
分散式釋出訂閱訊息系統Kafka
阿新 • • 發佈:2018-12-09
文章目錄
Kafka概述
卡夫卡是用於構建實時資料管道和流媒體應用。它是水平可伸縮的,容錯的,快速的,並執行在數千家公司的生產。
- PUBLISH & SUBSCRIBE
像訊息傳遞系統一樣讀寫資料流。 - PROCESS
編寫可伸縮的流式處理應用程式,實時響應事件。 - STORE
儲存資料流安全分佈,複製。容錯叢集。
Kafka概述和訊息系統類似
訊息中介軟體:生產者和消費者 媽媽:生產者 你:消費者 饅頭:資料流、訊息 正常情況下: 生產一個 消費一個 其他情況: 一直生產,你吃到某一個饅頭時,你卡主(機器故障), 饅頭就丟失了 一直生產,做饅頭速度快,你吃來不及,饅頭也就丟失了 拿個碗/籃子,饅頭做好以後先放到籃子裡,你要吃的時候去籃子裡面取出來吃 籃子/框: Kafka 當籃子滿了,饅頭就裝不下了,咋辦? 多準備幾個籃子 === Kafka的擴容
流處理平臺有三個關鍵功能:
- 釋出和訂閱資料流,類似於訊息佇列或企業訊息傳遞系統。
- 以容錯的持久方式儲存記錄流。
- 處理實時產生的資料流。
Kafka架構及核心概念
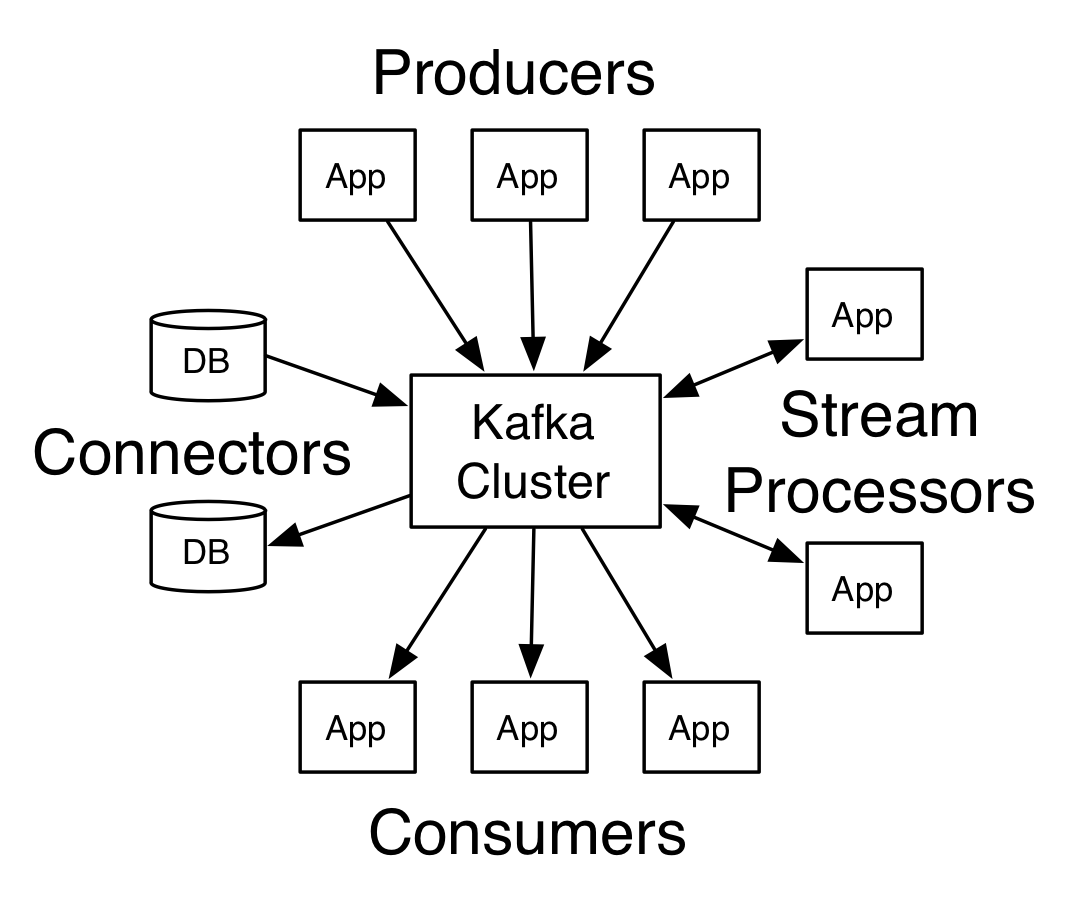
producer:生產者,就是生產饅頭(老媽)
consumer:消費者,就是吃饅頭的(你)
broker:籃子
topic:主題,給饅頭帶一個標籤,topica的饅頭是給你吃的,topicb的饅頭是給你弟弟吃
首先是幾個概念:
- Kafka作為一個叢集執行在一個或多個伺服器上,這些伺服器可以跨多個數據中心。
- Kafka叢集將記錄流儲存在稱為topic的類別中。
- 每個記錄由一個key、一個value和一個 timestamp組成。
Kafka單節點單Broker部署之Zookeeper安裝
kafka部署方式:
- 單節點單Broker部署及使用
- 單節點多Broker部署及使用
- 多節點多Broker部署及使用
單節點單Broker部署
1、zk直接解壓;配置環境變數(vi ~/.bash_profile)

修改ZK_HOME下的conf下的zoo.cfg
資料儲存路徑
2、下載解壓kafka;配置環境變數

修改配置檔案-$KAFKA_HOME/config/server.properties
broker.id=0
listeners //監聽的埠
host.name //啟動在本臺機器ip
log.dirs //日誌儲存路徑
zookeeper.connect //外部zk
啟動Kafka
kafka-server-start.sh
USAGE: /home/hadoop/app/kafka_2.11-0.9.0.0/bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
kafka-server-start.sh $KAFKA_HOME/config/server.properties

建立topic: zk
kafka-topics.sh --create --zookeeper hadoop000:2181 --replication-factor 1 --partitions 1 --topic hello_topic
檢視所有topic
kafka-topics.sh --list --zookeeper hadoop000:2181

注意要分別在不同的控制檯執行
傳送訊息: broker
kafka-console-producer.sh --broker-list hadoop000:9092 --topic hello_topic
消費訊息: zk
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic --from-beginning
--from-beginning的使用是從頭消費
檢視所有topic的詳細資訊:kafka-topics.sh --describe --zookeeper hadoop000:2181
檢視指定topic的詳細資訊:kafka-topics.sh --describe --zookeeper hadoop000:2181 --topic hello_topic

單節點多Broker部署及使用

分別修改三個配置檔案
server-1.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-1
listeners=PLAINTEXT://:9093
broker.id=1
server-2.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-2
listeners=PLAINTEXT://:9094
broker.id=2
server-3.properties
log.dirs=/home/hadoop/app/tmp/kafka-logs-3
listeners=PLAINTEXT://:9095
broker.id=3
啟動kafak
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-1.properties &
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-2.properties &
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-3.properties &
測試:
//建立一個topic
kafka-topics.sh --create --zookeeper hadoop000:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
//生產端傳送訊息
kafka-console-producer.sh --broker-list hadoop000:9093,hadoop000:9094,hadoop000:9095 --topic my-replicated-topic
//消費者消費訊息
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic my-replicated-topic
//檢視topic的訊息
kafka-topics.sh --describe --zookeeper hadoop000:2181 --topic my-replicated-topic
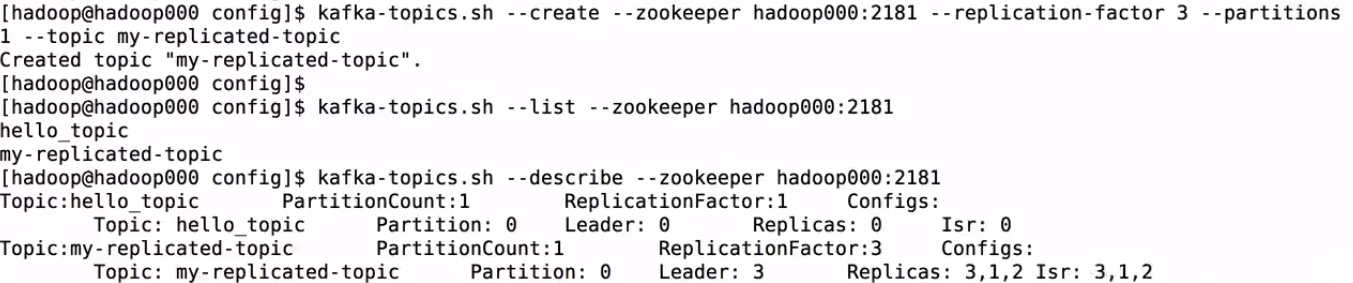
Kafka容錯性測試

kill掉server2

經過測試消費者和生產者都可以正常進行
查詢topic的詳細資訊發現活得節點就只剩3和1

繼續kill掉server3

測試消費者和生產者都可以正常進行;雖然有warning日誌;但是沒有影響幹活
在scala-maven的IDEA下Kafka Java API程式設計測試
加入kafka依賴
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.0</version>
</dependency>
/**
* Kafka常用配置檔案
*/
public class KafkaProperties {
public static final String ZK = "192.168.199.111:2181";
public static final String TOPIC = "hello_topic";
public static final String BROKER_LIST = "192.168.199.111:9092";
public static final String GROUP_ID = "test_group1";
}
Kafka Producer
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
/**
* Kafka生產者
*/
public class KafkaProducer extends Thread{
private String topic;
private Producer<Integer, String> producer;
public KafkaProducer(String topic) {
this.topic = topic;
Properties properties = new Properties();
properties.put("metadata.broker.list",KafkaProperties.BROKER_LIST);
properties.put("serializer.class","kafka.serializer.StringEncoder");
properties.put("request.required.acks","1");
producer = new Producer<Integer, String>(new ProducerConfig(properties));
}
@Override
public void run() {
int messageNo = 1;
while(true) {
String message = "message_" + messageNo;
producer.send(new KeyedMessage<Integer, String>(topic, message));
System.out.println("Sent: " + message);
messageNo ++ ;
try{
Thread.sleep(2000);
} catch (Exception e){
e.printStackTrace();
}
}
}
}
Kafka Consumer
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* Kafka消費者
*/
public class KafkaConsumer extends Thread{
private String topic;
public KafkaConsumer(String topic) {
this.topic = topic;
}
private ConsumerConnector createConnector(){
Properties properties = new Properties();
properties.put("zookeeper.connect", KafkaProperties.ZK);
properties.put("group.id",KafkaProperties.GROUP_ID);
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
@Override
public void run() {
ConsumerConnector consumer = createConnector();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
// topicCountMap.put(topic2, 1);
// topicCountMap.put(topic3, 1);
// String: topic
// List<KafkaStream<byte[], byte[]>> 對應的資料流
Map<String, List<KafkaStream<byte[], byte[]>>> messageStream = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStream.get(topic).get(0); //獲取我們每次接收到的資料
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while (iterator.hasNext()) {
String message = new String(iterator.next().message());
System.out.println("rec: " + message);
}
}
}
/**
* Kafka Java API測試
*/
public class KafkaClientApp {
public static void main(String[] args) {
new KafkaProducer(KafkaProperties.TOPIC).start();
new KafkaConsumer(KafkaProperties.TOPIC).start();
}
}
IDEA控制檯

虛擬機器Consumer控制檯


Kafka實戰之整合Flume和Kafka完成實時資料採集

更改Flume實戰案例三中的下半部分avro-memory-logger.conf為avro-memory-kafka.conf
avro-memory-kafka.conf
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
啟動測試:
flume-ng agent \
--name avro-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic