
elasticsearch 分散式文件儲存原理
路由一個文件到一個分片中
當索引一個文件的時候,文件會被儲存到一個主分片中。 Elasticsearch 如何知道一個文件應該存放到哪個分片中呢?當我們建立文件時,它如何決定這個文件應當被儲存在分片 1 還是分片 2 中呢?
首先這肯定不會是隨機的,否則將來要獲取文件的時候我們就不知道從何處尋找了。實際上,這個過程是根據下面這個公式決定的:
shard = hash(routing) % number_of_primary_shards
routing 是一個可變值,預設是文件的 _id ,也可以設定成一個自定義的值。 routing 通過 hash 函式生成一個數字,然後這個數字再除以 number_of_primary_shards
0 到 number_of_primary_shards-1 之間的餘數,就是我們所尋求的文件所在分片的位置。
這就解釋了為什麼我們要在建立索引的時候就確定好主分片的數量 並且永遠不會改變這個數量:因為如果數量變化了,那麼所有之前路由的值都會無效,文件也再也找不到了。
你可能覺得由於 Elasticsearch 主分片數量是固定的會使索引難以進行擴容。實際上當你需要時有很多技巧可以輕鬆實現擴容。我們將會在擴容設計一章中提到更多有關水平擴充套件的內容。
所有的文件 API( get 、 index 、 delete 、 bulk 、 update
mget )都接受一個叫做 routing 的路由引數 ,通過這個引數我們可以自定義文件到分片的對映。一個自定義的路由引數可以用來確保所有相關的文件——例如所有屬於同一個使用者的文件——都被儲存到同一個分片中。我們也會在擴容設計這一章中詳細討論為什麼會有這樣一種需求。
主分片和副本分片如何互動
為了說明目的, 我們 假設有一個叢集由三個節點組成。 它包含一個叫 blogs 的索引,有兩個主分片,每個主分片有兩個副本分片。相同分片的副本不會放在同一節點,所以我們的叢集看起來像 圖 8 “有三個節點和一個索引的叢集”。
圖 8. 有三個節點和一個索引的叢集
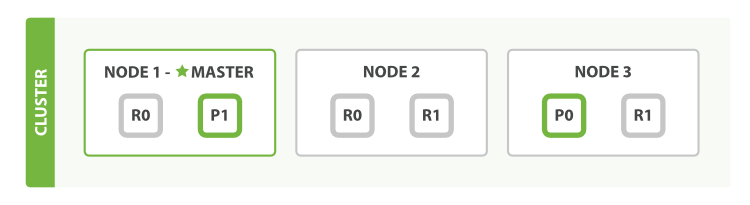
我們可以傳送請求到叢集中的任一節點。 每個節點都有能力處理任意請求。 每個節點都知道叢集中任一文件位置,所以可以直接將請求轉發到需要的節點上。 在下面的例子中,將所有的請求傳送到 Node 1
當傳送請求的時候, 為了擴充套件負載,更好的做法是輪詢叢集中所有的節點。
新建、索引和刪除文件
新建、索引和刪除 請求都是 寫 操作, 必須在主分片上面完成之後才能被複制到相關的副本分片,如下圖所示 圖 9 “新建、索引和刪除單個文件”.
圖 9. 新建、索引和刪除單個文件
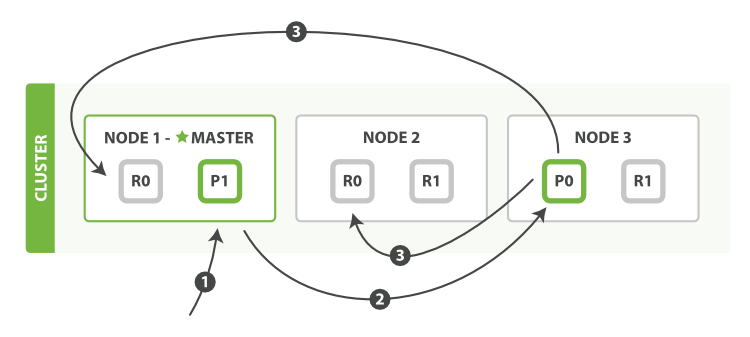
以下是在主副分片和任何副本分片上面 成功新建,索引和刪除文件所需要的步驟順序:
-
客戶端向
Node 1傳送新建、索引或者刪除請求。 -
節點使用文件的
_id確定文件屬於分片 0 。請求會被轉發到Node 3`,因為分片 0 的主分片目前被分配在 `Node 3上。 -
Node 3在主分片上面執行請求。如果成功了,它將請求並行轉發到Node 1和Node 2的副本分片上。一旦所有的副本分片都報告成功,Node 3將向協調節點報告成功,協調節點向客戶端報告成功。
在客戶端收到成功響應時,文件變更已經在主分片和所有副本分片執行完成,變更是安全的。
有一些可選的請求引數允許您影響這個過程,可能以資料安全為代價提升效能。這些選項很少使用,因為Elasticsearch已經很快,但是為了完整起見,在這裡闡述如下:
consistency
consistency,即一致性。在預設設定下,即使僅僅是在試圖執行一個_寫_操作之前,主分片都會要求必須要有 _規定數量(quorum)_(或者換種說法,也即必須要有大多數)的分片副本處於活躍可用狀態,才會去執行_寫_操作(其中分片副本可以是主分片或者副本分片)。這是為了避免在發生網路分割槽故障(network partition)的時候進行_寫_操作,進而導致資料不一致。_規定數量_即:
int( (primary + number_of_replicas) / 2 ) + 1
consistency 引數的值可以設為 one (只要主分片狀態 ok 就允許執行_寫_操作),all`(必須要主分片和所有副本分片的狀態沒問題才允許執行_寫_操作), 或 `quorum 。預設值為 quorum , 即大多數的分片副本狀態沒問題就允許執行_寫_操作。
注意,規定數量 的計算公式中 number_of_replicas 指的是在索引設定中的設定副本分片數,而不是指當前處理活動狀態的副本分片數。如果你的索引設定中指定了當前索引擁有三個副本分片,那規定數量的計算結果即:
int( (primary + 3 replicas) / 2 ) + 1 = 3
如果此時你只啟動兩個節點,那麼處於活躍狀態的分片副本數量就達不到規定數量,也因此您將無法索引和刪除任何文件。
timeout
如果沒有足夠的副本分片會發生什麼? Elasticsearch會等待,希望更多的分片出現。預設情況下,它最多等待1分鐘。 如果你需要,你可以使用 timeout 引數 使它更早終止: 100 100毫秒,30s 是30秒。
新索引預設有
1個副本分片,這意味著為滿足規定數量應該 需要兩個活動的分片副本。 但是,這些預設的設定會阻止我們在單一節點上做任何事情。為了避免這個問題,要求只有當number_of_replicas大於1的時候,規定數量才會執行。
取回一個文件
可以從主分片或者從其它任意副本分片檢索文件 ,如下圖所示 圖 10 “取回單個文件”.
圖 10. 取回單個文件
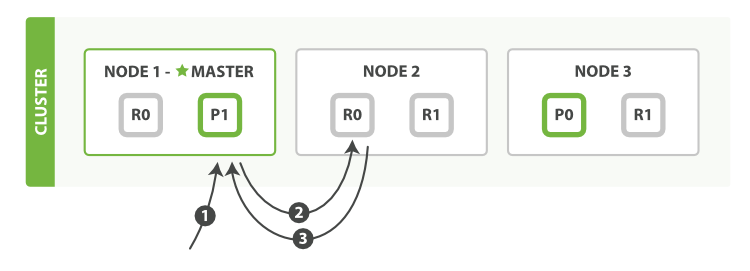
以下是從主分片或者副本分片檢索文件的步驟順序:
- 客戶端向
Node 1傳送獲取請求。 - 節點使用文件的
_id來確定文件屬於分片0。分片0的副本分片存在於所有的三個節點上。 在這種情況下,它將請求轉發到Node 2。 Node 2將文件返回給Node 1,然後將文件返回給客戶端。
在處理讀取請求時,協調結點在每次請求的時候都會通過輪詢所有的副本分片來達到負載均衡。
在文件被檢索時,已經被索引的文件可能已經存在於主分片上但是還沒有複製到副本分片。 在這種情況下,副本分片可能會報告文件不存在,但是主分片可能成功返回文件。 一旦索引請求成功返回給使用者,文件在主分片和副本分片都是可用的。
區域性更新文件
如 圖 11 “區域性更新文件” 所示,update API 結合了先前說明的讀取和寫入模式 。
圖 11. 區域性更新文件
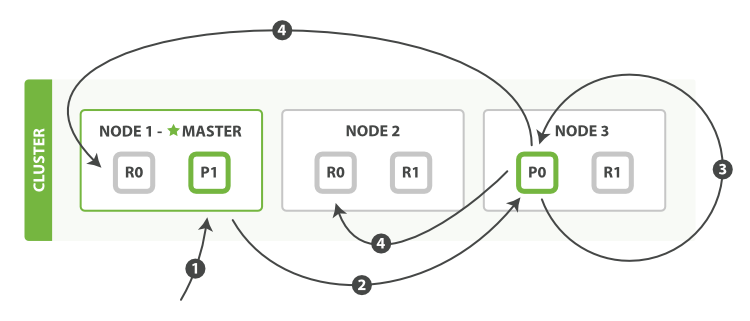
以下是部分更新一個文件的步驟:
- 客戶端向
Node 1傳送更新請求。 - 它將請求轉發到主分片所在的
Node 3。 Node 3從主分片檢索文件,修改_source欄位中的 JSON ,並且嘗試重新索引主分片的文件。 如果文件已經被另一個程序修改,它會重試步驟 3 ,超過retry_on_conflict次後放棄。- 如果
Node 3成功地更新文件,它將新版本的文件並行轉發到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向協調節點也返回成功,協調節點向客戶端返回成功。
update API 還接受在 新建、索引和刪除文件 章節中介紹的 routing 、 replication 、 consistency 和 timeout 引數。
基於文件的複製
當主分片把更改轉發到副本分片時, 它不會轉發更新請求。 相反,它轉發完整文件的新版本。請記住,這些更改將會非同步轉發到副本分片,並且不能保證它們以傳送它們相同的順序到達。 如果Elasticsearch僅轉發更改請求,則可能以錯誤的順序應用更改,導致得到損壞的文件。
多文件模式
mget 和 bulk API 的 模式類似於單文件模式。區別在於協調節點知道每個文件存在於哪個分片中。 它將整個多文件請求分解成 每個分片 的多文件請求,並且將這些請求並行轉發到每個參與節點。
協調節點一旦收到來自每個節點的應答,就將每個節點的響應收集整理成單個響應,返回給客戶端,如 圖 12 “使用 mget 取回多個文件” 所示。
圖 12. 使用 mget 取回多個文件
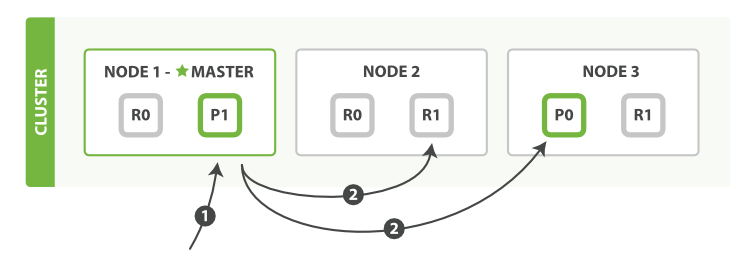
以下是使用單個 mget 請求取回多個文件所需的步驟順序:
- 客戶端向
Node 1傳送mget請求。 Node 1為每個分片構建多文件獲取請求,然後並行轉發這些請求到託管在每個所需的主分片或者副本分片的節點上。一旦收到所有答覆,Node 1構建響應並將其返回給客戶端。
可以對 docs 陣列中每個文件設定 routing 引數。
bulk API, 如 圖 13 “使用 bulk 修改多個文件” 所示, 允許在單個批量請求中執行多個建立、索引、刪除和更新請求。
圖 13. 使用 bulk 修改多個文件
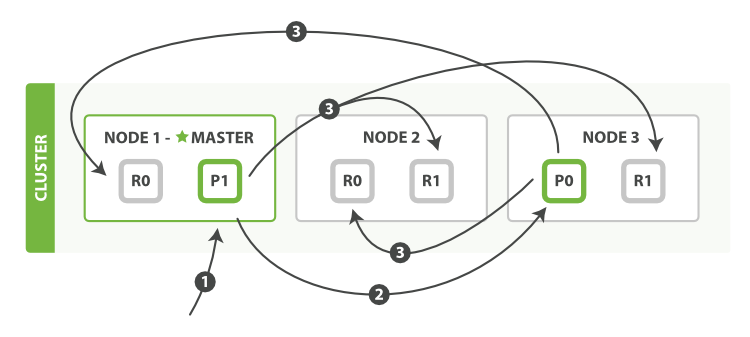
bulk API 按如下步驟順序執行:
- 客戶端向
Node 1傳送bulk請求。 Node 1為每個節點建立一個批量請求,並將這些請求並行轉發到每個包含主分片的節點主機。- 主分片一個接一個按順序執行每個操作。當每個操作成功時,主分片並行轉發新文件(或刪除)到副本分片,然後執行下一個操作。 一旦所有的副本分片報告所有操作成功,該節點將向協調節點報告成功,協調節點將這些響應收集整理並返回給客戶端。
bulk API 還可以在整個批量請求的最頂層使用 consistency 引數,以及在每個請求中的元資料中使用 routing 引數。
為什麼是有趣的格式?
當我們早些時候在代價較小的批量操作章節瞭解批量請求時, 您可能會問自己, "為什麼 bulk API 需要有換行符的有趣格式,而不是傳送包裝在 JSON 陣列中的請求,例如 mget API?" 。
為了回答這一點,我們需要解釋一點背景:在批量請求中引用的每個文件可能屬於不同的主分片, 每個文件可能被分配給叢集中的任何節點。這意味著批量請求 bulk 中的每個 操作 都需要被轉發到正確節點上的正確分片。
如果單個請求被包裝在 JSON 陣列中,那就意味著我們需要執行以下操作:
- 將 JSON 解析為陣列(包括文件資料,可以非常大)
- 檢視每個請求以確定應該去哪個分片
- 為每個分片建立一個請求陣列
- 將這些陣列序列化為內部傳輸格式
- 將請求傳送到每個分片
這是可行的,但需要大量的 RAM 來儲存原本相同的資料的副本,並將建立更多的資料結構,Java虛擬機器(JVM)將不得不花費時間進行垃圾回收。
相反,Elasticsearch可以直接讀取被網路緩衝區接收的原始資料。 它使用換行符字元來識別和解析小的 action/metadata 行來決定哪個分片應該處理每個請求。
這些原始請求會被直接轉發到正確的分片。沒有冗餘的資料複製,沒有浪費的資料結構。整個請求儘可能在最小的記憶體中處理。