用場景
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,
提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間
隔 flushInterval ,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
- 二級快取的侷限性
mybatis二級快取對細粒度的資料級別的快取實現不好,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,
但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取
資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料
全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取
vue是什麼?
vue是一個當前很火的js框架。它可以將我們的資料,和顯示資料的DOM文件進行繫結。一旦繫結以後,DOM和資料將會自動同步。使我們不用在考慮給DOM的某個元素去進行賦值,而是將注意力放在資料模型上。