
大資料離線-HDFS(上)
本次介紹HDFS,分為上,中,下,三篇
- 上篇入HDFS門介紹,常用操作
- 中篇為HDFS的讀寫原理介紹
- 下篇為HDFS的測試Demo,常用API
1. HDFS的基本概念
HDFS的介紹 HDFS 是 Hadoop Distribute File System 的簡稱, 意為: Hadoop 分散式檔案系統。 是 Hadoop 核心元件之一,作為最底層的分散式儲存服務而存在。 分散式檔案系統解決的問題就是大資料儲存。 它們是橫跨在多臺計算機上的儲存系統。分散式檔案系統在大資料時代有著廣泛的應用前景,它們為儲存和處理超大規模資料提供所需的擴充套件能力
HDFS的設計目的 過程1
過程2
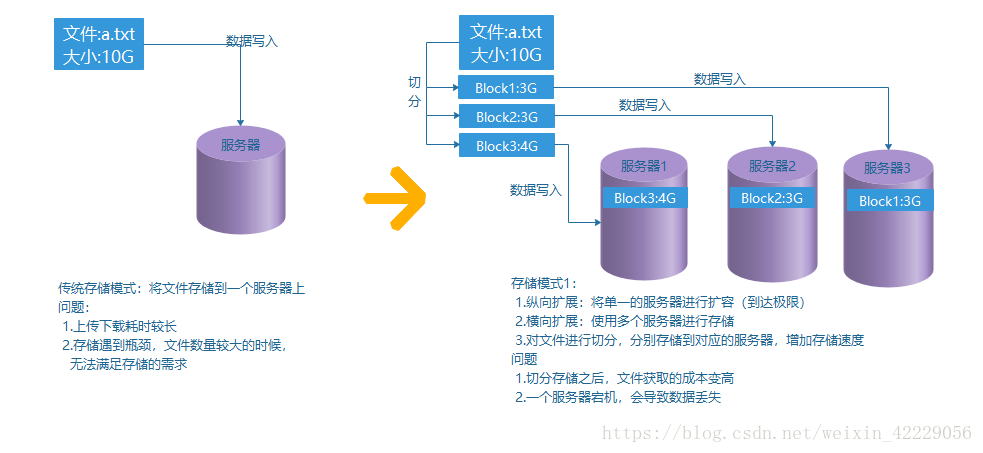
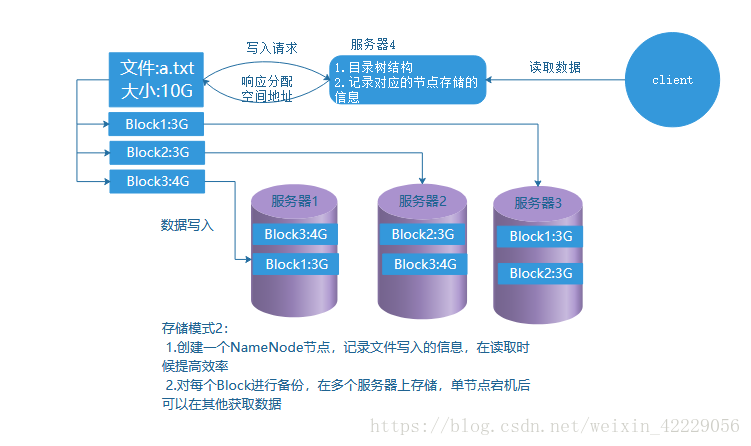
儲存模式2就是簡單的HDFS的儲存模型,具體的儲存過程,在下一篇的儲存和讀取中會進行詳細的講解。
2.HDFS的重要特性
master/slave 架構 HDFS 採用 master/slave 架構。 一般一個 HDFS 叢集是有一個 Namenode 和一定數目的 Datanode 組成。 Namenode 是 HDFS 叢集主節點, Datanode 是 HDFS 叢集從節點,兩種角色各司其職,共同協調完成分散式的檔案儲存服務。
分塊儲存 HDFS 中的檔案在物理上是分塊儲存(block) 的,塊的大小可以通過配置引數來規定,預設大小在 hadoop2.x 版本中是 128M。
名稱空間NameSpace HDFS 支援傳統的層次型檔案組織結構。使用者或者應用程式可以建立目錄,然後將檔案儲存在這些目錄裡。檔案系統名字空間的層次結構和大多數現有的檔案系統類似:使用者可以建立、刪除、移動或重新命名檔案。 Namenode 負責維護檔案系統的名字空間,任何對檔案系統名字空間或屬性 的修改都將被 Namenode 記錄下來。 HDFS 會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問檔案, 形如: hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
Namenode 元資料管理 -我們把目錄結構及檔案分塊位置資訊叫做元資料。 Namenode 負責維護整個hdfs 檔案系統的目錄樹結構,以及每一個檔案所對應的 block 塊資訊(block 的 id,及所在的 datanode 伺服器)。
DataNode資料儲存 檔案的各個 block 的具體儲存管理由 datanode 節點承擔。 每一個 block 都可以在多個 datanode 上。 Datanode 需要定時向 Namenode 彙報自己持有的 block資訊。儲存多個副本(副本數量也可以通過引數設定 dfs.replication,預設是 3)。
副本機制 為了容錯,檔案的所有 block 都會有副本。每個檔案的 block 大小和副本系數都是可配置的。應用程式可以指定某個檔案的副本數目。副本系數可以在檔案建立的時候指定,也可以在之後改變。
一次寫入,多次讀出 HDFS 是設計成適應一次寫入,多次讀出的場景,且不支援檔案的修改。正因為如此, HDFS 適合用來做大資料分析的底層儲存服務,並不適合用來做.網盤等應用,因為,修改不方便,延遲大,網路開銷大,成本太高。
3. HDFS的基本操作
- Shell命令列客戶端 Hadoop 提供了檔案系統的 shell 命令列客戶端,使用方法如下:
hadoop fs <args> //<args表示引數>檔案系統 shell 包括與 Hadoop 分散式檔案系統( HDFS)以及 Hadoop 支援的其他檔案系統( 如本地 FS, HFTP FS, S3 FS 等) 直接互動的各種類似 shell 的命令。 所有 FS shell 命令都將路徑 URI 作為引數。
URI 格式為 scheme://authority/path。`對於 HDFS,該 scheme 是 hdfs,對於本地 FS,該 scheme 是 file。 scheme 和 authority 是可選的。 如果未指定,則使用配置中指定的預設方案。
對於 HDFS,命令示例如下:
hadoop fs -ls hdfs://namenode:host/parent/child
//hadoop fs -ls /parent/child fs.defaultFS 中有配置對於本地檔案系統,命令示例如下:
hadoop fs -ls file:///root/如果使用的檔案系統是 HDFS,則使用 hdfs dfs 也是可以的,hadoop1.x的使用方式。
命令如下
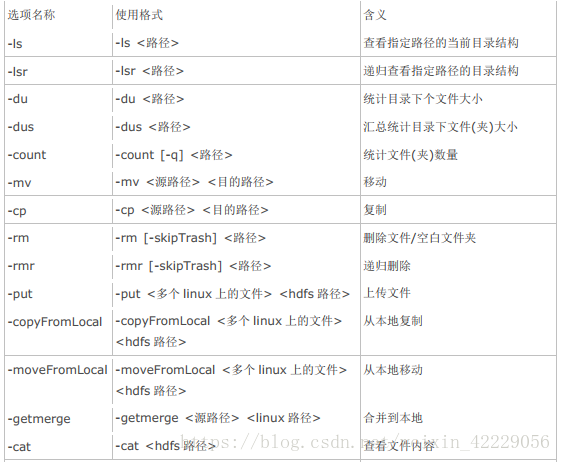

具體演示如下
-ls
功能: 顯示檔案、 目錄資訊。
使用方法: hadoop fs -ls [-h][-R] <args>
例項:hadoop fs -ls /user/hadoop/file1-mkdir
功能: 在 hdfs 上建立目錄, -p 表示會建立路徑中的各級父目錄。
使用方法: hadoop fs -mkdir [-p] <paths>
示例: hadoop fs -mkdir – p /user/hadoop/dir1-put
功能: 將單個 src 或多個 srcs 從本地檔案系統複製到目標檔案系統。
使用方法: hadoop fs -put [-f] [-p] [ -|<localsrc1> .. ]. <dst>
-p:保留訪問和修改時間,所有權和許可權。
-f:覆蓋目的地(如果已經存在)
示例: hadoop fs -put -f localfile1 localfile2 /user/hadoop/hadoopdir- -get 功能:將檔案下載到本地系統
使用方法: hadoop fs -get [-ignorecrc][-crc][-p][-f] <src> <localdst>
-ignorecrc:跳過對下載檔案的 CRC 檢查。
-crc:為下載的檔案寫 CRC 校驗和。
示例: hadoop fs -get hdfs://host:port/user/hadoop/file localfile- -appendToFile 功能:追加一個檔案到已經存在的檔案末尾
使用方法: hadoop fs -appendToFile <localsrc> ... <dst>
示例: hadoop fs -appendToFile localfile /hadoop/hadoopfile- -cat 功能:顯示檔案內容到 stdout
使用方法: hadoop fs -cat [-ignoreCrc] URI [URI ...]
示例: hadoop fs -cat /hadoop/hadoopfile- -tail 功能: 將檔案的最後一千位元組內容顯示到 stdout。
使用方法: hadoop fs -tail [-f] URI
-f 選項將在檔案增長時輸出附加資料。
示例: hadoop fs -tail /hadoop/hadoopfile- -chmod 功能: 改變檔案的許可權。使用-R 將使改變在目錄結構下遞迴進行。
示例: hadoop fs -chmod 666 /hadoop/hadoopfile- -cp 功能:從 hdfs 的一個路徑拷貝 hdfs 的另一個路徑
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 - -mv 功能:在 hdfs 目錄中移動檔案
示例: hadoop fs -mv /aaa/jdk.tar.gz /- -rm 功能: 刪除指定的檔案。只刪除非空目錄和檔案。 -r 遞迴刪除。
示例: hadoop fs -rm -r /aaa/bbb/- -df 功能:統計檔案系統的可用空間資訊
示例: hadoop fs -df -h /- -du 功能: 顯示目錄中所有檔案大小,當只指定一個檔案時,顯示此檔案的大小。
示例: hadoop fs -du /user/hadoop/dir1- -setrep 功能: 改變一個檔案的副本系數。 -R 選項用於遞迴改變目錄下所有檔案的副本 係數。
示例: hadoop fs -setrep -w 3 -R /user/hadoop/dir1上篇的內容的到此結束
本部落格主要對大資料的學習進行系統的講解,感興趣的同學可以關注訂閱。