
搭建redis-scrapy分散式爬蟲環境
阿新 • • 發佈:2018-12-09
ubuntu上作主機
A . 主機---管理指紋佇列,資料佇列,request隊:redis, 建議不要爬資料。
1臺主機,用ubutnu系統
上課演示的是這臺電腦也爬取,不光要安裝redis, 還要安裝scrapy(先)和scrapy-redis(後)
基本步奏:
1. 啟動服務:redis-server
2. 使用 redis 客戶端檢視是否啟動:redis-cli
必須安裝的是redis: apt-get install redis-server
3. 如果要把當前電腦當成Master端把bind 127.0 步奏實現: ubuntu上裝redis
1. cd, 在根目錄下,裝redis-server
sudo apt-get install redis-server
2. 啟動 Redis 服務
redis-server
3.(ctrl +arl +t, 另一視窗) 啟動redis 客戶端
redis-cli
4.ping:pong
127.0.0.1 是本機 IP ,6379 是 redis 服務埠。現在我們輸入 PING 命令------ window上裝: RedisDesktopManager , 並連ubuntu上的redis, 管理redis資料
1, 點選RedisDesktopManager.exe 直接一步步安裝就行,
2. 裝好後, 連結上ubtuntu上的redis伺服器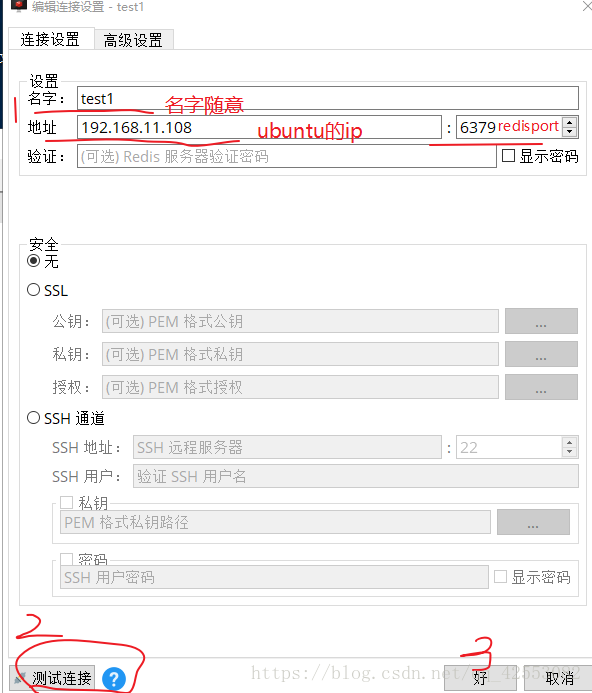
2. 從機(奴隸),專門做爬取資料,只要執行程式碼:安裝scrapy和scrapy-redis
從機2臺
window一臺,和另外一臺ubuntu系統
安裝scrapy命令:pip3 install scrapy
安裝scrapy-redis命令:pip install scrapy-redis
3. 測試從機是否可用連結上主機的redis
從機爬取的資料要傳輸到主機的redis,判斷request是否請求
連結到主機的命令:redis-cli -h 主機的ip
例如:redis-cli -h 192.168.11.73
四、scrapy-redis原始碼自帶專案說明
執行爬蟲:
from scrapy import cmdline
cmdline.execute("scrapy crawl mycrawler_redis".split())
讓爬蟲開始爬取網站命令:
進入到redis客戶端:redis-cli
執行任務的命令:lpush mycrawler:start_urls https://www.sina.com.cn/
lpush myspider:start_urls https://hr.tencent.com/position.php?&start=0#a
五、scrapy_redis執行流程和scrapy對比