
elasticsearch 處理衝突及樂觀併發控制
處理衝突
當我們使用 index API 更新文件 ,可以一次性讀取原始文件,做我們的修改,然後重新索引 整個文件 。 最近的索引請求將獲勝:無論最後哪一個文件被索引,都將被唯一儲存在 Elasticsearch 中。如果其他人同時更改這個文件,他們的更改將丟失。
很多時候這是沒有問題的。也許我們的主資料儲存是一個關係型資料庫,我們只是將資料複製到 Elasticsearch 中並使其可被搜尋。 也許兩個人同時更改相同的文件的機率很小。或者對於我們的業務來說偶爾丟失更改並不是很嚴重的問題。
但有時丟失了一個變更就是 非常嚴重的 。試想我們使用 Elasticsearch 儲存我們網上商城商品庫存的數量, 每次我們賣一個商品的時候,我們在 Elasticsearch 中將庫存數量減少。
有一天,管理層決定做一次促銷。突然地,我們一秒要賣好幾個商品。 假設有兩個 web 程式並行執行,每一個都同時處理所有商品的銷售,如圖 圖 7 “Consequence of no concurrency control” 所示。
圖 7. Consequence of no concurrency control
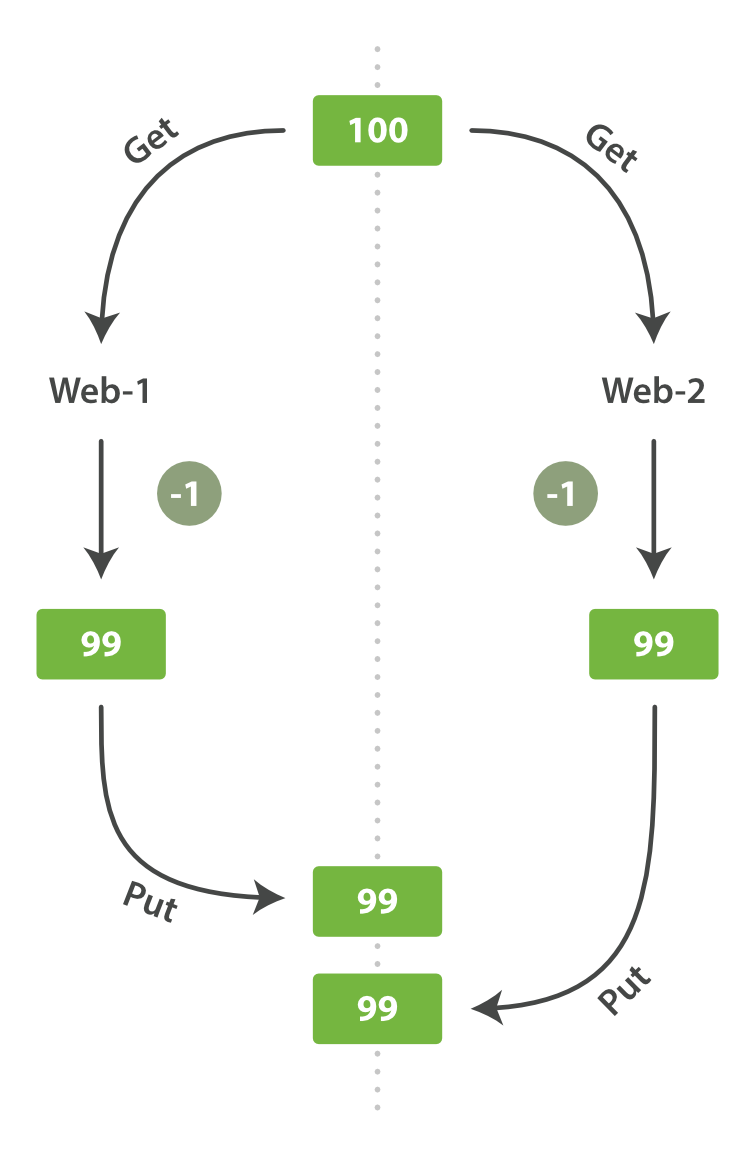
web_1 對 stock_count 所做的更改已經丟失,因為 web_2 不知道它的 stock_count 的拷貝已經過期。 結果我們會認為有超過商品的實際數量的庫存,因為賣給顧客的庫存商品並不存在,我們將讓他們非常失望。
變更越頻繁,讀資料和更新資料的間隙越長,也就越可能丟失變更。
在資料庫領域中,有兩種方法通常被用來確保併發更新時變更不會丟失:
悲觀併發控制
這種方法被關係型資料庫廣泛使用,它假定有變更衝突可能發生,因此阻塞訪問資源以防止衝突。 一個典型的例子是讀取一行資料之前先將其鎖住,確保只有放置鎖的執行緒能夠對這行資料進行修改。
樂觀併發控制
Elasticsearch 中使用的這種方法假定衝突是不可能發生的,並且不會阻塞正在嘗試的操作。 然而,如果源資料在讀寫當中被修改,更新將會失敗。應用程式接下來將決定該如何解決衝突。 例如,可以重試更新、使用新的資料、或者將相關情況報告給使用者。
樂觀併發控制
Elasticsearch 是分散式的。當文件建立、更新或刪除時, 新版本的文件必須複製到叢集中的其他節點。Elasticsearch 也是非同步和併發的,這意味著這些複製請求被並行傳送,並且到達目的地時也許 順序是亂的
當我們之前討論 index , GET 和 delete 請求時,我們指出每個文件都有一個 _version (版本)號,當文件被修改時版本號遞增。 Elasticsearch 使用這個 _version 號來確保變更以正確順序得到執行。如果舊版本的文件在新版本之後到達,它可以被簡單的忽略。
我們可以利用 _version 號來確保 應用中相互衝突的變更不會導致資料丟失。我們通過指定想要修改文件的 version 號來達到這個目的。 如果該版本不是當前版本號,我們的請求將會失敗。
讓我們建立一個新的部落格文章:
PUT /website/blog/1/_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}響應體告訴我們,這個新建立的文件 _version 版本號是 1 。現在假設我們想編輯這個文件:我們載入其資料到 web 表單中, 做一些修改,然後儲存新的版本。
首先我們檢索文件:
GET /website/blog/1響應體包含相同的 _version 版本號 1 :
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
現在,當我們嘗試通過重建文件的索引來儲存修改,我們指定 version 為我們的修改會被應用的版本:
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
我們想這個在我們索引中的文件只有現在的
_version為1時,本次更新才能成功。
此請求成功,並且響應體告訴我們 _version 已經遞增到 2 :
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
然而,如果我們重新執行相同的索引請求,仍然指定 version=1 , Elasticsearch 返回 409 ConflictHTTP 響應碼,和一個如下所示的響應體:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
這告訴我們在 Elasticsearch 中這個文件的當前 _version 號是 2 ,但我們指定的更新版本號為 1 。
我們現在怎麼做取決於我們的應用需求。我們可以告訴使用者說其他人已經修改了文件,並且在再次儲存之前檢查這些修改內容。 或者,在之前的商品 stock_count 場景,我們可以獲取到最新的文件並嘗試重新應用這些修改。
所有文件的更新或刪除 API,都可以接受 version 引數,這允許你在程式碼中使用樂觀的併發控制,這是一種明智的做法。
通過外部系統使用版本控制
一個常見的設定是使用其它資料庫作為主要的資料儲存,使用 Elasticsearch 做資料檢索, 這意味著主資料庫的所有更改發生時都需要被複制到 Elasticsearch ,如果多個程序負責這一資料同步,你可能遇到類似於之前描述的併發問題。
如果你的主資料庫已經有了版本號 — 或一個能作為版本號的欄位值比如 timestamp — 那麼你就可以在 Elasticsearch 中通過增加 version_type=external 到查詢字串的方式重用這些相同的版本號, 版本號必須是大於零的整數, 且小於 9.2E+18 — 一個 Java 中 long 型別的正值。
外部版本號的處理方式和我們之前討論的內部版本號的處理方式有些不同, Elasticsearch 不是檢查當前 _version 和請求中指定的版本號是否相同, 而是檢查當前 _version 是否 小於 指定的版本號。 如果請求成功,外部的版本號作為文件的新 _version 進行儲存。
外部版本號不僅在索引和刪除請求是可以指定,而且在 建立 新文件時也可以指定。
例如,要建立一個新的具有外部版本號 5 的部落格文章,我們可以按以下方法進行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
} 在響應中,我們能看到當前的 _version 版本號是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
現在我們更新這個文件,指定一個新的 version 號是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}請求成功並將當前 _version 設為 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
如果你要重新執行此請求時,它將會失敗,並返回像我們之前看到的同樣的衝突錯誤, 因為指定的外部版本號不大於 Elasticsearch 的當前版本號。