
認識ElasticSearch的API,並深入Search的使用
0.引言
本文羅列介紹了ES提供的公共API,重點圍繞資料檢索主題相關API進行說明總結。
1.概述
Elasticsearch提供全功能的RESTful API。以基於HTTP協議傳輸交換JSON資料的方式,向用戶提供訪問服務。
具體的訪問方式可按照引數的提交方法區分為以下兩種:
- 通過URI引數提交,比如:
curl 'localhost:9200/bank/_search?q=*&pretty
- 通過請求報文體提交,比如:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d ' { "query": { "match_all": {} } }'
雖說以上說明中的兩個例子效果一致,但是具體來說,報文體提交的方式具備更高的可讀性,並且具備更豐富的表示能力,有一些功能是必須使用該方式才可以被訪問。URI引數方式的優勢在於便於快速測試。
有很重要的一點必須要理解的是:一旦請求結果返回,那麼Elasticsearch就完全結束了關於該次請求的處理,不會維護任何跟查詢結果相關的類似於“遊標”概念的伺服器端資源,查詢結果中當然也不會出現該類資源的引用。這種方式跟其他諸如SQL平臺的處理方法截然不同。通常在SQL平臺中使用者會得到查詢結果集中靠前的部分子集,之後如果再有需要,使用者可以通過能夠維護訪問狀態的“遊標”機制繼續向伺服器獲取查詢結果集中的剩餘部分。
關於ES提供的資料存取服務,可以按照訪問物件型別、操作型別的種類,將所有的API作以梳理劃分。那麼這些劃分,在API技術層面則有可能分別對應著不同種類的URL訪問點、HTTP方法、網路請求引數等等。
2.基本分類
就ES API大方面的功能語義而言,可以分為以下幾類:
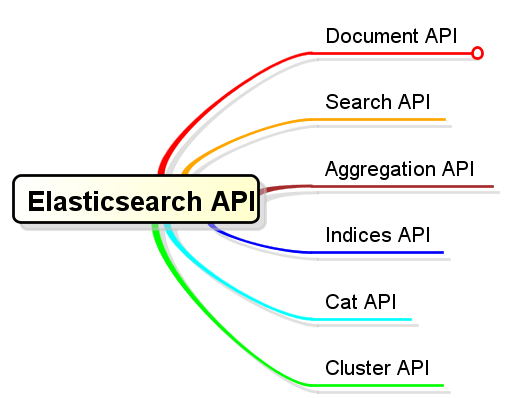
- Document API:文件的增、刪、改、查(按文件ID)
- Search API:文件搜尋
- Aggregation API:聚合計算
- Indices API:索引操作,建立、檢視、刪除、開啟、關閉等等
- Cat API:可以獲得壓縮與對齊結果的API(遵循傳統的終端命令結果形式,非JSON響應格式)
- Cluster API:叢集管理操作
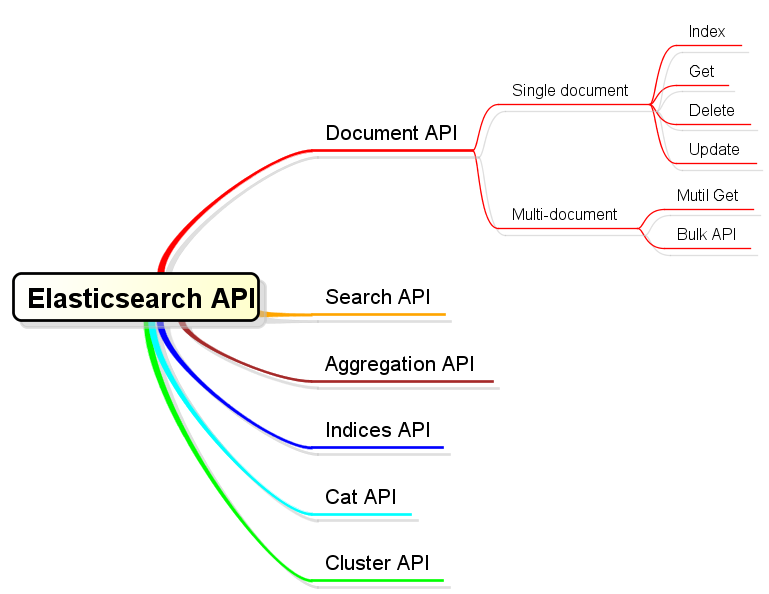
3.Document API
Document API中主要以HTTP中PUT、DELETE、POST、GET這四種方法,來對應到文件的增、刪、改、查四種操作,而服務訪問點就以<server>/{<index-name>}/{<type-name>}為模式;HTTP方法與URL結合使用,以達到文件操作目的。
而且ES還提供了關於該主題的批量操作API,分別是批量查詢和批量新增。批量查詢為GET <server>/{<index-name>}/{<type-name>}/_mget;批量新增為POST <server>/{<index-name>}/{<type-name>}/_bulk。
4.Search API
4.1 Search概述
使用Search API可以執行查詢,得到匹配查詢的檢索結果。關於查詢本身,就像前文概述中所說,可以通過URL引數或者請求報文體兩種方式來提交。所有的Search API都可以跨多個索引,以及在一個索引內跨多種Type。關於這一點,體現在API的訪問點URL上,就是以下情況:
GET <server>/{<index-name-list>}/{<type-name-list>}/_search
舉例如下:
檢索範圍為twitter索引中所有type:
$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'
檢索範圍為twitter索引中,tweet和user這兩種type:
$ curl -XGET 'http://localhost:9200/twitter/tweet,user/_search?q=user:kimchy'
檢索範圍為kimchy與elasticsearch兩個索引中tweet這種type:
$ curl -XGET 'http://localhost:9200/kimchy,elasticsearch/tweet/_search?q=tag:wow'
檢索範圍為所有available的索引中tweet這種type:
$ curl -XGET 'http://localhost:9200/_all/tweet/_search?q=tag:wow'
檢索範圍為所有索引中的所有type:
$ curl -XGET 'http://localhost:9200/_search?q=tag:wow'
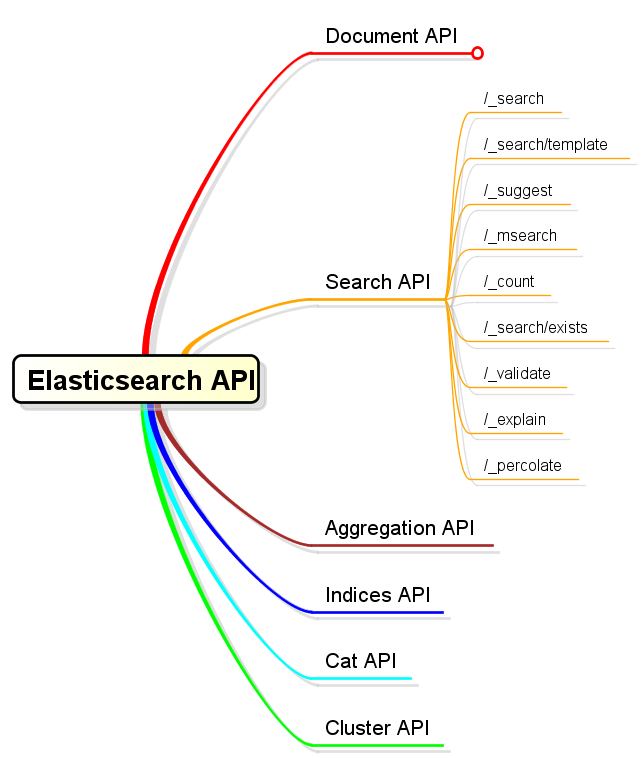
4.2 Search API類別細分
Search本身涵蓋了較大的概念範圍,比如“搜尋匹配檢索條件的文件集合”、“獲得匹配檢索條件的文件數量”、“檢查是否存在符合檢索條件的文件”,等等,這些都屬於搜尋的範疇。這些不同的API語義差別,對應了不同的API訪問點。以下對Search API做了類別細分:
4.2.1 /_search
該訪問點是資料搜尋中最常用的API。接下來將按照報文體提交搜尋的方式來詳細說明。
$ curl -XGET 'http://localhost:9200/twitter/tweet/_search' -d '{
"query" : {
"term" : { "user" : "kimchy" }
}
}
'
可以看到,報文體中提交了一個欄位名為query用以表示查詢條件的欄位資訊。該欄位也是整個檢索查詢中最重要的提交資訊,但是檢索查詢中還可以提交更多的查詢相關引數。
| 引數名稱 | 描述 |
|---|---|
| timeout | 限定執行過期時長。預設不設此值,不設立超時限制。 |
| from | 返回文件結果起始位置。預設為0。 |
| size | 返回文件結果集大小。預設為10。 |
| search_type | dfs_query_then_fetch or query_then_fetch . Defaults to query_then_fetch. See Search Type for more. |
| request_cache | true 或者 false。當檢索操作不返回文件集本身的情況下,設定是否快取。See Shard request。 |
| terminate_after | 限定從每個shard中收集的最大文件數量。預設不設此最大數量限制。如果設定了該值,那麼響應結果中將會包含一個terminated_early的欄位,以表示該次查詢實際上是較早地終止了。 |
| sort | 通過設定一個(或一組)排序欄位來控制結果集中的文件順序。 |
| _source | 控制、過濾結果中的_source欄位。預設情況下,文件搜尋操作返回的內容中包括文件中的_source欄位,除非使用_source引數或者fields引數進行控制。See Source filtering。 |
| fields | fields引數描述的是關於在型別對映定義中被明確指定儲存的欄位。指定被儲存的欄位中,哪些是需要被載入返回的。See fields。 |
| script_fields | 允許使用指令碼定義新的欄位。 |
| fielddata_fields | Allows to return the field data representation of a field for each hit。 |
| post_filter | 應用在檢索結果集處理的最末尾處。其目的在於做聚合統計時針對更多範圍內資料,但是返回的檢索查詢結果集中只需要其中一部分即可。那麼,post_filter就是用於最後過濾出想要的那一小部分。 |
| highlight | Allows to highlight search results on one or more fields。See Highlighting。 |
| rescore | 設定重新計算相關度得分的機制。該機制使得可以針對排名較前的特定範圍內的檢索結果(在query和post_filter之後),進行重新排序。(並非針對所有的檢索結果都重新計算分數) |
| scroll | 使用該引數,可以使得使用者可以像使用傳統資料庫遊標一樣來獲取較大的查詢結果集,而不再限於一次性的“單頁”結果。 |
| preference | 可以使用該引數控制檢索請求執行在哪個分片上。預設情況下是隨機的。 |
| explain | true 或者 false,控制是否解釋檢索結果中每個文件的得分是如何計算出來的。 |
| version | true 或者 false, 控制是否返回每個檢索結果項的版本號碼。 |
| indices_boost | 使用該引數可以針對各個索引來配置不同的評分基數。這種設定對於明確知曉某索引中的資料相對比較重要的情況是很有用的。 |
| min_score | 設定得分最低閾值,用於排除掉結果集中低於該分數的文件。 |
關於引數傳遞
以上引數中,除了search_type和request_cache是必須通過URL引數來傳遞,其它的都建議置於請求報文體中。不過請求報文體的內容本身,也可以通過一個名為source的URL引數來傳遞。
HTTP GET 和 POST 都可以被用來發送請求。(主要是因為並不是所有的http client都能夠允許GET方法傳送報文體,所以POST方法是被允許的。)
關於/search的響應內容
關於/search的響應內容,除了包含匹配搜尋條件的文件之外,還包含了跟檢索結果相關的檢索效能資訊反饋。舉例如下:
{
"took" : 2, #A
"timed_out" : false, #A
"_shards" : {
"total" : 2, #B
"successful" : 2, #B
"failed" : 0 #B
},
"hits" : {
"total" : 2, #C
"max_score" : 0.9066504, #C
"hits" : [ { #D
"_index" : "get-together", #D
"_type" : "group", #D
"_id" : "3", #D
"_score" : 0.9066504, #D
"fields" : { #D
"location" : "San Francisco, California, USA", #D
"name" : "Elasticsearch San Francisco" #D
} #D
} ] #D
}
}
- A: How long your request took and if it timed out
- B: How many shards were queried
- C: Statistics on all documents that matched
- D: The results array
A.Time
響應結果中最先展示的資訊就是關於該次請求的耗時資訊:
"took" : 2,
"timed_out" : false,
took欄位顯示了ES花費了多少時間來處理該次請求(毫秒單位)。time_out欄位顯示該次請求處理是否超時。預設情況下是不會出現超時的,除非在查詢提交時設定了timeout引數。如若出現超時情形,那麼返回的檢索結果僅僅是超時前能夠收集到的部分結果。
B.Shards
響應結果中其次展示的資訊就是關於該次請求涉及到的分片資訊:
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
}
展示了總共有多少個分片被分派了該次請求,其中成功和失敗各有多少次。
C.Hits statistics
響應結果中最後展示的就是關於檢索查詢的命中文件資訊了。hits元素有可能會比較相當長,因為它包含了一個所有匹配文件的陣列。不過,在文件陣列之前它還包括了一組統計資訊:
"total" : 2,
"max_score" : 0.90178301
total數值不一定會和返回結果中的陣列長度一致,一般情形下都會遠大於實際返回的陣列長度。預設情況下,ES限制了實際返回結果長度為10。而total則表示了索引中匹配檢索的文件總數目。可以通過提交查詢時的size引數來控制實際返回結果大小。
D.Resulting documentss
檢索結果文件集,會以陣列形式出現在hits欄位上。
"hits" : [ {
"_index" : "get-together",
"_type" : "group",
"_id" : "3",
"_score" : 0.9066504,
"fields" : {
"location" : "San Francisco, California, USA",
"name" : "Elasticsearch San Francisco"
}
} ]
每個匹配的文件都會顯示其歸屬的索引和型別,以及文件ID和得分。如果在提交查詢時定義了 “欄位”列表(fields屬性),那麼文件內容將展示相關欄位資訊。如果在提交查詢時沒有設定關於fields的設定,那麼將會顯示_source內容。
關於searchType
執行一次分散式檢索可以通過許多種不同的執行路徑。分散式檢索操作,需要將檢索請求分發到所有相關的分片上,然後在收集所有的檢索結果。當做這種“分發/收集”操作時,可以有多種方式,尤其是對於搜尋引擎而言。這個過程中可能會涉及以下問題:
問題1:執行分散式搜尋時,需要在每個分片上獲取多大的結果集呢?
舉個例子,如果當前有10個分片,我們需要從中檢索出10個滿足檢索條件的文件,那麼就需要從所有的分片中各檢索10個文件,然後將他們排序,確保最終返回正確的結果。
問題2:每個分片只能侷限於自身所儲存的資訊來執行檢索操作,它不能夠考慮到其它索引中儲存的類似於詞頻等搜尋引擎資訊。
舉個例子,如果我們需要獲取準確的排序結果,那麼將需要首先從所有的分片中收集詞頻資訊並進行全域性的計算,然後再在各個分片上以全域性的詞頻資訊來執行檢索操作。
ES允許使用者可以通過請求引數來控制檢索請求的執行方式,通過search_type進行設定即可。
query_then_fetch
該型別設定為系統預設設定。在該設定下,檢索請求將分為兩階段進行。
1.第一階段:查詢請求被轉發給所有被涉及的分片,每個分片在本地執行檢索併產生有序結果。然後,每個分片僅返回足夠分發節點合併、重排各分片結果的資訊,使得分發節點初步得到一個全域性排序的結果集,但是該結果集中並不包括命中文件本身。
2.第二階段:分發節點從相關分片中獲取結果集文件內容。
dfs_query_then_fetch
與query_tehn_fetch基本相同,區別在於第一階段中,各分片中執行檢索時依據的評分資訊被換做了全域性的term資訊,以期能夠得到更精確的評分結果。
count
首先:Deprecated in 2.0.0-beta1. Because count does not provide any benefits over query_then_fetch with a size of 0.
其次:通常來講,直接使用 /count API 會更好一點,因為那樣會有更多的設定選項可供使用。
scan
首先:Deprecated in 2.1.0. Because scan does not provide any benefits over a regular scroll request sorted by _doc.
scan型別檢索的初衷是為了通過關閉排序功能,進而允許可以以較高的效率來滾動讀取較大的結果集。但是,從版本2.1.0開始,更推薦直接使用/scroll API。
關於_source與fields以及script fields
ES本身提供了若干預定義欄位,用於完成一些關鍵且必要的功能。這些欄位一般都具備有以下特徵:
- 名稱以下劃線"_"開頭
- 使用者不需要直接去宣告其定義,也不需要直接為其賦值
- 這些欄位往往起到一些關鍵性作用
_source就是其中之一。該欄位的目的是為了儲存文件的原始文字內容的。有了它,才會使得檢索後的結果不僅僅只是一個文件ID,而且可以直接看到匹配檢索的文件內容。
在建立type的時候可以特意指定關閉_source欄位內容,但是該功能預設是開啟的。在檢索時,返回結果預設也是會帶回_source內容的,該行為可以通過在提交檢索請求時設定_source引數為false來關閉。
另外,在檢索文件時,不僅僅可以簡單地控制返回結果中是否包括_source內容,而且可以更精細地控制需要具體哪些欄位。方法為在檢索查詢引數中使用_source引數過濾或者fields引數,只是二者有所區別。
使用_source過濾的方法如下:
{
"_source": "obj.*",
"query" : {
"term" : { "user" : "kimchy" }
}
}
使用該引數時,查詢結果中將不再返回_source中的所有內容,而是有選擇性地返回指定欄位。
使用fields屬性也可以起到過濾返回欄位的效果。但是它與_source屬性的機制不太一樣。fields屬性原本是針對被特殊指定須儲存的欄位內容,只是預設情況下,欄位是不會被儲存的。關於欄位是否須被儲存,其設定方式是在建立type定義時,與指定欄位型別一樣。
不過,當前情況下,ES考慮到向後相容性,就算是fields指定的欄位並沒有被儲存,那麼使用fields的實現方式就自動變成了“先載入_source,然後再解析欄位內容”。
上段中提到了兩種儲存:_source與個別獨立欄位。這二者沒有太大聯絡,可以同時都儲存,也可以同時都不儲存,當然也可以只儲存其中一種。二者的應用方面差別在於,如果存在經常需要訪問某一個特定欄位的情形,那麼單獨儲存該欄位將會比從_source表示的整個文件內容中解析的效率高。當然,儲存將會引發空間代價,不過ES會對_source和其它任何獨立欄位的內容進行壓縮。
最後再說到script_fields,使用該提交引數可以運用指令碼能力來生成新的臨時欄位。基本過程就是使用指令碼表示式,來基於原有的文件資訊來生成新欄位,比如下面的例子:
{
"query" : {
...
},
"script_fields" : {
"test1" : {
"script" : "doc['my_field_name'].value * 2"
},
"test2" : {
"script" : {
"inline": "doc['my_field_name'].value * factor",
"params" : {
"factor" : 2.0
}
}
}
}
}
該項功能的使用具體細節可多參照指令碼使用方面的參考。
關於欄位_all
就像_source欄位儲存了所有資訊一樣,_all欄位索引了所有資訊。當在_all欄位上進行檢索時,只要有任意欄位能夠匹配,那麼ES都會返回相關結果。這種操作在使用者不清楚具體目標欄位時比較有用。以下檢索就是在_all上進行的:
curl 'localhost:9200/get-together/group/_search?q=elasticsearch'
假如對檢索功能沒有檢索任意欄位的需求,那麼在建立type時可以像關閉_source一樣來關閉_all。這樣會減小索引體積,並且加快索引速度。
另外,還可以針對欄位級別來設定當前欄位是否包含在_all中,預設都是包含的除非指定欄位屬性include_in_all為false。
關於排序
在提交檢索查詢時,可以通過設定sort引數來控制返回指定排序結果。sort定義是基於一個或多個欄位的,指定這些欄位的升降序和排序優先順序。所以sort本身將會是一個複合物件,舉個例子如下:
{
"sort" : [
{ "post_date" : {"order" : "asc"}},
"user",
{ "name" : "desc" },
{ "age" : "desc" },
"_score"
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
除了_score欄位的預設順序是desc之外,其餘的任何欄位預設順序都是asc。排序欄位除了可以是文件欄位,還有兩個特殊的內建欄位可以被指定為排序欄位:
1._score:文件相關度評分。 2._doc:文件被索引的順序。該順序幾乎沒有實際需求場景,只是其優勢在於排序效率最高。所以,一般在不關心結果順序時應當使用_doc排序。尤其是在使用scroll操作時。
排序記憶體耗用
在排序時,相關的排序欄位值都會被載入記憶體。這意味著每個分片都需要足夠的記憶體來能夠容下這些資料。所以,對於字串型別的排序欄位應當避免被分析;數值型別欄位應當儘量設定為較短長度(比如short integer float 而不是 long double)。
其它關於排序的內容,還有諸如:
- 如何使用多值欄位來排序
- 如何處理缺失欄位的情況
- 如何根據地理位置距離來排序
- 如何使用排序指令碼
等等,可檢視更多參考說明。
關於分頁
from + size
前文已經提到ES並不像傳統的資料庫那樣能夠提供“遊標”來分步、連續獲得查詢結果集。所以,關於ES查詢分頁的問題,最簡陋的做法就是直接使用查詢請求中的from和size引數來進行控制。
from:定義了獲取結果中首元素的偏移量。size:定義了獲取結果的最大文件數量。
比如下例請求,得到第0-9個,共10個結果:
{
"from" : 0, "size" : 10,
"query" : {
"term" : { "user" : "kimchy" }
}
}
接下來可以通過第二次請求來獲取第10-19個元素,為第二頁結果:
{
"from" : 10, "size" : 10,
"query" : {
"term" : { "user" : "kimchy" }
}
}
不過需要注意的是,from+size是不允許超出ES配置項index.max_result_window的。該配置項預設值為10000。其背後的含義也就是,該方法其實是每次都從頭獲取、截斷返回的做法。一來效率不過,二來無法進行更深的分頁。
scroll
關於分頁,更專業的做法是使用scroll相關的API。
scroll為ES的查詢模式開設一個特例,它打破了通常ES查詢的“一錘子”模式,提供了類似於資料遊標機制。使得使用者有機會能夠獲取一次查詢相關的大批量結果資料甚至是全量結果資料。
相對於面向終端使用者的實時查詢,scroll更適用於大批量資料處理。比如,索引的遷移:將舊索引中的資料遷出到一個配置變更後的新索引中。
scroll API的具體使用方式舉例說明如下:
在提交查詢請求時,使用scroll引數來(1)指定本次請求是需要建立scroll search上下文的;(2)指定該scroll search上下文的存活過期時長為多久。
curl -XGET 'localhost:9200/twitter/tweet/_search?scroll=1m' -d '
{
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
'
以上請求返回的查詢結果相對於普通查詢特殊的一點是結果中會包括一個_scroll_id欄位。那麼接著獲取下一批資料結果時,直接使用該欄位即可:
curl -XGET 'localhost:9200/_search/scroll' -d'
{
"scroll" : "1m",
"scroll_id" : "c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1"
}
'
對於後續的請求傳送,URL中不必再包括index與type名稱以及其他檢索相關的資訊,這些都在初始檢索查詢時已經確定。不過繼續使用scroll引數來更新對應上下文的存活過期時長。該請求的關鍵在於scroll_id引數。每次執行scroll查詢都會獲得下一批資料結果直到沒有剩餘結果(hit陣列為空)。
老的ES版本中,傳送scroll_id的方法為直接將id值寫在報文體中:
curl -XGET 'localhost:9200/_search/scroll?scroll=1m' -d 'c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1'
在使用scrollAPI時,有以下需要注意的幾點:
- ES官方文件中提示,每次
scroll請求都會返回關聯的_scroll_id,並且還提示每次返回的_scroll_id可能會有所更新,對於使用者而言應該使用最近一次返回的_scroll_id。不過,筆者實驗的ES版本並沒有在後續請求過程中更新_scroll_id,而是一直沿用首次請求建立的_scroll_id值。Whatever,追蹤最新的_scroll_id應該是沒錯的,無論該值是否會被更新。 - 如果檢索請求中定義了聚合計算,那麼只有初次請求的返回結果中會包含聚合結果。
- 對於
scroll檢索,設定排序方式為按_doc欄位,會對請求的執行起到優化效果。比如:
curl -XGET 'localhost:9200/_search?scroll=1m' -d '
{
"sort": [
"_doc"
]
}
'
scroll檢索上下文的存活時間
在進行scroll請求時,無論是初次請求還是後續請求,都需要使用scroll引數來指定ES儲存檢索上下文的過期時長。比如設定scroll=1m。(時間單位說明)該過期時長的意義是針對請求者處理而言的,指的是請求者在這麼長時間範圍內會處理完該批資料,然後再發起下一批的資料請求。如果超時,那麼ES將放棄儲存該次請求的上下文以免不必要的資源耗用。
這背後的影響在於,ES會週期性地將小的索引合併為大的索引進而優化檢索效率,合併完成後將會刪除掉舊的小索引。scroll 檢索上下文將會避免ES刪除掉正在使用中的小索引(使用完畢後再刪除)。換個角度來看,scroll請求返回的資料反映的是其搜尋請求被建立時的資料狀態,就好比是當時的資料快照。那麼後續如果有文件資料變動,只會影響到下一次的請求,對已經在執行的scroll檢索無影響。
檢查當前“scroll 檢索上下文的存活情況”可以使用以下方法:
curl -XGET localhost:9200/_nodes/stats/indices/search?pretty
關於scroll的銷燬清理
就像之前所說的那樣,srcoll檢索上下文將會在超時後被自動清理。保持scroll檢索上下文具有一定的代價,所以做到儘快清理是十分必要的,比如明確scroll檢索已經執行完畢的時候應該立即主動關閉其檢索上下文。關閉方法如下,使用clear-scrollAPI即可:
curl -XDELETE localhost:9200/_search/scroll -d '
{
"scroll_id" : ["c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1"]
}'
一次性關閉多組:
curl -XDELETE localhost:9200/_search/scroll -d '
{
"scroll_id" : ["c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1", "aGVuRmV0Y2g7NTsxOnkxaDZ"]
}'
一次性關閉所有:
curl -XDELETE localhost:9200/_search/scroll/_all
關於命名查詢
在進行檢索查詢時,每個filter和query都可以接收一個_name引數設定。如下:
{
"size": 5,
"query": {
"bool": {
"must": {
"terms": {
"_name": "test",
"direct": [
"process_send"
]
}
}
}
}
}
返回的結果文件中將會包含matched_queries資訊:
{
"_index" : "main",
"_type" : "pix0",
"_id" : "AVNA6II_Kawvxx13OgK4",
"_score" : 3.4127,
"matched_queries" : [ "test" ]
}
4.2.2 /_search/template
/_search/template訪問點是對/_search的模板化擴充套件,它在原功能基礎上引入了模板化機制,使得一些具有固定檢索條件結構的應用場景可以使用模板來達到容易維護的目的。
具體方式採用mustach語言來進行模板定義。舉例如下:
GET /_search/template
{
"inline" : {
"query": { "match" : { "{{my_field}}" : "{{my_value}}" } },
"size" : "{{my_size}}"
},
"params" : {
"my_field" : "foo",
"my_value" : "bar",
"my_size" : 5
}
}
更多關於mustache,請參照online documentation of the mustache project。
模板本身可以在系統中進行預定義,比如以*.mustache檔案的方式置於系統的config/scripts目錄中;或者儲存在ES中的一個命名為.scripts的特殊索引中。在使用這些內建模板的時候,只需要使用檔名(指令碼檔案)或者模板名稱(索引儲存)來引用即可。比如下例所示:
GET /_search/template
{
"file": "storedTemplate",
"params": {
"query_string": "search for these words"
}
}
還需要說明的是,為了方便模板的除錯,ES提供/_render/template訪問點用於模板校驗。如下例:
GET /_render/template
{
"inline": {
"query": {
"terms": {
"status": [
"{{#status}}",
"{{.}}",
"{{/status}}"
]
}
}
},
"params": {
"status": [ "pending", "published" ]
}
}
返回模板渲染後的結果:
{
"template_output": {
"query": {
"terms": {
"status": [
"pending",
"published"
]
}
}
}
}
這種校驗測試方式同樣適用於預定義的模板,比如下例所示:
GET /_render/template
{
"file": "my_template",
"params": {
"status": [ "pending", "published" ]
}
}
4.2.3 /_suggest
對於搜尋引擎使用者而言,當其使用搜索功能開始鍵入檢索關鍵字時,搜尋引擎往往會依據使用者輸入來及時的不斷地提示相似的、相關的搜尋內容,進而幫助使用者更好地選定更精確的檢索關鍵詞。那麼訪問點/_suggest就是提供該方面功能的,比如下例:
curl -XPOST 'localhost:9200/_suggest' -d '{
"my-suggestion" : {
"text" : "the amsterdma meetpu",
"term" : {
"field" : "body"
}
}
}'
該功能本身也是基於檢索來完成的,所以除了直接訪問/_suggest之外呢還可以通過訪問/_search來完成,只是需要帶上相關請求引數即可:
curl -s -XPOST 'localhost:9200/_search' -d '{
"query" : {
...
},
"suggest" : {
...
}
}'
suggest特性本身還在部分完善中,更多參考請見Suggesters。
4.2.4 /_msearch
ES提供了允許批量執行檢索的API,其訪問點就是/_msearch。發向該訪問點的請求內容有點類似於使用 bulk API的情況,其內容結構如下:
header\n
body\n
header\n
body\n
其中header部分包括:
index資訊type資訊search_type資訊preference資訊routing資訊
body部分包括通常search request中可以包含的內容,比如query aggregations from size 等等。
例如:
$ cat requests
{"index" : "test"}
{"query" : {"match_all" : {}}, "from" : 0, "size" : 10}
{"index" : "test", "search_type" : "dfs_query_then_fetch"}
{"query" : {"match_all" : {}}}
{}
{"query" : {"match_all" : {}}}
{"query" : {"match_all" : {}}}
{"search_type" : "dfs_query_then_fetch"}
{"query" : {"match_all" : {}}}
$ curl -XGET localhost:9200/_msearch --data-binary "@requests"; echo
上例中有兩個header分別是{}和空,這兩種情況是等價的(即遵循預設設定)。對於批量檢索請求,響應結果將會是一個responses陣列,按順序對應提交批量檢索。那如果其中有執行錯誤的結果,將會在responses中原本表示對應檢索結果的位置上出現一個錯誤訊息。
關於/_msearch的使用,也可以像之前介紹使用/_search那樣,通過URL路徑來控制訪問的索引範圍和類型範圍,一旦這樣做等於是為批量請求設定了預設的檢索目標除非檢索請求中在header部分覆寫了有關設定。例如:
$ cat requests
{}
{"query" : {"match_all" : {}}, "from" : 0, "size" : 10}
{}
{"query" : {"match_all" : {}}}
{"index" : "test2"}
{"query" : {"match_all" : {}}}
$ curl -XGET localhost:9200/test/_msearch --data-binary @requests; echo
以上批量請求將會預設執行在索引test中(第一、第二這兩個請求),但是最後一個請求由於進行了特殊設定所以將會執行在索引test2上。
除了檢索範圍,像search_type這樣的控制引數也可以進行寫在URL中進行全域性的預設設定。
4.2.5 /_count
該API服務於使用者只需得到匹配文件數量,而不關心具體文件內容的情況。對於該API的使用基本上等價於使用/_search時設定size引數為0的情形。所以對其的使用也基本與/_search一致,除了URL訪問點地址的不同。
4.2.6 /_search/exists
該API服務於使用者僅需要知曉對於目標查詢是否有任何一個文件被命中的場景。其用法也與/_search基本相同。其響應結果大概如下:
{
"exists" : true
}
只是在ES2.1.0版本之後,已經丟棄了該API。推薦直接使用/_search且設定引數size=0&terminate_after=1。
4.2.7 /_validate
該API使得使用者可以在檢索查詢執行之前,提前校驗請求內容本身是否合法,而不需要真正地執行本次請求。使用方法如下:
curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}'
如果,請求合法,那麼響應結果如下:
curl -XGET 'http://localhost:9200/twitter/_validate/query?q=user:foo'
{"valid":true,"_shards":{"total":1,"successful":1,"failed":0}}
如果,請求非法,那麼響應結果如下:
curl -XGET 'http://localhost:9200/twitter/tweet/_validate/query?q=post_date:foo'
{"valid":false,"_shards":{"total":1,"successful":1,"failed":0}}
在使用/_validate時還可以特別地附帶上explain引數,進而可以得到更詳細的校驗結果:
curl -XGET 'http://localhost:9200/twitter/tweet/_validate/query?q=post_date:foo&pretty=true&explain=true'
{
"valid" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"explanations" : [ {
"index" : "twitter",
"valid" : false,
"error" : "[twitter] QueryParsingException[Failed to parse]; nested: IllegalArgumentException[Invalid format: \"foo\"];; java.lang.IllegalArgumentException: Invalid format: \"foo\""
} ]
}
4.2.8 /_explain
該API可以針對一個指定的文件與一個指定的查詢,得出文件之於查詢的相關性得分。這種功能可以對“某個文件是否匹配某個查詢”的問題給出有用的反饋。
使用該API時,需要給出指定的索引、型別以及文件ID。例如:
curl -XGET 'localhost:9200/twitter/tweet/1/_explain' -d '{
"query" : {
"term" : { "message" : "search" }
}
}'
得出的響應內容大概如下:
{
"matches" : true,
"explanation" : {
"value" : 0.15342641,
"description" : "fieldWeight(message:search in 0), product of:",
"details" : [ {
"value" : 1.0,
"description" : "tf(termFreq(message:search)=1)"
}, {
"value" : 0.30685282,
"description" : "idf(docFreq=1, maxDocs=1)"
}, {
"value" : 0.5,
"description" : "fieldNorm(field=message, doc=0)"
} ]
}
}
4.2.8 /_percolator
percolator詞義本身是濾壺的意思。那這個“濾壺”在這裡指的是什麼呢?
通常來講,我們都是使用“檢索查詢”來搜尋“文件”,這背後的隱含意義其實是二者存在著一個匹配關係。那麼,這種匹配關係是雙向的,也就是說,當一個“檢索查詢”定義匹配一個“文件”時,也可以說是這個“文件”匹配了這個“檢索查詢”。
所以,ES現在提供了一種功能,讓我們可以將“檢索定義”儲存在索引中,然後通過/_percolator就可以提交“文件”來試著找出其匹配的“檢索查詢”了。
那照這個意思來說,事先儲存在索引中的查詢檢索定義就是所謂的“濾壺”了,用來過濾文件。
“查詢檢索定義”和“文件”二者位置可以互換的原因在於,它們都是JSON資料這個統一性基礎。
/_percolatorAPI是一種實時的工作方式,一個percolator query被索引後,就可以馬上應用於percorlator API中。只是有一點需要注意的是,在percorlator query中涉及的欄位引用,必須是已經被相關索引定義過了的。
使用樣例,首先註冊一個percolator query:
curl -XPUT 'localhost:9200/my-index/.percolator/1' -d '{
"query" : {
"match" : {
"message" : "bonsai tree"
}
}
}'
提交一個文件來試圖匹配已經註冊過的percolator query:
curl -XGET 'localhost:9200/my-index/my-type/_percolate' -d '{
"doc" : {
"message" : "A new bonsai tree in the office"
}
}'
以上請求將會得到以下響應內容:
{
"took" : 19,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"total" : 1,
"matches" : [
{
"_index" : "my-index",
"_id" : "1"
}
]
}
前面說了percolator query會被儲存在索引中,那麼它自然也遵循了ES中關於索引儲存的規範和約定。percolator query可以被儲存在任意一個索引中的.percolator型別下。不過通常推薦的做法是,使用一個專用的索引來儲存所有的percolator query。那麼再回到percolate API的使用上來,使用時必須指定三個必須的引數:
- index:包含
.percolator型別的索引(儲存了percolator query的索引) - type:被過濾文件的型別(在index中被定義過,顯示地或者是被動地)
- doc:被過濾文件
curl -XGET 'localhost:9200/twitter/tweet/_percolate' -d '{
"doc" : {
"created_at" : "2010-10-10T00:00:00",
"message" : "some text"
}
}'
percolator的內部機制是這樣的:ES將會把.percolator中的查詢定義解析為Lucene查詢並且維護在記憶體中。當提交percolator文件時,請求中的文件會被解析為Lucene文件並存儲到記憶體中的一個Lucene索引中(一次只能儲存住一個文件),然後所有的percolator查詢都會被作用於這個索引上,最終得出查詢命中結果。
檢視更多Percolator參考。
5.Aggregation API
ES提供了強大的聚合計算功能,這使得使用者在資料檢索查詢的基礎之上能夠聚合分組資料,並再基於分組進行聚合計算。聚合計算是針對一個數據集進行的,這個資料集被稱作聚合計算上下文。那麼最大的聚合計算上下文就是最外層的資料檢索直接得到的資料檢索結果了。
便於對聚合計算的理解,可以對聚合計算操作分為以下三大類別:
- Bucketing
- Metric
- Pipeline
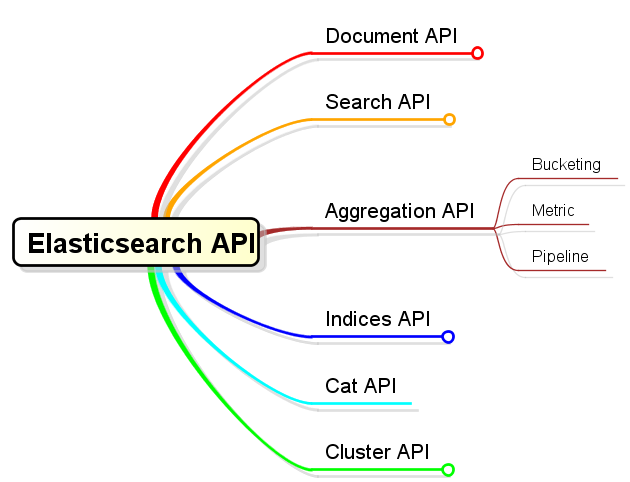
Bukecting的含義就是“分桶”,很形象的說明了它更多地對應了“聚合計算”中的“聚合”。它允許使用者定義一些分類標準,然後當操作被執行時,就會使用這些分類標準來評估上下文中的每個文件,當文件滿足相關標準後,就會落入相關的“桶”中。最終,使用者得到的是一組bucket,每個bucket都擁有一組相關文件集。
Metric的含義就是指標計算,它更多地對應了“聚合計算”中的“計算”。它的作用就在於針對一組文件集來得出指定計算指標。
Pipeline的含義是“管道”,它提供了“基於聚合計算結果”的“聚合計算”連線能力。這個功能目前ES(version 2.2)並未對外正式釋放,尚在實驗性階段。
以上說明介紹了aggregation API的基本分類。不過,關於aggregation最強大之處在於允許多個aggregation之間的巢狀執行。意思是:bucket可以形成新的aggregation上下文,在這個上下文中可以繼續應用aggregation。需要特殊說明的是,只有Bucketing型別的aggregation才可以往下繼續巢狀,因為只有它才能繼續向下提供bucket列表這種細分上下文,Metric型別只能作為子aggregation。(另外,注意“巢狀”的概念,關於這點請區別於pipeline連線)
就像前文介紹的資料檢索/_search的用法一樣,使用aggregation也是向某個API訪問點提交請求報文的套路。具體提交的內容大概長成以下這個樣子:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
可以看到,對於aggregation定義而言這是一個森林結構。使用aggregations關鍵詞來引導一組aggregation定義,每個aggregation定義都有一個邏輯上的名稱。這個邏輯名稱可以用來在響應結果中識別對應的聚合計算結果。在定義aggregation的時候,需要指定aggregation type,作為aggregation定義中第一個key出現,這個是必須的。然後,每種type可能都需要不同的設定引數,這些引數呢就直接設定type為key的object裡即可。如果需要有子聚合,那麼在於type平級的位置直接定義下一層aggregations即可。
以上是關於aggregation的概要說明,其它更多、更詳細的說明本文中不再細表。(另開專題討論)
6.Indices API
Indices API屬於針對索引的管理性質的API,其管理範圍包括各個索引、索引設定、別名、對映、索引模板等等。從分類角度,具體有以下內容:
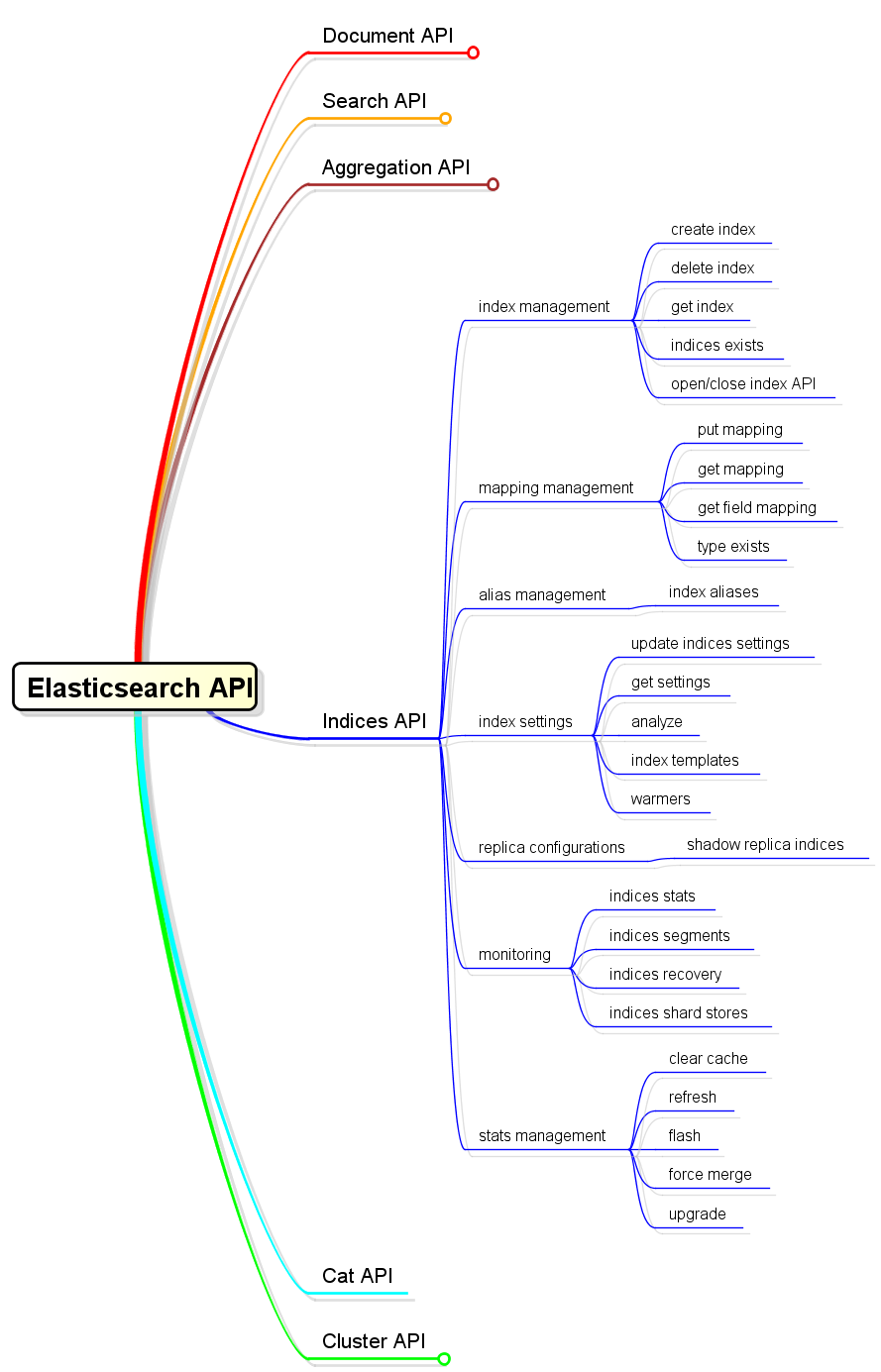
以上是關於索引管理方面API的概要說明,其它更多、更詳細的說明本文中不再細表。(另開專題討論)
7.Cat API
JSON資料是一種非常適合機器解析的資料。但另外一方面,對於人的視覺而言,尤其是ssh終端上展現時,JSON格式資料顯得非常囉嗦、冗餘。這時候其實更需要傳統的表式資料。那麼catAPI就是為了滿足這個需求而存在的。
Cat API的訪問點就是/_cat,直接訪問這個地址將會列出其支援的所有命令:
$ curl http://localhost:9200/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
每個命令都可以接受help引數,進而可以得到該命令頭部資訊的解釋:
$ curl http://localhost:9200/_cat/plugins?help
id | | unique node id
name | n | node name
component | c | component
version | v | component version
type | t | type (j for JVM, s for Site)
url | u | url for site plugins
description | d | plugin details
以master命令為例,顯示出master節點資訊:
$ curl http://localhost:9200/_cat/master
LUVZ_XYGSX-XX1YylIoSOQ DESKTOP-BR0F8C4 10.0.0.4 Tundra
每個命令都可以接受一個v引數,以顯示(加上了表頭的)詳細資訊:
$ curl http://localhost:9200/_cat/master?v
id host ip node
LUVZ_XYGSX-XX1YylIoSOQ DESKTOP-BR0F8C4 10.0.0.4 Tundra
每個命令都可以接受一個h引數,以定製表列:
$ curl http://localhost:9200/_cat/master?h=id,ip
LUVZ_XYGSX-XX1YylIoSOQ 10.0.0.4
更多關於Cat API。
8.Cluster API
Cluster API是一族以/_cluster和/_nodes為訪問點,工作於叢集管理範疇的API。涉及到以下內容:
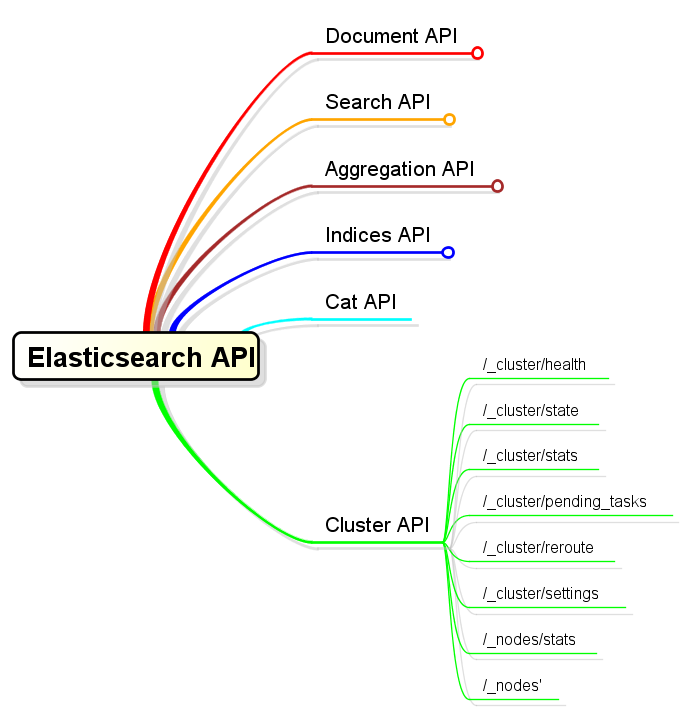
以上是關於索引管理方面API的概要說明,其它更多、更詳細的說明本文中不再細表。(另開專題討論)