
反彙編演算法介紹和應用——線性掃描演算法分析
做過逆向的朋友應該會很熟悉IDA和Windbg這類的軟體。IDA的強項在於靜態反彙編,Windbg的強項在於動態除錯。往往將這兩款軟體結合使用會達到事半功倍的效果。可能經常玩這個的朋友會發現IDA反彙編的程式碼準確度要高於Windbg,深究其原因,是因為IDA採用的反彙編演算法和Windbg是不同的。下面我來說說我所知道的兩種反彙編演算法。(轉載請指明來自breaksoftware的csdn部落格)
1 線性掃描(Linear sweep)
線性掃描是一種非常基礎的反彙編演算法。看到“線性”二字,我們腦海裡可能會立馬浮現出一個指標對一段記憶體中資料從開始到最後進行一次遍歷的場景。而實際上這種演算法的確是如此執行的。像windbg就是使用這種反彙編演算法的。反彙編步驟是:
A 位置指標lpStart指向程式碼段開始處
B 從lpStart位置開始嘗試匹配指令,並得到指令長度n
C 如果B成功,則反彙編(Intel風格或者AT&T風格)從lpStart之後n個數據;如果失敗,則退出
D 位置指標lpStart賦值為lpStart+n,即上條指令的結尾
E 判斷lpStart是否超過了程式碼段結尾處,如果超出則結束。如果不超出則進入B流程。
在A、E這兩個過程中,我們需要提前確定程式碼開始處和結束處。一般來說,在windows平臺上,我們可以根據PE檔案的可選頭標準域中BaseOfCode結合DataDirectory中相關資訊可以算出來程式碼開始位置,從PE檔案可選頭標準域中SizeOfCode得到程式碼段總大小,從而確定結尾位置。
在B這個過程,對於不同指令集存在細微的差別。現在簡要說下主要兩種指令集:
RISC全稱是Reduced Instruction Set Computing,即精簡指令集。該指令集有個非常重要的特定——指令長度相同,這樣反彙編匹配不會出現回溯現象。
CISC全稱是Complex Instruction Set Computer,即複雜指令集。該指令集一個重要的特點是和RISC正好相反的——指令長度可變,這樣反彙編匹配會出現回溯現象。
可以發現線性掃描的一大特點就是簡單方便,但是它存在一個問題:它無法知道整個程式的執行流。使用過IDA的朋友會發現,在我們使用IDA開啟一個PE檔案時,IDA會給我們顯示一個UML型別的執行流程圖。而Windbg就沒有這樣的功能。為什麼?就是因為線性掃描有不知執行流這個缺陷。
既然知道了缺陷,那麼在充滿極客的安全領域,自然有人會去研究和利用。我們可以利用這個缺陷,讓Windbg這類使用線性反彙編演算法的工具分析出錯誤的結果。
我們開始一個思考個過程:看如上ABCDE流程,我們可以發現特別“懸”的一個操作就是確定lpStart。因為只要lpStart確定錯誤,那麼分析出來的結果肯定是不對的。的確,線性掃描演算法就是存在這樣一個致命的問題。那如何利用呢?
a 在一條可以改變執行流的有效指令後插入無效資訊
這兒所說的指令包括jmp,ja等跳轉,以及ret等改變EIP的指令。
我們先看個跳轉指令例子
int _tmain(int argc, _TCHAR* argv[])
{
int i = argc;
if ( argc > 1 ) {
i++;
}
__asm
{
jz position
jnz position
_emit 0xE8
position:
}
i++;
return 0;
}
我們使用jz position、jnz position使程式的執行流肯定走到position處,從而我們在jnz position這條有效指令後插入的0xE8是個無效資料。這樣我們將觸發線性掃描出錯
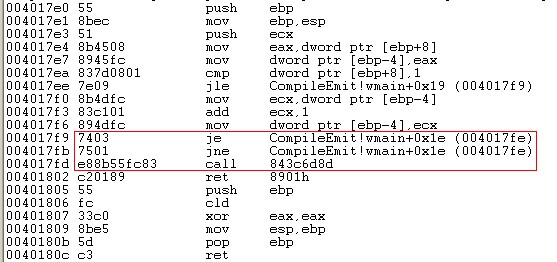
我們可以看到插入的0xE8(call指令)影響了分析結果,因為線性掃描在掃描004017fb~004017fc時發現是有效的jne指令,於是它傻乎乎的認為004017fd開始的就是下一條指令開始處。正確的結果我們看IDA的反彙編結果

我們再看一個ret的例子
因為push xxx使得棧頂為xxx,而ret將pop出xxx,並將EIP改成xxx,讓程式從xxx初開始執行。這樣我們又構造了一個無效資料0xE8。我們看看Windbg和IDA的反彙編結果
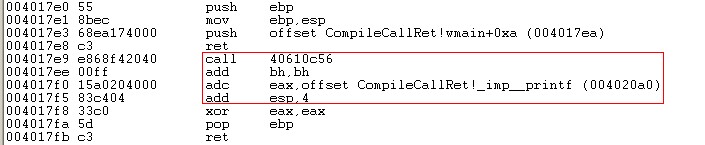
Windbg
IDA(此處IDA有點智慧,它判斷了下ret之後的EIP是否為一個固定地址)
b 正常的流程識別錯誤
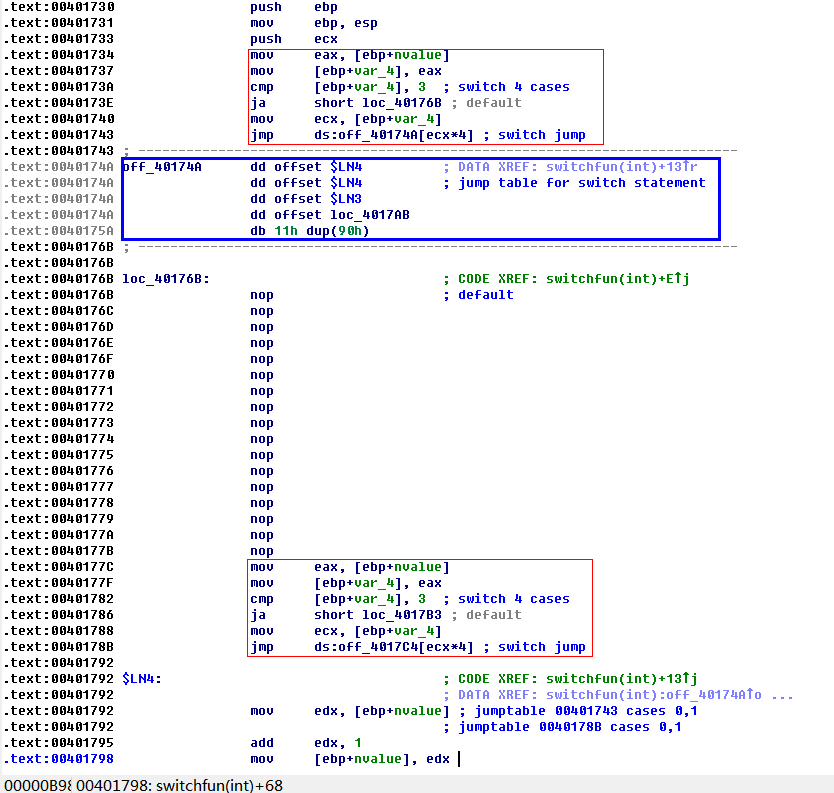
編譯器在將處理我們程式碼時是有策略的,比如當我們switch中case比較多的時候(我在我的環境測試時發現好像要超過2個case),switch case邏輯會使用跳轉表來表達。舉個例子
int switchfun(int nvalue){
switch(nvalue) {
case 0:
case 1: {
nvalue++;
}break;
case 2: {
nvalue += 2;
}break;
case 3: {
nvalue += 3;
}break;
default: {
nvalue = 0;
};
}
return nvalue;
}

可以見到這就是使用了跳轉表。我們可以看到0040177C位置是一組資料。如果我們將這個跳轉表放在0040174A處,將原來0040174A的邏輯後移,並修正相關偏移,是不是我們就讓Windbg分析出錯呢?是的,可是為了構造這樣的結構,我得對我的程式碼做改動,且要修改生成的二進位制檔案。
int switchfun(int nvalue){
{
__asm nop;
.
.
.
__asm nop;
}
switch(nvalue) {
case 0:
case 1: {
nvalue++;
}break;
case 2: {
nvalue += 2;
}break;
case 3: {
nvalue += 3;
}break;
default: {
nvalue = 0;
};
}
return nvalue;
}
我們人為插入多個nop,為我們之後方便修改二進位制檔案提供空間,同時可以減少計算偏移的量。對二進位制檔案修改如下

我將從B7C到B92的資料拷貝到以前是一串90(nop)開始處的B34。並緊跟這串資料,將BC4開始的跳轉表資料拷貝過來,同時修正跳轉表的偏移(C4->4A)。程式可以正確執行,我們看windbg的反彙編結果。

錯了吧!
我們再看看IDA的反彙編結果
可以見到IDA分析是正確的。
經過如上分析,是不是你覺得IDA比Windbg好呢?其實也不一定。線性掃描的一個大優點就是它可以把所有程式碼都反彙編掉,而IDA使用的遞迴下降(recursive descent)演算法並不一定會將所有程式碼都反彙編掉,我會在下一篇博文說明如何利用IDA這個缺陷,來隱藏我們不想被反彙編的邏輯。
做過逆向的朋友應該會很熟悉IDA和Windbg這類的軟體。IDA的強項在於靜態反彙編,Windbg的強項在於動態除錯。往往將這兩款軟體結合使用會達到事半功倍的效果。可能經常玩這個的朋友會發現IDA反彙編的程式碼準確度要高於Windbg,深究其原因,是因為IDA採用的反彙編演算法和Windbg是不同的。下面我來說說我所知道的兩種反彙編演算法。(轉載請指明來自breaksoftware的csdn部落格)