
Weka安裝及簡單應用
因為前段時間上課有接觸WEKA這個軟體 ,寫了一個實驗報告,特此把它貼出來,希望能對大家有所幫助~
一、Weka介紹
1、Weka簡介
Weka是懷卡託智慧分析環境(Waikato Environment for Knowledge Analysis)的英文字首縮寫,在該網站可以免費下載可執行軟體和原始碼,還可以獲得說明文件、常見問題解答、資料集和其他文獻等資源。Weka是紐西蘭懷卡託大學用Java開發的資料探勘著名開源軟體,該系統自1993年開始由紐西蘭政府資助,至今已經歷了20年的發展,其功能已經十分強大和成熟。
Weka作為一個公開的資料探勘工作平臺,集合了大量能承擔資料探勘任務的機器學習演算法,包括對資料進行預處理,分類,迴歸、聚類、關聯規則以及在新的互動式介面上的視覺化。如果想自己實現資料探勘演算法的話,可以看一看WEKA的介面文件。在WEKA中整合自己的演算法甚至借鑑它的方法自己實現視覺化工具並不是件很困難的事情。
2、Weka的安裝
WEKA的官方地址是www.cs.waikato.ac.nz/ml/weka/downloading.html。點開左側download欄,可以進入下載頁面,裡面有windows, mas os, linux等平臺下的版本。目前穩定的版本是3.8。
如果本機沒有安裝java,可以選擇帶有jre的版本。下載後是一個exe的可執行檔案,雙擊進行安裝即可。
安裝步驟:

安裝完畢,啟動weka的快捷方式,就可以看到圖1的介面。
圖1 weka主介面
一般常用的有四個應用,分別是:
(1)Explorer
系統提供的最容易使用的影象使用者介面。通過選擇選單和填寫表單,可以呼叫weka的所有功能。這是用來進行資料實驗、挖掘的環境,它提供了分類,聚類,關聯規則,特徵選擇,資料視覺化等等功能,如圖2所示。
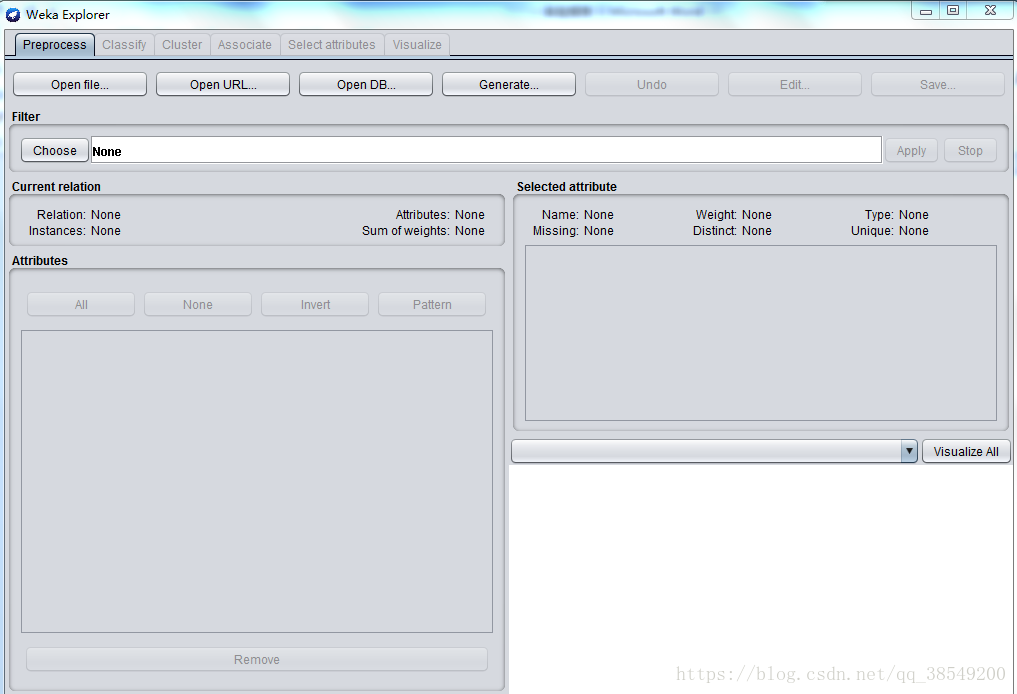
圖 2 Explorer 介面
(2)Experimenter
用於幫助使用者解答實際應用分類和迴歸技術中遇到的一個基本問題——對於一個已知問題,哪種方法及引數值能夠取得最佳效果?通過Weka提供的實驗者工作環境,使用者可以比較不同的學習方案。儘管探索者介面也能通過互動完成這樣的功能,但通過實驗者介面,使用者可以讓處理過程實現自動化。實驗者介面更加容易使用不同引數去設定分類器和過濾器,使之執行在一組資料集中,收集效能統計資料,實現重要的測試實驗,介面如圖3所示。
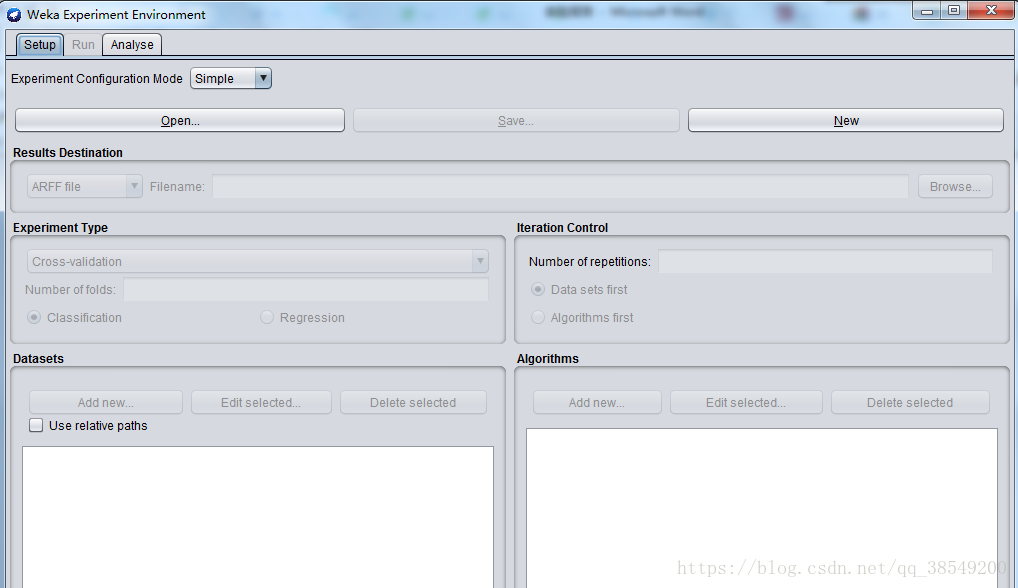
圖3 Experimenter主介面
(3)KnowledgeFlow
可以使用增量方式的演算法來處理大型資料集,使用者可以定製處理資料流的方式和順序。知識流介面允許使用者在螢幕上任意拖曳代表學習演算法和資料來源的圖形構件,並以一定的方式和順序組合在一起。也就是,按照一定順序將代表資料來源、預處理工具、學習演算法、評估手段和視覺化模組的各構件組合在一起,形成資料流。如果使用者選取的過濾器和學習演算法具有增量學習功能,那就可以實現大型資料集的增量分批讀取和處理,介面如圖4所示。
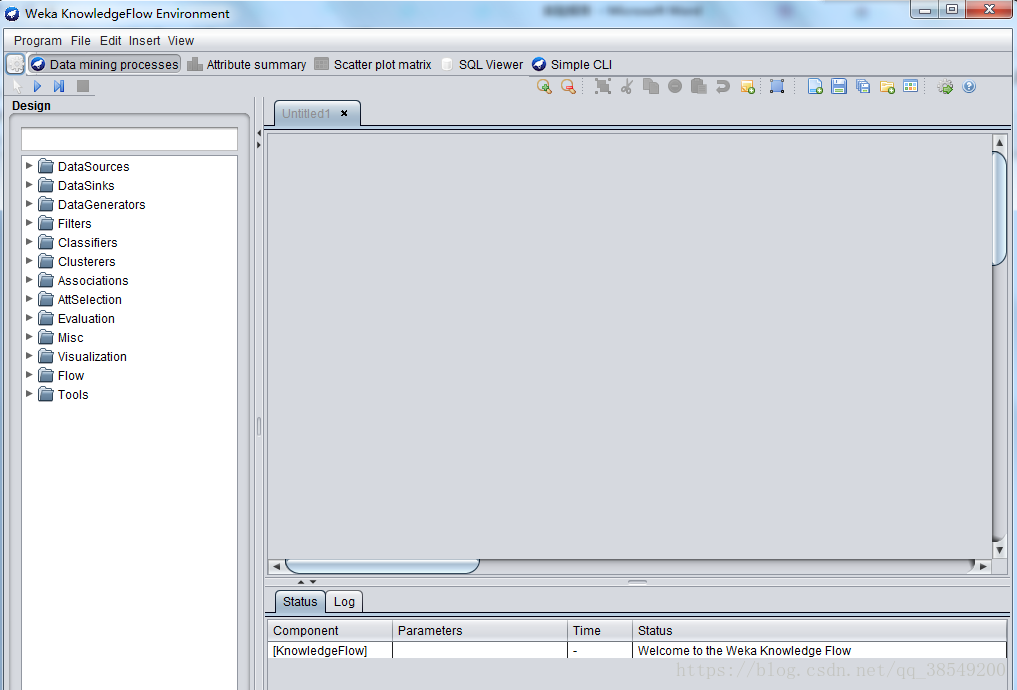
圖4 KnowledgeFlow介面
(4)Simple CLI
是為不提供自己的命令列介面的作業系統提供的,該簡單命令列介面用於和使用者進行互動,可以直接執行Weka命令,如圖5所示。
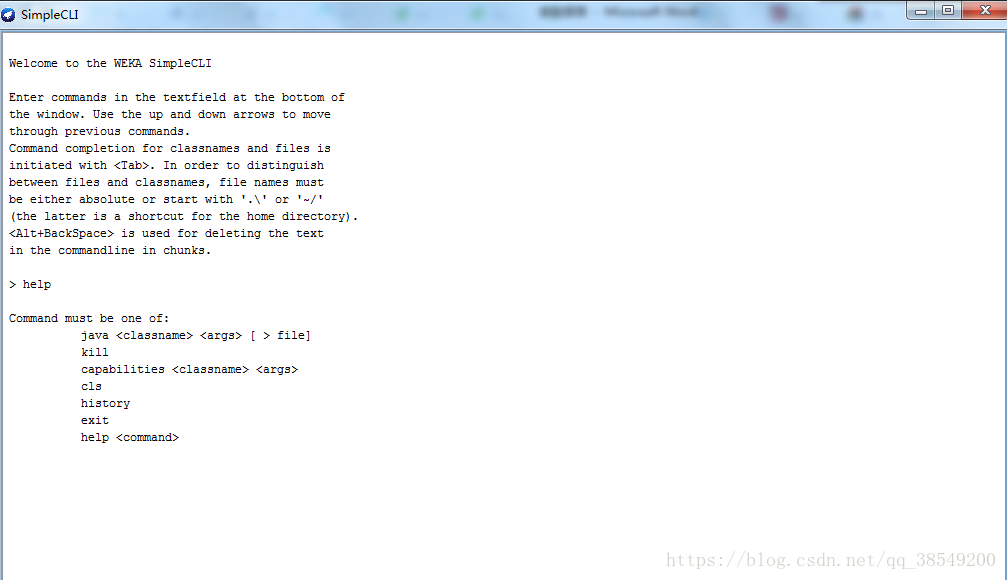
圖5 Simple CLI介面
二、分類演算法
1、資料說明
實驗的資料來源於UCI資料集,網址如下:
該資料的資料屬性如下:
- age (numeric),年齡;
- job (nominal),工作型別;
- marital (nominal),婚姻狀態;
- education (nominal),教育程度;
- default (nominal),是否有信用違約記錄;
- balance (numeric),年平均餘額;
- housing (nominal),是否有房貸;
- loan (nominal),是否有個人貸款記錄;
- contact (nominal),溝通型別;
- day (numeric),每月最後一個接觸日;
- month (nominal),每年最後一個接觸月;
- duration (numeric),最後一次接觸時間;
- campaign (numeric),在此活動期間和此客戶執行的聯絡人數量;
- pdays (numeric),上次與客戶聯絡的日期是在上次活動之後;
- previous (numeric),在此活動之前和此客戶端執行的聯絡人數量;
- poutcome (nominal),上次營銷活動的結果;
- y(nominal)
2、資料預處理
(1)匯入資料
Weka平臺支援ARFF格式和CSV格式的資料。我在UCI上下載的是CSV格式的資料,但在匯入的時候還是會報錯。經過反覆實驗發現,我下載的CSV檔案中的資料是由冒號將資料隔開的,把冒號換成逗號,就能成功匯入了。
也可以利用WEKA將CSV格式轉換成ARFF格式再匯入,方法如下:
執行WEKA的主程式,出現GUI後可以點選下方按鈕進入相應的模組。我們點選進入“Simple CLI”模組提供的命令列功能。由於weka暫不支援中文輸入,所以挑選了在D盤下進行轉換,在新視窗的最下方(上方是不能寫字的)輸入框寫上java weka.core.converters.CSVLoader D:/bank-full.csv > D:/bank-full.arff,即可成功轉換,生成檔案“D:/bank-full.arff”如圖6。
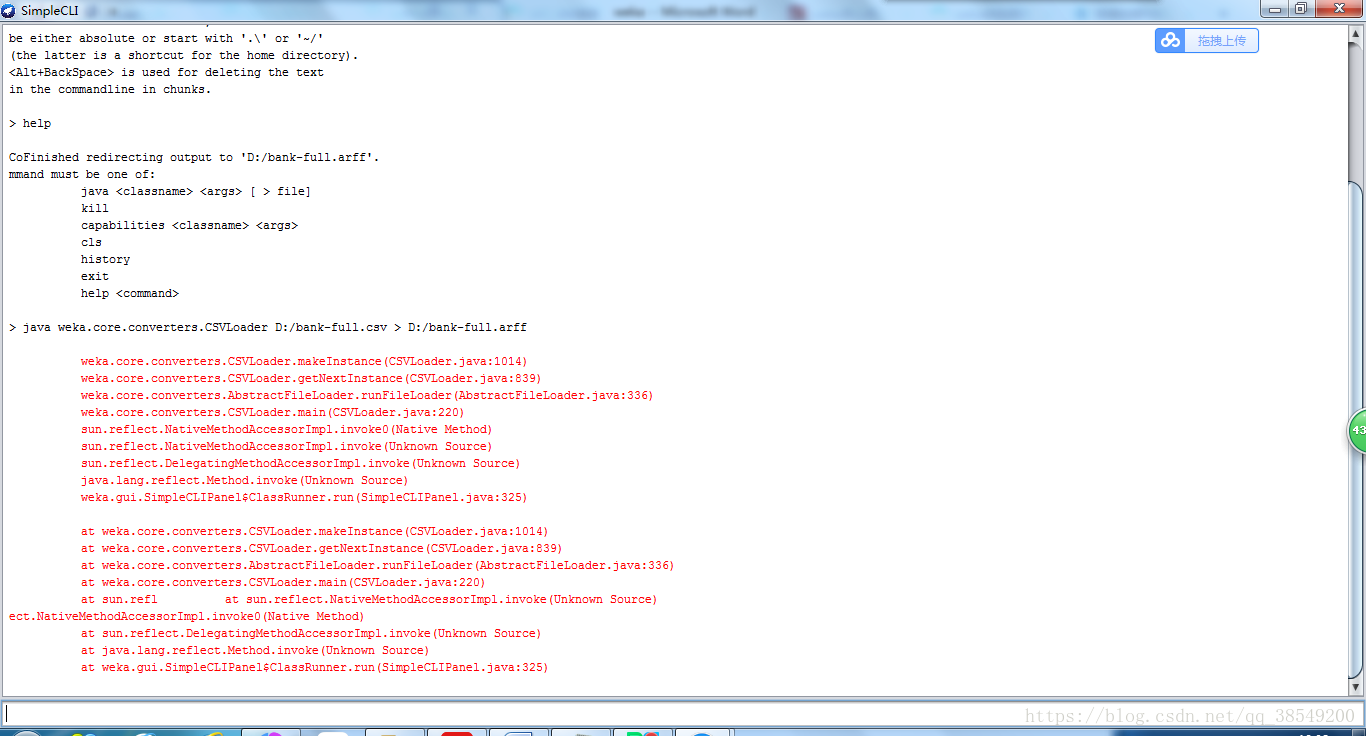
圖6 資料轉換過程圖
還有一種方法,進入“Exploer”模組,從上方的按鈕中開啟CSV檔案然後另存為ARFF檔案亦可。實驗所需的訓練集為bank-full.arff,測試集為bank-test.arff。
(2)資料預處理
通常對於WEKA來說並不支援中文,所以我們將一些涉及中文的欄位刪除。WEKA支援的<datatype>有四種,分別是:numeric--數值型,<nominal-specification>--分類(nominal)型,string--字串型,date [<date-format>]--日期和時間型。
而本表只有nemeric和nominal兩種型別,數值屬性(nemeric) 數值型屬性可以是整數或者實數,但WEKA把它們都當作實數看待。分類屬性(nominal) 分類屬性由<nominal-specification>列出一系列可能的類別名稱並放在花括號中:{<nominal- name1>, <nominal-name2>, ...} 。資料集中該屬性的值只能是其中一種類別。如果類別名稱帶有空格,仍需要將之放入引號中。
實驗資料集中所有的資料都是實驗所需的,因此不存在屬性篩選的問題。若所採用的資料集中存在大量的與實驗無關的屬性,則需要使用weka平臺的Filter(過濾器)實現屬性的篩選。Filter處可以通過Choose 選擇某個篩選器Filter,以實現篩選資料或者對資料進行某種變換。資料預處理主要就是利用它來實現,如圖7所 示。
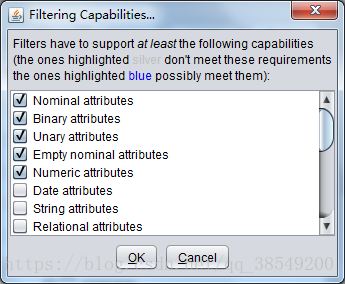
圖7 Filter(過濾器)
3、決策樹演算法
WEKA中的“Classify”選項卡中包含了分類(Classification)和迴歸(Regression),在這兩個任務中,都有一個共同的目標屬性(輸出變數)。可以根據一個樣本(WEKA中稱作例項)的一組特徵(輸入變數),對目標進行預測。為了實現這一目的,我們需要有一個訓練資料集,這個資料集中每個例項的輸入和輸出都是已知的。觀察訓練集中的例項,可以建立起預測的模型。有了這個模型,我們就可以新的輸出未知的例項進行預測了。衡量模型的好壞就在於預測的準確程度。在WEKA中,待預測的目標(輸出)被稱作Class屬性,這應該是來自分類任務的“類”。一般的,若Class屬性是分型別時我們的任務才叫分類,Class屬性是數值型時我們的任務叫回歸。而我們使用決策樹演算法C4.5對Fund-data-normal建立起分類模型。因此我們製作分類不做迴歸。
用“Explorer”開啟訓練集“bank-full.arff”。切換到“Classify”選項卡,點選“Choose”按鈕後可以看到很多分類或者回歸的演算法分門別類的列在一個樹型框裡。樹型框下方有一個“Filter...”按鈕,點選後勾選“Binary attributes”“Numeric attributes”和“Binary class”。點“OK”後回到樹形圖,可以發現一些演算法名稱變灰了,說明它們不能用。選擇“trees”下的“J48”,這就是我們需要的C4.5演算法。
點選“Choose”右邊的文字框,彈出新視窗為該演算法設定各種引數。我們把引數保持預設。
選上“Cross-validation”並在“Folds”框填上“10”。點“Start”按鈕開始讓演算法生成決策樹模型。很快,用文字表示的一棵決策樹以及對這個決策樹的誤差分析結果出現在右邊“Classifier output”中。見圖8、圖9,圖10。
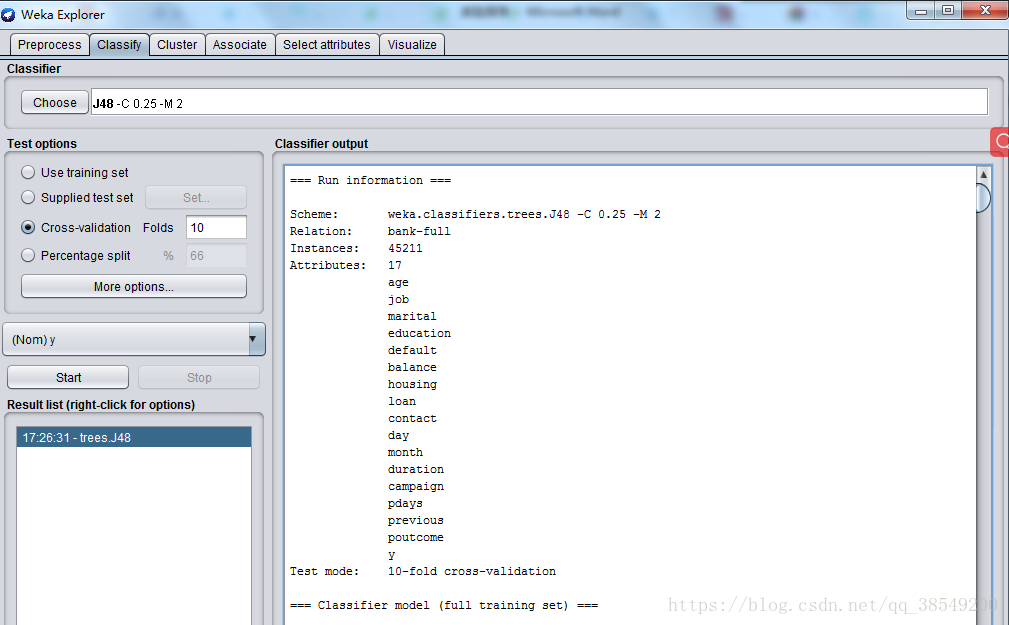
圖8 決策樹演算法結果
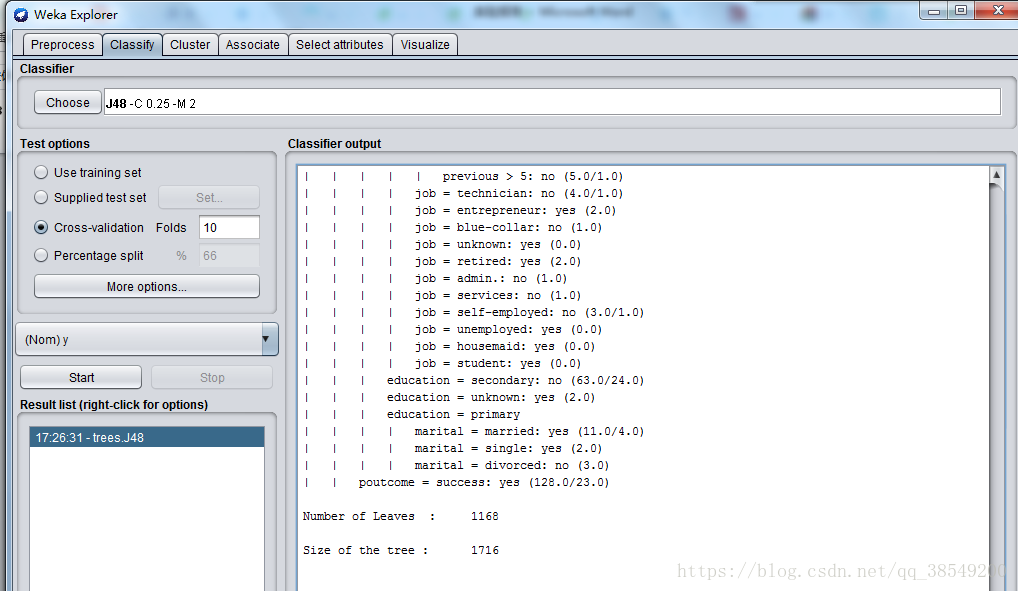
圖9 決策樹演算法結果
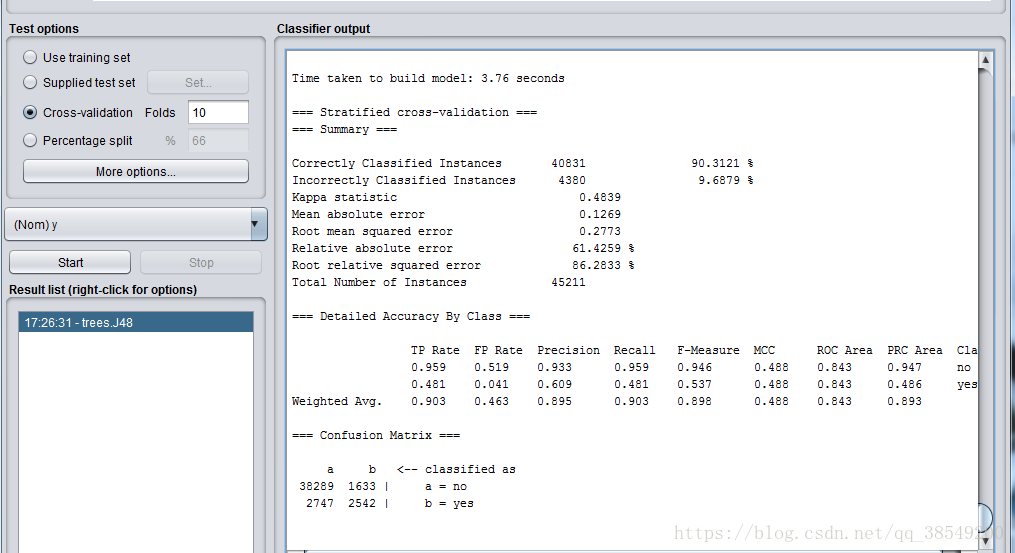
圖10 決策樹演算法結果
分析結果:
該結果的開頭給出了資料集的概要,同時註明所用的評估方法是10折交叉驗證。該方法是預設的。再往下是一棵剪枝過的決策樹,這棵樹是文字形式的。這裡給出的模型通常是從Preprocess面板中的完整資料集上產生。第一層的分裂基於屬性outlook進行
在這個樹結構中,冒號後面的是分配到某葉子節點的類標,類標後面是到達該葉子結點的實力數量,該數量以十進位制數表示。由圖可知,由9.6879%的例項在交叉驗證中被錯誤分類。從結尾處的混淆矩陣中可以看出,有1633屬於no的例項被分為yes,同時有2747屬於yes的例項被分為no類,總例項是45211。P=0.895,R=0.903,ROC面積為0.843
將模型運用在測試集:
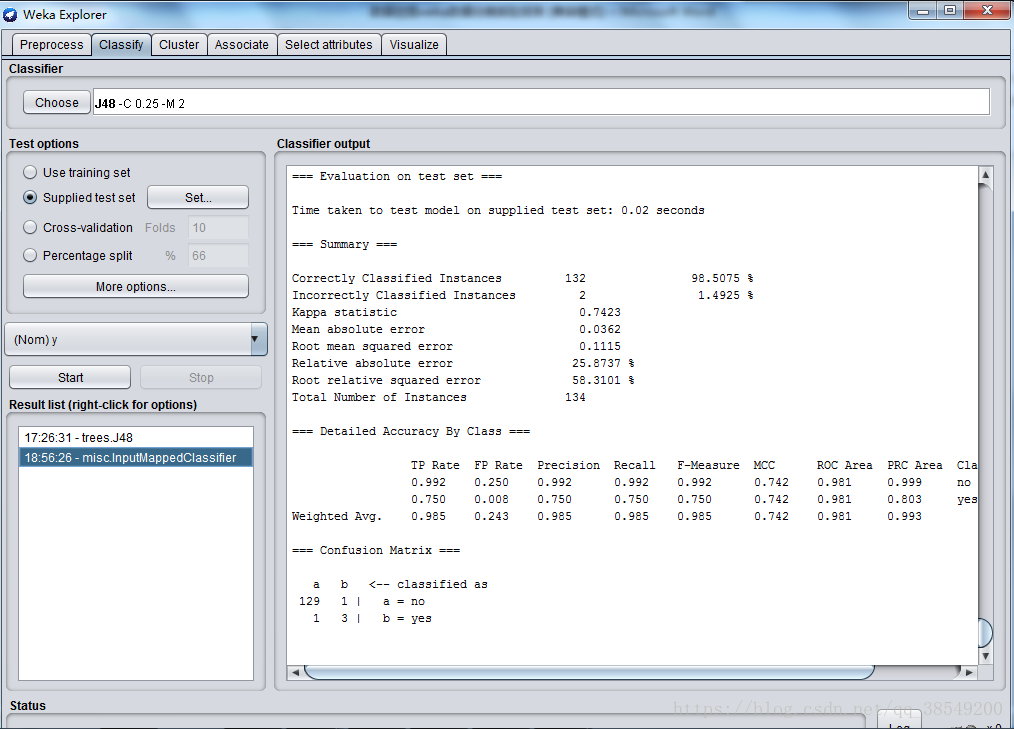
圖11 訓練集結果
結果分析:
準確率為98.5075%,有2個例項被錯誤分類。P=0.985,R=0.985,ROC面積為0.981。
4、樸素貝葉斯分類器
到“Classify”選項卡,點選“Choose”按鈕後可以看到很多分類或者回歸的演算法分門別類的列在一個樹型框裡。選擇“bayes”下的“NaiveBayes”,這就是我們需要的樸素貝葉斯演算法。
選上“Cross-validation”並在“Folds”框填上“10”。點“Start”按鈕開始讓演算法生成貝葉斯分類器,結果如圖12、圖13。
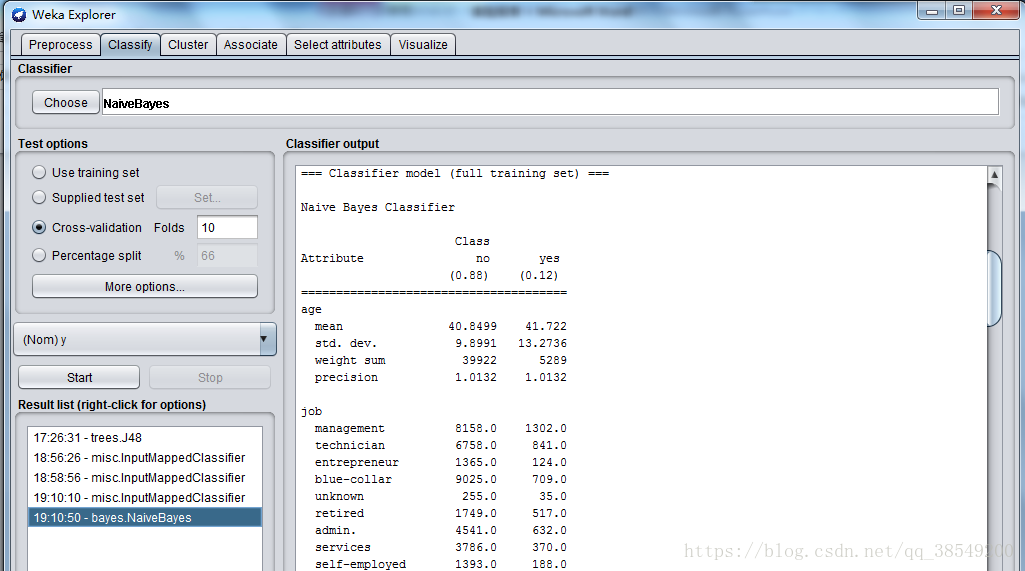
圖12 樸素貝葉斯
圖13 樸素貝葉斯演算法結果
結果分析:如圖所示,這個輸出與決策樹演算法輸出顯著不同就在於它輸出的不是一顆文字形式的樹,這裡關於樸素貝葉斯模型的引數呈現在表中。第一列給出了屬性,其他兩列給出了類標值,表中每項可以死名目值得頻度計數,也可以是數值型屬性正態分佈的引數。使用樸素貝葉斯分類器訓練資料集,正確分類例項比例為88.0073%。根據混淆矩陣,有2924屬於no的例項被分為yes,同時有2498屬於yes的例項被分為no類。P=0.884,R=0.880,ROC面積為0.861
將模型應用於測試集:
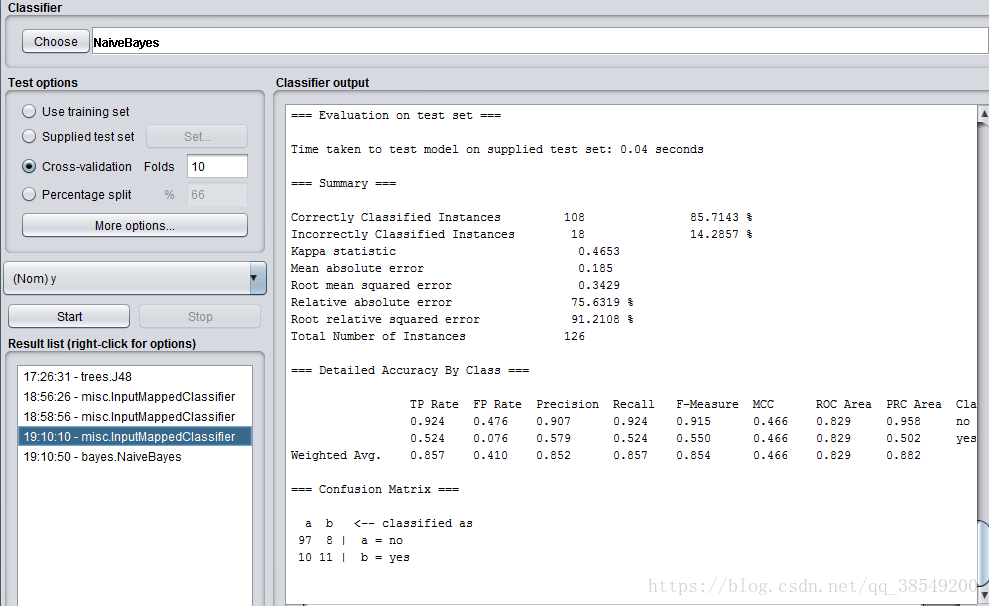
圖14 測試集結果
結果分析:
準確率為85.7143%,有18個例項被錯誤分類。P=0.852,R=0.857,ROC面積為0.829。
5、KNN演算法
到“Classify”選項卡,點選“Choose”按鈕後可以看到很多分類或者回歸的演算法分門別類的列在一個樹型框裡。選擇“lazy”下的“IBk”,這就是我們需要的樸素貝葉斯演算法。
選上“Cross-validation”並在“Folds”框填上“10”。點“Start”按鈕開始讓演算法生成KNN分類器。K值設為10,如圖15。
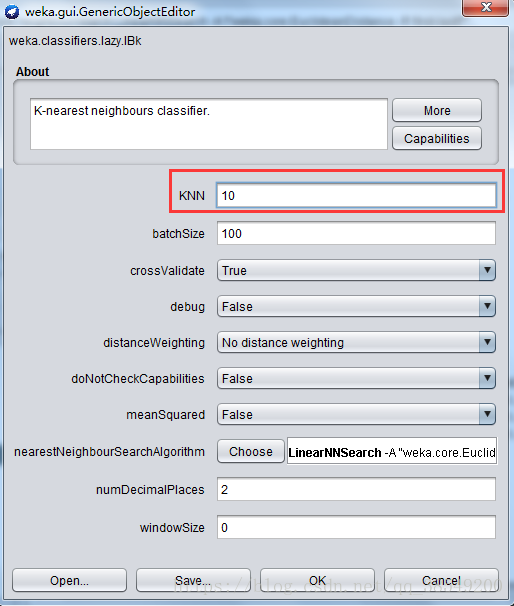
圖15 K值設定位置
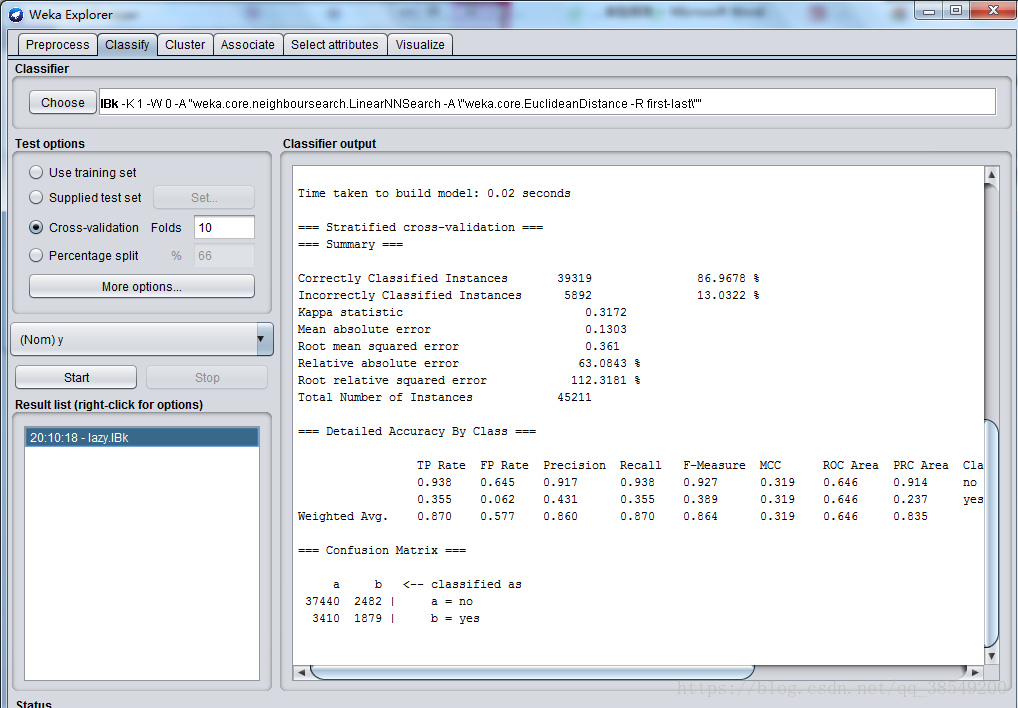
圖16 KNN結果
使用KNN分類器訓練資料集,正確分類例項比例為86.9678%。根據混淆矩陣,有2482屬於no的例項被分為yes,同時有3410屬於yes的例項被分為no類。P=0.860,R=0.870,ROC面積為0.646。
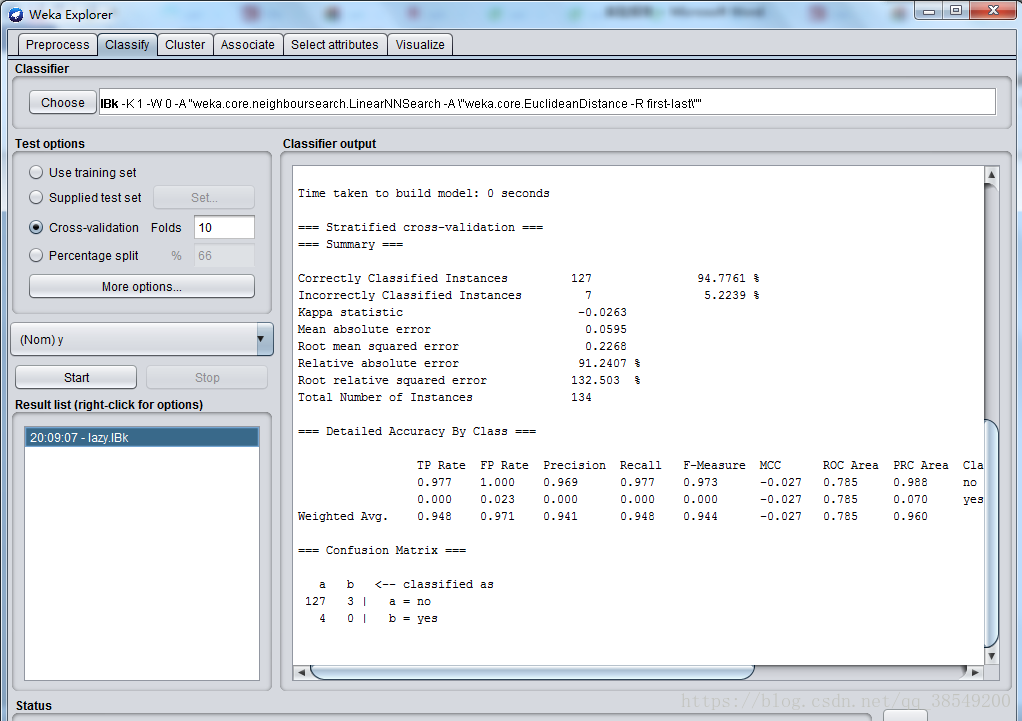
圖17 KNN測試集上結果
結果分析:
準確率為94.7761%,有7個例項被錯誤分類。P=0.941,R=0.948,ROC面積為0.785。
三、聚類演算法
weka提供採用k-means演算法聚類的SimpleKMeans,簇的數目由引數指定,使用者可以選擇使用歐式距離或曼哈頓距離作為距離度量。這裡使用weka data自帶的iris資料建立起聚類模型。iris裡包括四個屬性變數(比如花的長度和寬度)和一個分類變數class(分成了3種,每種50個數據,一共150條資料),我們這裡不需要分類結果,於是我們要在實驗開始的時候將class給remove掉,自定義新的分類種數。
用“Explorer”開啟軟體自帶的“iris.arff”,並切換到“Cluster”。點“Choose”按鈕選擇“SimpleKMeans”,這是WEKA中實現K均值的演算法。點選旁邊的文字框,修改“numClusters”為5,說明我們希望把這150條例項聚成5類,即K=5。下面的“seed”引數是要設定一個隨機種子,依此產生一個隨機數,用來得到K均值演算法中第一次給出的K個簇中心的位置。我們不妨暫時讓它就為10。
選中“Cluster Mode”的“Use training set”,點選“Start”按鈕,觀察右邊“Clusterer output”給出的聚類結果。見下圖18:
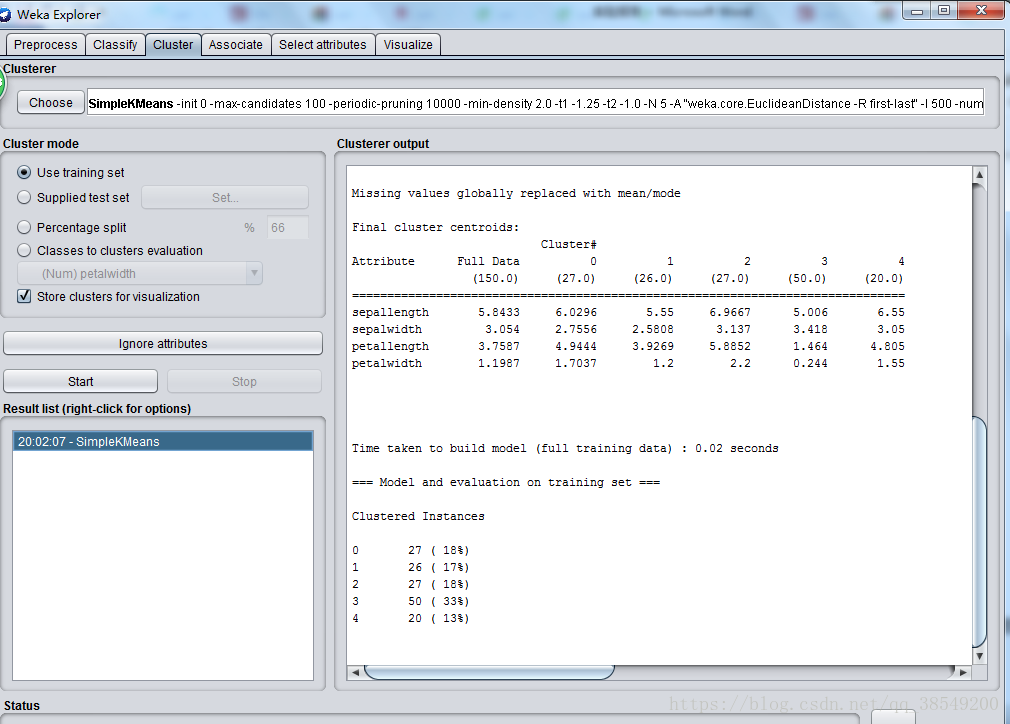
圖18 聚類演算法結果
分析結果:within cluster sum of squared errors:是評價聚類好壞的標準,數值越小說明同一簇例項之間的距離越小,此時的值為5.13.seed引數設定不同會導致該數值不同(因為初始點的選擇對kmeans方法十分重要)cluster controids:其後列出了各個簇中心(最終趨向收斂不再迭代)的位置。對於數值型的屬性,簇中心就是它的均值。clustered instances:是各個簇中例項的數目及百分比。
四、關聯規則
使用weka安裝目錄data資料夾下的breast-cancer.arff資料資料作關聯規則的分析。用“Explorer”開啟“breast-cancer.arff”後,切換到“Associate”選項卡。預設關聯規則分析是用Apriori演算法,我們就用這個演算法,但是點“Choose”右邊的文字框修改預設的引數。
從網上獲得的Apriori有關知識:對於一條關聯規則L->R,我們常用支援度(Support)和置信度(Confidence)來衡量它的重要性。規則的支援度是用來估計在一個購物籃中同時觀察到L和R的概率P(L,R),而規則的置信度是估計購物欄中出現了L時也出會現R的條件概率P(R|L)。關聯規則的目標一般是產生支援度和置信度都較高的規則。
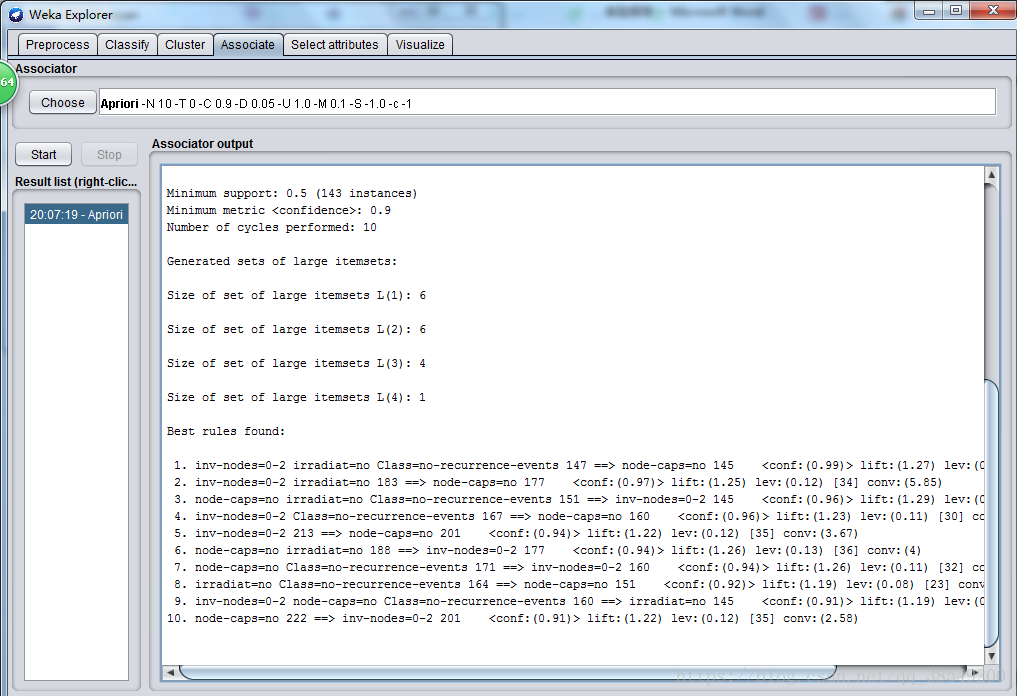
圖19 Apriori演算法結果
結果分析:規則採用“條件 num1=>結論 num2”的形式表示,num1表示滿足條件的例項個數,num2表示滿足整個規則(包括後面的結果,如X=>Y中的Y)的例項個數,num2/num1=conf,即該規則的置信度。距離,第一行的inv-nodes=0-2, irradiat都是X中的某項條件,這表示x1,x2,...,xn=>yi這條關聯規則。因為在上面apriori中的引數選擇裡numRules預設寫的是10,所以從上往下列出了10條挖掘出的最佳關聯規則。可以改,比如改成12,(在滿足置信條件的情況下)就會列出12條。
五、小結
通過本次資料探勘實驗,重新學習了一下資料探勘的相關概念和知識,理解了資料探勘的用途和使用步驟;進一步學習了WEKA開源資料探勘工具在資料探勘學習中的使用方法。並且對WEKA的分類與迴歸、聚類分析、關聯規則幾個模組化的基本分析方式進行了操作實驗。在此過程中學會了運用各個模組的分析方法。由於是初次實驗WEKA分析軟體,對WEKA的運用和最終的資料結果運用還不熟悉,還需要在以後的學習中加以著重研究。