
流式計算形態下的大資料分析
1 介 紹
1.1 流式計算介紹
流式大資料計算主要有以下特徵:
1)實時性。流式大資料不僅是實時產生的,也是要求實時給出反饋結果。系統要有快速響應能力,在短時間內體現出資料的價值,超過有效時間後資料的價值就會迅速降低。
2)突發性。資料的流入速率和順序並不確定,甚至會有較大的差異。這要求系統要有較高的吞吐量,能快速處理大資料流量。
3)易失性。由於資料量的巨大和其價值隨時間推移的降低,大部分資料並不會持久儲存下來,而是在到達後就立刻被使用並丟棄。系統對這些資料有且僅有一次計算機會。
4)無限性。資料會持續不斷產生並流入系統。在實際的應用場景中,暫停服務來更新大資料分析系統是不可行的,系統要能夠持久、穩定地執行下去,並隨時進行自我更新,以便適應分析需求。
1.2 應用場景介紹
網際網路領域就是很好的流式大資料應用場景。該領域在日常運營中會產生大量資料,包括系統自動生成的使用者、行為、日誌等資訊,也包括使用者所實時分享的各類資料。網際網路行業的資料量不僅巨大,其中半結構化和非結構化所呈現的資料也更多。由於網際網路行業對系統響應時間的高要求,這些資料往往需要實時的分析和計算,以便及時為使用者提供更理想的服務。
流式計算在網際網路大資料中的典型應用場景如下:
1)社交網站。在社交網站中,要對使用者資訊進行實時分析,一方面將使用者所釋出的資訊推送出去,另一方面也要為使用者及時發現和推薦其感興趣的內容,及時發現和防止欺詐行為,增進使用者使用體驗。
2)搜尋引擎。搜素引擎除了向用戶反饋搜尋結果以外,還要考慮和計算使用者的搜尋歷史,發掘使用者感興趣的內容和偏好,為使用者推送推廣資訊。
3)電子商務。電子商務側重於大資料技術中的使用者偏好分析和關聯分析,以便有針對性地向用戶推薦商品。同時,隨著大量電子商務開始內嵌網際網路消費金融服務,對使用者的風險分析和預警也是非常重要的。
可以預見,隨著技術的不斷髮展、網際網路與物聯網等領域的不斷深入連線,未來要分析的資料量必然還會爆炸性增長。傳統的批量計算方式並不適合這類對響應時間要求很高的場景,能持續執行、快速響應的流式計算方法,才能解決這一方面的需求。
1.3 隨機森林方法介紹
隨機森林是目前海量資料處理中應用最廣的分類器之一,在響應速度、資料處理能力上都有出色表現[10, 13]
每個元分類器h∈H,都等價於從輸入空間X到輸出類集Y的對映函式。對輸入空間X中的每一條輸入xi,h都可以得到h(xi)=yi,yi為分類器h給出的決策結果。
定義決策函式D,則分類器集合H對輸入xi所得到的最終結果y就可以定義如下:
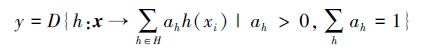
在隨機森林中,單棵樹的生長過程如下:
1)針對原始訓練集,使用Bagging方法在原始樣本集S中進行有放回的隨機資料選取,形成有區別的訓練集Tset。
2)採用抽樣的方式選取特徵。假設資料集一共有N個特徵,選擇其中M個特徵,M≤N。每個抽取出來的訓練集,使用隨機選取的M個特徵來進行節點分裂。
3)所有生成的決策樹自由生長,不進行剪枝。每一棵決策樹的輸出結果之間可採用簡單的多數投票法(針對分類問題)或者結果平均法(針對迴歸問題)組合成最終的輸出結果。
隨機森林方法是組合分類器演算法的一種,是決策樹的組合。它擁有Bagging和隨機特徵選擇這2種方法的優點。在大資料環境下,隨機森林方法還有以下優點:
① 隨機森林方法可以處理大資料量,能夠應對突發性資料;
② 隨機森林方法生成較為簡單的決策樹,易於解讀;
③ 隨機森林方法適用於分散式和並行環境,擴充套件性好,適用於對分散式架構有很高要求的流式大資料處理環境;
4)決策樹分類器非常簡單,能以極高效率對新資料進行處理,適用於流式大資料環境下對響應速度要求高的特點;
在流式大資料環境下,隨機森林方法也存在一些問題,其中最核心的問題,就是流式大資料環境中資料具有實時性和易失性的特點,經典隨機森林方法難以適應。以訓練集資料為基礎所生成的決策樹會過期,對新資料進行分類的準確度下降。
2 流式大資料環境下的演算法改進2.1 方法改進思路
以往對隨機森林方法的改進主要集中在幾個方面:
將隨機森林與Hadoop、MapReduce等計算框架結合,實現分散式隨機森林方法,提高演算法的處理效率。
對資料進行預處理,降低資料集的不平衡性,以此提升演算法在非平衡性資料集上的準確度和分類效能。
針對標準隨機森林方法採用C4.5作為節點分裂演算法的情況,用效率更高的節點分裂演算法如CHI2來替換C4.5,可以提高演算法處理大資料集的能力。
基於分類器相似性度量和分類間隔概念,對冗餘的分類器進行修剪,以取得更好的分類效果與更小的森林規模。
這幾種改進方法可以有效地在特定環境下提高隨機森林演算法的表現,但都不能完全滿足流式大資料環境對演算法的要求。鑑於流式大資料演算法需求所表現出來的鮮明特徵,從流式大資料的特徵出發,對經典的隨機森林方法進行改造,思路如下:
1)使用隨機森林方法實時處理資料,由於隨機森林是一種比較簡單的分類器,對資料的響應時間可以得到保障,能夠滿足實時性要求。
2)僅對一段時間內的資料進行儲存,在記憶體可用的條件下處理少量資料,這樣就可以解決流式大資料的易失性和無限性特點。
3)由於資料的無序性,經典隨機森林所產生的分類器無法滿足所有的輸入資料,必須令分類器能夠隨著新資料的輸入不斷更新,保持對資料的敏感性和準確度。因為資料的易失性,所以分類器的更新就必須基於演算法所臨時儲存的有限訓練資料進行。
4)分類器更新方法必須是可伸縮的、高效的,不能影響到分類器對資料的正常處理。
2.2 改進後的隨機森林方法
首先定義隨機森林中決策樹h的準確度(accurate)Ah:
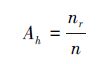
式中,nr是決策樹h給出正確結果的次數,n是決策樹h所處理過的所有資料數量。準確度給出了在一定時間內某棵樹給出正確結果的比例。
在迴歸問題中,決策樹h給出的分類結果如與最終結果一致,則認為該決策樹得出了正確結果。計算決策樹h給出結果xi與最終結果之間的差值,並取其標準差作為h的準確度:
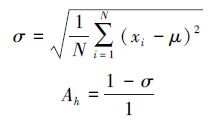
準確度衡量一棵樹在一段時間內判定結果的準確程度。演算法在執行過程中跟蹤每棵樹的準確度,並定期對隨機森林進行更新,淘汰其中準確度最低的樹:
1)按照標準的隨機森林方法構造決策樹群H。
2)為每一棵決策樹h,h∈H建立1張記錄表Th,記錄隨機森林在處理資料過程中生成的結果。
3)一段時間後,對所有決策樹的結果記錄表進行掃描,刪除其中準確度最低的樹。
通過準確度進行篩選後,森林中樹的數量會越來越少,實現決策樹集的剪枝。但數量的過分減少,也會造成整個決策樹集在準確度上的降低[11]。
為了保持一定數量的決策樹,在剪枝的同時,也要對資料集進行跟蹤,生成新的決策樹來保持整個森林的質量。為了從資料集中篩選出對生成新的決策樹更有用的樣本,引入間隔(margin)定義如下: 間隔指隨機森林在1條給定樣本資料(x,y)上的整體決策正確度,定義為:
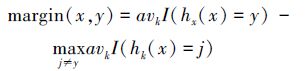
式中,avk( )是一個求均值函式,I( )是一個度量函式。如果在隨機森林中大部分決策樹對樣本(x,y)得到正確結果,則margin(x,y)大於零。如果margin(x,y)小於零或某一閾值,則說明該樣本被大部分決策樹識別失誤,演算法對該樣本得出了錯誤結論。
margin(x,y)大於零的樣本,說明決策樹集可以得到正確結果。與已有的決策樹相似度高的樹並不會提高整個森林的準確度,此類樣本不需要再次處理。為了讓新生成的決策樹能夠提高整個森林的準確度,記錄margin(x,y)小於等於零的樣本,形成新的訓練資料集S′。資料集S′的特點,是隻佔當前資料集S中的一小部分,但其資料特徵與其他資料不同。
在資料集S′上使用隨機森林方法,獲得一個新的決策樹集合{h′(x,θk),k=1,…}。資料集S′只代表了全部資料集中的一部分資料,在S′中篩選一定比例的決策樹,加入原來的決策樹集合中。
根據S′與S之間的比例確定要篩選出的決策樹數量:
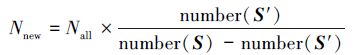
篩選方法可以有以下幾種:
S′篩選法:利用S′進行檢驗,並按照準確度對所有決策樹排序,選擇其中準確度最高的Nnew棵決策樹。
S篩選法:利用全部資料集S進行檢驗,並按準確度對所有決策樹排序,選擇準確度最高的Nnew棵樹。
Margin篩選法:計算每棵樹在資料集S′上的margin均值與margin方差之比[18],作為每一棵決策樹的重要性衡量指標,選擇最重要的Nnew棵樹。
改進後的隨機森林方法流程如圖 1所示。

|
| 圖 1 改進後隨機森林方法流程圖 |
| 圖選項 |
① 使用初始訓練資料集S生成最初的隨機森林H;
② 使用隨機森林H對當前待處理的資料集Si進行分類:
a) 用隨機森林中的每一棵樹hj對Si中的每一條資料xj進行分類;
b) 記錄每一棵樹和每一條資料的分類結果,同時計算該條資料分類結果的間隔值margin(xj,y);
c) 如果margin(xj,y)小於給定閾值,則將xj加入新訓練資料集S′。
③ Si分類完畢後,計算每棵樹的準確度,並進行剪枝;
④ 在新訓練資料集S′上執行隨機森林方法,生成新的隨機森林H′;
⑤ 對新的隨機森林進行剪枝,將剪枝後的H′與H合併,形成新的隨機森林H;
⑥ 清空訓練資料集S′,開始處理下一批資料。
2.3 新隨機森林方法的優點
新的隨機森林方法有著以下優點:
1)新方法每次所處理的資料集是有限的,在實際應用中,可以根據記憶體大小設計每次處理的資料集大小,保證資料的實時計算和計算效率;
2)新方法中,需要儲存的只有結果記錄表和新訓練資料集,相比原始資料流小了很多,滿足流式大資料的易失性特點,在大資料量下的伸縮性更好;
3)對新資料的處理只需要使用隨機森林進行驗證和投票,執行效率高,能夠實時反饋資料的處理結果;
4)該系統可以持續地更新執行下去,並能夠不斷使用資料的新特性來更新自身,滿足流式大資料環境的無序性和無限性特點。