
bullets mysql資料庫面試總結
資料庫優化
建表優化
1)資料庫正規化
l 第一正規化(1NF):強調的是列的原子性,即列不能夠再分成其他幾列。
如電話列可進行拆分---家庭電話、公司電話
l 第二正規化(2NF):首先是 1NF,另外包含兩部分內容,一是表必須有主鍵;二是沒有包含在主鍵中的列必須完全依賴於主鍵,而不能只依賴於主鍵的一部分。
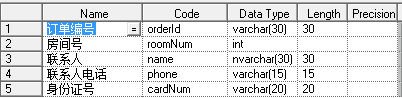

l 第三正規化(3NF):首先是 2NF,另外非主鍵列必須直接依賴於主鍵,不能存在傳遞依賴。
比如Student表(學號,姓名,年齡,性別,所在院校,院校地址,院校電話)
這樣一個表結構,就存在上述關係。 學號--> 所在院校 --> (院校地址,院校電話)
這樣的表結構,我們應該拆開來,如下。
(學號,姓名,年齡,性別,所在院校)--(所在院校,院校地址,院校電話)
滿足這些規範的資料庫是簡潔的、結構明晰的;同時,不會發生插入(insert)、刪除(delete)和更新(update)操作異常。
2)資料型別選擇
l 數字型別
Float和double選擇(儘量選擇float)
區分開TINYINT / INT / BIGINT,能確定不會使用負數的欄位,建議新增 unsigned定義
能夠用數字型別的欄位儘量選擇數字型別而不用字串型別的
l 字元型別
char,varchar,TEXT的選擇:非萬不得已不要使用 TEXT 資料型別,定長欄位,建議使用 CHAR 型別(填空格),不定長欄位儘量使用 VARCHAR(自動適應長度,超過階段),且僅僅設定適當的最大長度
l 時間型別
按選擇優先順序排序DATE(精確到天)、TIMESTAMP、DATETIME(精確到時間)
l ENUM
對於狀態欄位,可以嘗試使用 ENUM 來存放
l 避免使用NULL欄位,很難查詢優化且佔用額外索引空間
3)字元編碼
同樣的內容使用不同字符集表示所佔用的空間大小會有較大的差異,所以通過使用合適的字符集,可以幫助我們儘可能減少資料量,進而減少IO操作次數。
1.純拉丁字元能表示的內容,選擇 latin1 字元編碼
2.中文可選用utf-8
3.MySQL的資料型別可以精確到欄位,所以當我們需要大型資料庫中存放多位元組資料的時候,可以通過對不同表不同欄位使用不同的資料型別來較大程度減小資料儲存量,進而降低 IO 操作次數並提高快取命中率
Sql優化
1) 只返回需要的資料
a) 不要寫SELECT *的語句
b) 合理寫WHERE子句,不要寫沒有WHERE的SQL語句。
2) 儘量少做重複的工作
可以合併一些sql語句
3) 適當建立索引(不是越多越好)但以下幾點會進行全表掃描
a) 左模糊查詢’%...’
b) 使用了不等操作符!=
c) Or使用不當,or兩邊都必須有索引才行
d) In 、not in
e) Where子句對欄位進行表示式操作
f) 對於建立的複合索引(從最左邊開始組合),查詢條件用到的列必須從左邊開始不能間隔。否則無效,複合索引的結構與電話簿類似
g) 全文索引:當於對檔案建立了一個以詞庫為目錄的索引(檔案大全文索引比模糊匹配效果好)
能在char、varchar、text型別的列上面建立全文索引
MySQL 5.6 Innodb引擎也能進行全文索引
搜尋語法:MATCH (列名1, 列名2,…) AGAINST (搜尋字串 [搜尋修飾符])
如果列型別是字串,但在查詢時把一個數值型常量賦值給了一個字元型的列名name,那麼雖然在name列上有索引,但是也沒有用到。
4) 使用join代替子查詢
5) 使用union代替手動建立臨時表
索引優化
一、 建立索引,以下情況不適合建立索引
l 表記錄太少
l 經常插入、刪除、修改的表
l 資料重複且分佈平均的表字段
二、 複合索引
如果一個表中的資料在查詢時有多個欄位總是同時出現則這些欄位就可以作為複合索引
索引
索引是對資料庫表中一列或多列的值進行排序的一種結構。
優點:
l 大大加快資料的檢索速度
l 建立唯一性索引,保證資料庫表中每一行資料的唯一性
l 可以加速表和表之間的連線
缺點:
l 索引需要佔物理空間。
l 當對錶中的資料進行增加、刪除和修改的時候,索引也要動態的維護,
降低了資料的維護速度。
索引分類:
l 普通索引
create index zjj_temp_index_1 on zjj_temp_1(first_name);
drop index zjj_temp_index_1;
l 唯一索引,索引列的值必須唯一,但允許有空值
create unique index zjj_temp_1 on zjj_temp_1(id);
l 主鍵索引,它是一種特殊的唯一索引,不允許有空值。
l 組合索引
事務
資料庫事務(Database Transaction) ,是指作為單個邏輯工作單元執行的一系列操作,要麼完全地執行,要麼完全地不執行。
四大特徵:
(1)原子性
事務必須是原子工作單元;對於其資料修改,要麼全都執行,要麼全都不執行。
(2)一致性
事務的一致性指的是在一個事務執行之前和執行之後資料庫都必須處於一致性狀態。事務執行的結果必須是使資料庫從一個一致性狀態變到另一個一致性狀態。
(3) 隔離性(關於事務的隔離性資料庫提供了多種隔離級別)
一個事務的執行不能干擾其它事務。即一個事務內部的操作及使用的資料對其它併發事務是隔離的,併發執行的各個事務之間不能互相干擾。
(4)永續性
事務完成之後,它對於資料庫中的資料改變是永久性的。該修改即使出現系統故障也將一
直保持。
在介紹資料庫提供的各種隔離級別之前,我們先看看如果不考慮事務的隔離性,會發生的幾種問題:
l 髒讀
髒讀是指在一個事務處理過程裡讀取了另一個未提交的事務中的資料。
l 不可重複讀
l 幻讀
幻讀和不可重複讀都是讀取了另一條已經提交的事務,不可重複讀重點在於update和delete,而幻讀的重點在於insert。
在可重複讀中,該sql第一次讀取到資料後,就將這些資料加鎖,其它事務無法修改這些資料,就可以實現可重複 讀了。但這種方法卻無法鎖住insert的資料,所以當事務A先前讀取了資料,或者修改了全部資料,事務B還是可以insert資料提交,這時事務A就會 發現莫名其妙多了一條之前沒有的資料,這就是幻讀,不能通過行鎖來避免。需要Serializable隔離級別 ,讀用讀鎖,寫用寫鎖,讀鎖和寫鎖互斥,這麼做可以有效的避免幻讀、不可重複讀、髒讀等問題,但會極大的降低資料庫的併發能力。
現在來看看MySQL資料庫為我們提供的四種隔離級別:
① Serializable (序列化):可避免髒讀、不可重複讀、幻讀的發生。
② Repeatable read (可重複讀):可避免髒讀、不可重複讀的發生。
③ Read committed (讀已提交):可避免髒讀的發生。
④ Read uncommitted (讀未提交):最低級別,任何情況都無法保證。
在MySQL資料庫中預設的隔離級別為Repeatable read (可重複讀)。
鎖模式包括:
l 共享鎖:(讀取)操作建立的鎖。其他使用者可以併發讀取資料,但任何事物都不能獲取資料上的排它鎖,直到已釋放所有共享鎖。
l 排他鎖(X鎖):對資料A加上排他鎖後,則其他事務不能再對A加任任何型別的封鎖。獲准排他鎖的事務既能讀資料,又能修改資料。
l 更新鎖: 更新 (U) 鎖可以防止通常形式的死鎖。如果兩個事務獲得了資源上的共享模式鎖,然後試圖同時更新資料,則兩個事務需都要轉換共享鎖為排它 (X) 鎖,並且每個事務都等待另一個事務釋放共享模式鎖,因此發生死鎖。 若要避免這種潛 在的死鎖問題,請使用更新 (U) 鎖。一次只有一個事務可以獲得資源的更新 (U) 鎖。如果事務修改資源,則更新 (U) 鎖轉換為排它 (X) 鎖。否則,鎖轉換為共享鎖。
鎖的粒度主要有以下幾種型別:
l 行鎖: 粒度最小,併發性最高
l 頁鎖:一次鎖定一頁。25個行鎖可升級為一個頁鎖。
l 表鎖:粒度大,併發性低
l 資料庫鎖:控制整個資料庫操作
樂觀鎖:相對悲觀鎖而言,樂觀鎖假設認為資料一般情況下不會造成衝突,所以在資料進行提交更新的時候,才會正式對資料的衝突與否進行檢測,如果發現衝突了,則讓返回使用者錯誤的資訊,讓使用者決定如何去做。一般的實現樂觀鎖的方式就是記錄資料版本。
悲觀鎖:顧名思義,就是很悲觀,每次去拿資料的時候都認為別人會修改,所以每次在拿資料的時候都會上鎖,這樣別人想拿這個資料就會block直到它拿到鎖。傳統的關係型資料庫裡邊就用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖。
索引
MyISAM、InnoDB區別
l MyISAM型別不支援事務處理等高階處理,而InnoDB型別支援。
l MyISAM表不支援外來鍵,InnoDB支援
l MyISAM鎖的粒度是表級,而InnoDB支援行級鎖定。
l MyISAM支援全文型別索引,而InnoDB不支援全文索引。(mysql 5.6後innodb支援全文索引)
MyISAM相對簡單,所以在效率上要優於InnoDB,小型應用可以考慮使用MyISAM。當你的資料庫有大量的寫入、更新操作而查詢比較少或者資料完整性要求比較高的時
候就選擇innodb表。當你的資料庫主要以查詢為主,相比較而言更新和寫 入比較少,並且業務方面資料完整性要求不那麼嚴格,就選擇mysiam表。
MyISAM和InnoDB索引實現:
MyISAM索引實現
MyISAM索引檔案和資料檔案是分離的,索引檔案僅儲存資料記錄的地址。
l 主索引
MyISAM引擎使用B+Tree作為索引結構,葉節點的data域存放的是資料記錄的地址。

l 輔助索引
在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重複。
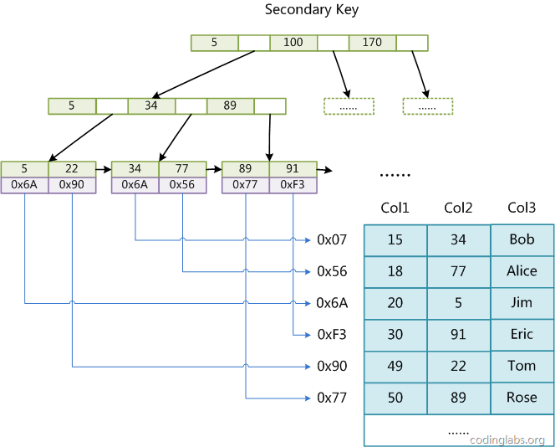
MyISAM中索引檢索的演算法為首先按照B+Tree搜尋演算法搜尋索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址,讀取相應資料記錄。
MyISAM的索引方式也叫做“非聚集”的,之所以這麼稱呼是為了與InnoDB的聚集索引區分。
InnoDB索引實現
然InnoDB也使用B+Tree作為索引結構,但具體實現方式卻與MyISAM截然不同.
l 主索引
InnoDB表資料檔案本身就是主索引。
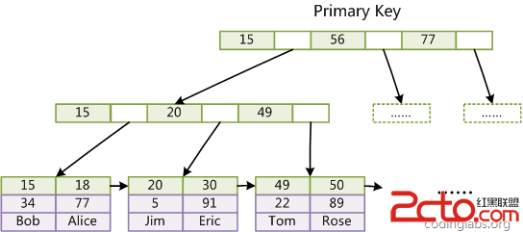
InnoDB主索引(同時也是資料檔案)的示意圖,可以看到葉節點包含了完整的資料記錄。這種索引叫做聚集索引。因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵,這個欄位長度為6個位元組,型別為長整形。
l 輔助索引
InnoDB的所有輔助索引都引用主鍵作為data域。
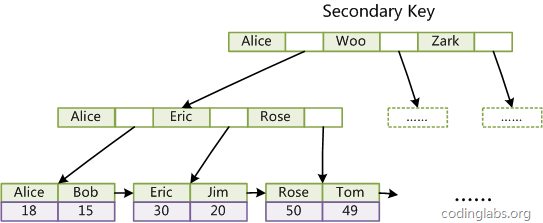
聚集索引這種實現方式使得按主鍵的搜尋十分高效,但是輔助索引搜尋需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
不同儲存引擎的索引實現方式對於正確使用和優化索引都非常有幫助,例如知道了InnoDB的索引實現後,就很容易明白
1、為什麼不建議使用過長的欄位作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。再例如,
2、用非單調的欄位作為主鍵在InnoDB中不是個好主意,因為InnoDB資料檔案本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時資料檔案為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增欄位作為主鍵則是一個很好的選擇。
InnoDB索引和MyISAM索引的區別:
l 一是主索引的區別,InnoDB的資料檔案本身就是索引檔案。而MyISAM的索引和資料是分開的。
l 二是輔助索引的區別:InnoDB的輔助索引data域儲存相應記錄主鍵的值而不是地址。而MyISAM的輔助索引和主索引沒有多大區別。
紅黑樹 B樹 B+樹 B-樹
二叉查詢樹(BST):
二叉排序樹或者是一棵空樹,或者是具有下列性質的二叉樹:
l 若左子樹不空,則左子樹上所有結點的值均小於它的根結點的值。
l 若右子樹不空,則右子樹上所有結點的值均大於它的根結點的值。
l 左、右子樹也分別為二叉排序樹。
l 沒有鍵值相等的節點(因此,插入的時候一定是葉子節點)。
刪除演算法
l 要刪除節點是葉子節點。
l 要刪除的節點只有一個孩子(左孩子或右孩子),這種情況比較簡單,只需要將該孩子連線到當前節點的父節點即可。
l 要刪除的節點有兩個孩子,這個時候的演算法就比較複雜(相比較於只有一個孩子的情況)。首先我們需要找到待刪除節點的左子樹上的最大值節點,或者右子樹上的最小值節點,然後將該節點的引數值與待刪除的節點引數值進行交換,最後刪除該節點,這樣需要刪除的引數就從該二叉樹中刪除了。
紅黑樹:
紅黑樹(Red Black Tree) 是一種自平衡二叉查詢樹 :
l 每個節點或者是黑色,或者是紅色。
l 根節點是黑色。
l 每個葉子節點是黑色。
l 如果一個節點是紅色的,則它的子節點必須是黑色的。
l 從一個節點到該節點的子孫節點的所有路徑上包含相同數目的黑節點。
紅黑樹的各種操作的時間複雜度是O(log2N)。
紅黑樹 vs AVL
紅黑樹的查詢效能略微遜色於AVL樹,因為他比avl樹會稍微不平衡最多一層,也就是說紅黑樹的查詢效能只比相同內容的avl樹最多多一次比較,但是,紅黑樹在插入和刪除上完爆avl樹,avl樹每次插入刪除會進行大量的平衡度計算,而紅黑樹為了維持紅黑性質所做的紅黑變換和旋轉的開銷,相較於avl樹為了維持平衡的開銷要小得多
插入操作

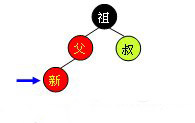
紅父 如果新節點的父結點為紅色,這時就需要進行一系列操作以保證整棵樹紅黑性質。如下圖所示,由於父結點為紅色,此時可以判定,祖父結點必定為黑色。這時需要根據叔父結點的顏色來決定做什麼樣的操作。青色結點表示顏色未知。由於有可能需要根結點到新點的路徑上進行多次旋轉操作,而每次進行不平衡判斷的起始點(我們可將其視為新點)都不一樣。所以我們在此使用一個藍色箭頭指向這個起始點,並稱之為判定點。
l 紅叔 當叔父結點為紅色時,如下圖所示,無需進行旋轉操作,只要將父和叔結點變為黑色,將祖父結點變為紅色即可。但由於祖父結點的父結點有可能為紅色,從而違反紅黑樹性質。此時必須將祖父結點作為新的判定點繼續向上(迭代)進行平衡操作。
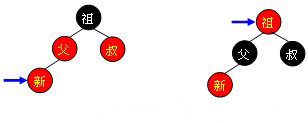
需要注意的是,無論“父節點”在“叔節點”的左邊還是右邊,無論“新節點”是“父節點”的左孩子還是右孩子,它們的操作都是完全一樣的(其實這種情況包括4種,只需調整顏色,不需要旋轉樹形)。
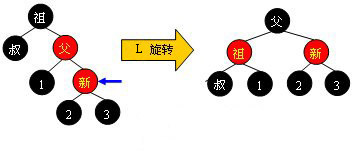
l 黑叔 當叔父結點為黑色時,需要進行旋轉,以下圖示了所有的旋轉可能: Case 1:

Case 2:
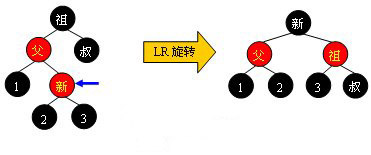
Case 3:
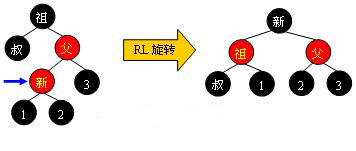
Case 4:
B樹與B-樹:
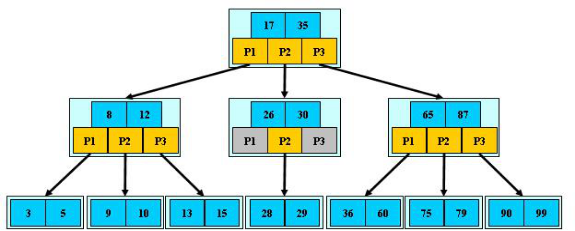
B-tree樹即B樹,B即Balanced,平衡的意思。因為B樹的原英文名稱為B-tree,而國內很多人喜歡把B-tree譯作B-樹,其實,這是個非常不好的直譯,很容易讓人產生誤解。如人們可能會以為B-樹是一種樹,而B樹又是另一種樹。而事實上是,B-tree就是指的B樹。
m階B樹是一棵平衡的m路搜尋樹。它是空樹,或者是滿足下列性質的樹:
l 根結點的兒子數為[2, M];
l 除根結點以外的非葉子結點的兒子數為[M/2, M]; (M/2向上取整)
l 每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;
l 非葉子結點的關鍵字個數=指向兒子的指標個數-1;
l 非葉子結點的關鍵字:K[1], K[2], …, K[X-1];且K[i] < K[i+1];
l 非葉子結點的指標:P[1], P[2], …, P[X];其中P[1]指向關鍵字小於K[1]的
子樹,P[X]指向關鍵字大於K[X-1]的子樹,其它P[i]指向關鍵字屬於(K[i-1], K[i])的子樹;
l 所有葉子結點位於同一層;
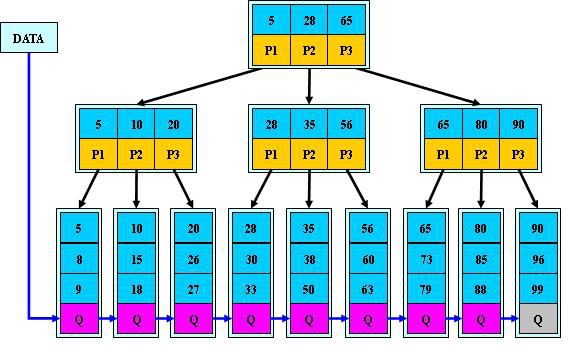
B+樹:
B+樹是B-樹的變體,也是一種多路搜尋樹:
其定義基本與B-樹同,除了:
l 非葉子結點的子樹指標與關鍵字個數相同;
l 非葉子結點的子樹指標P[i],指向關鍵字值屬於[K[i], K[i+1])的子樹
(B-樹是開區間);
l 為所有葉子結點增加一個指標鏈;
l 所有關鍵字都在葉子結點出現;
基本SQL操作
l SELECT * FROM table ORDER BY field DESC; (ASC|DESC)
SELECT DISTINCT field from table where 範圍
l INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
l UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
l DELETE FROM table_name WHERE some_column=some_value;
LIKE 操作符
SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern;
IN 操作符
SELECT column_name(s) FROM table_name WHERE column_name
IN (value1,value2,...);
BETWEEN 操作符
SELECT column_name(s) FROM table_name WHERE column_name BETWEEN
JOIN
左連線,右連線,內連線
left join(左聯接): 返回包括左表中的所有記錄和右表中聯結欄位相等的記錄。
right join(右聯接): 返回包括右表中的所有記錄和左表中聯結欄位相等的記錄。
inner join(等值連線): 只返回兩個表中聯結欄位相等的行。(預設)
UNION 操作符
UNION 操作符用於合併兩個或多個 SELECT 語句的結果集。
SELECT country, name FROM Websites WHERE country='CN' UNION SELECT country, app_name FROM apps WHERE country='CN' ORDER BY country;
建立檢視
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition
SQL函式
Avg() Count() Max() Min() Sum()
Group By():
GROUP BY 語句用於結合聚合函式,根據一個或多個列對結果集進行分組。
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name;
HAVING 子句可以讓我們篩選分組後的各組資料。
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
如何查詢資料庫表結構,主鍵
desc tabl_name;
建表
CREATE TABLE 表名稱
(
列名稱1 資料型別,
....
)